

CART算法及案例分析
CART算法的R语言实现
#步骤1 数据预处理,建立训练集和预测集
loc <- "http://archive.ics.uci.edu/ml/machine-learning-databases/" ds <- "breast-cancer-wisconsin/breast-cancer-wisconsin.data" url <- paste(loc, ds, sep="") data <- read.table(url, sep=",", header=FALSE, na.strings="?") #na.strings="?" : 数集中缺失的类型用“?”来表示。 head(data) #未命名

names(data) <- c("ID", "clumpThickness", "sizeUniformity", #给数据集属性贴标签
"shapeUniformity", "maginalAdhesion",
"singleEpithelialCellSize", "bareNuclei",
"blandChromatin", "normalNucleoli", "mitosis", "class")
head(data) #命名之后

data$class[data$class==2]<- "良性" #数据预处理,设置class=2的显示"良性" data$class[data$class==4]<- "恶性" #数据预处理,设置class=4的显示"恶性" data<-data[-1] #删除第一列(这列是编号,分析过程不考虑) str(data)

set.seed(1234) train<-sample(nrow(data),0.7*nrow(data)) tdata<-data[train,] dim(tdata)

vdata<-data[-train,] dim(vdata)

#步骤2 用rpart函数构建树
library(rpart) dtree<-rpart(class~.,data=tdata,method="class",parms=list(split="gini")) printcp(dtree)

#步骤3 prune剪枝,提高模型的泛化能力
dtree$cptable #剪枝的复杂度

tree<-prune(dtree,cp=0.0125) tree$cptable #剪枝后的复杂度及分枝数

#步骤4 模型可视化
opar<-par(no.readonly = T) #par(mfrow=c(1,2)) #画面分页 library(rpart.plot) rpart.plot(dtree,branch=1,type=2,fallen.leaves=T,cex=0.8,sub="剪枝前")

rpart.plot(dtree,branch=1,type=4,fallen.leaves=T,cex=0.8,sub="剪枝后")
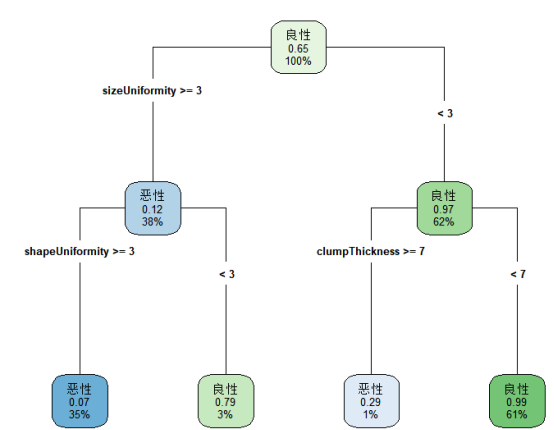
#步骤5 利用预测集检验模型效果
predtree<-predict(tree,newdata=vdata,type="class") #利用预测集进行预测
table(vdata$class,predtree,dnn=c("真实值","预测值")) #输出混淆矩阵

CART经典算法案例分析
library(rpart)
data(car.test.frame) #加载数据
head(car.test.frame) #查看数据
car.test.frame$Mileage=100*4.596/(1.6*car.test.frame$Mileage) #将Mileage(英里数)的取值换算为“油耗”指标
names(car.test.frame)<-c("价格","产地","可靠性","油耗","类型","车重","发动机功率","净马力")
head(car.test.frame)
str(car.test.frame)

Data_Mileage<-matrix(0,60,1) #设矩阵Data_Mileage用来存放新变量 Data_Mileage[which(car.test.frame$"油耗">=11.6)]="A" #将“油耗”在11.6~15.8区间的样本Data_Mileage值设置为A Data_Mileage[which(car.test.frame$"油耗"<=9)]="C" #将“油耗”在7.7~9区间的样本Data_Mileage值设置为C Data_Mileage[which(Data_Mileage==0)]="B" #将“油耗”不在A、C区间的样本Data_Mileage值设置为B car.test.frame$"分组油耗"=Data_Mileage #在car.test.frame数据集中添加信变量“分组油耗”,取值为Data_Mileage car.test.frame[1:10,c(4,9)] #查看预处理后car.test.frame数据集中“”油耗及“分组油耗”变量的前10行数据

a<-round(1/4*sum(car.test.frame$"分组油耗"=="A")) #计算A组中的测试集样本,记为a b<-round(1/4*sum(car.test.frame$"分组油耗"=="B")) #计算B组中的测试集样本,记为b c<-round(1/4*sum(car.test.frame$"分组油耗"=="C")) #计算C组中的测试集样本,记为c sub<-strata(car.test.frame,stratanames="分组油耗",size=c(c,b,a),method="srswor") #car.test.frame中的“分组油耗”变量进行分层抽样 Car_train<-car.test.frame[-sub$ID_unit,] #生成训练集Car_train Car_test<-car.test.frame[sub$ID_unit,] #生成测试集Car_test formula_Car_Reg<-油耗~价格+产地+可靠性+类型+车重+发动机功率+净马力 Car_Reg<-rpart(formula_Car_Reg,Car_train,method="anova") #用除“分组油耗”以外的所有变量来对“油耗”建立决策树,且选择树的类型为回归树,即method="anova" Car_Reg

printcp(Car_Reg)
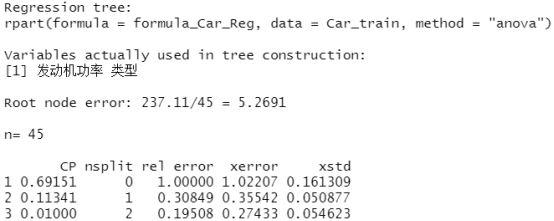
summary(Car_Reg)



Car_Reg2<-rpart(formula_Car_Reg,Car_train,method="anova",cp=0.5) Car_Reg2

Car_Reg3<-prune.rpart(Car_Reg,cp=0.5) #对决策树Car_Reg按照CP值为0.5进行剪枝,新的回归树记为Car_Reg3 Car_Reg3 #回归树展示

#可通过深度参数maxdepth对所生成树进行控制
Car_Reg4<-rpart(formula_Car_Reg,Car_train,method="anova",maxdepth=1) #树的深度maxdepth设为1,新的回归树记为Car_Reg4 Car_Reg4 #导出回归树Car_Reg4的基本信息

printcp(Car_Reg4) #导出回归树Car_Reg4的CP值

Car_plot<-rpart(formula_Car_Reg,Car_train,method="anova",minsplit=10) #用树状图进行观察,选择参数minsplit为10来绘制决策树图形 Car_plot

library(rpart.plot) rpart.plot(Car_plot) #绘制决策树

rpart.plot(Car_plot,type=4)
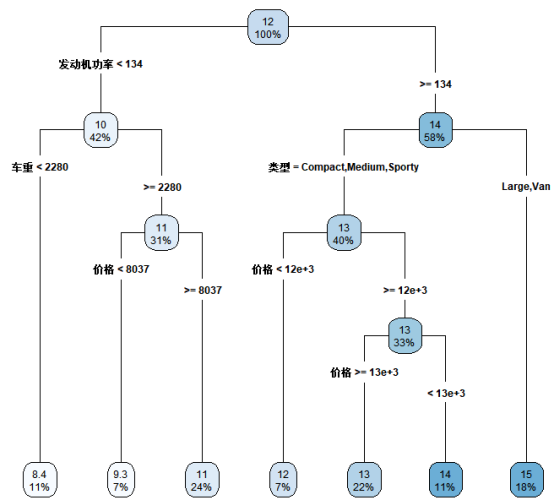
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15990067.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号