
readr包进行数据导入(解析向量、解析文件、写入文件)
使用readr进行数据导入
readr 也是 tidyverse 的核心 R包之一。
library(tidyverse)
1.2 入门
readr 的多数函数用于将平面文件转换为数据框。
read_csv() 读取逗号分隔文件、read_csv2() 读取分号分隔文件(这在用 , 表示小数位的国家非常普遍)、read_tsv() 读取制表符分隔文件、read_delim() 可以读取使用任意分隔符的文件。
read_csv("a,b,c
1,2,3
4,5,6")
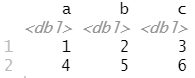
read_csv() 函数都使用数据的第一行作为列名称,这是一种常见做法。
有时文件开头会有好几行元数据。你可以使用 skip = n 来跳过前 n 行;或者使用
comment = "#" 来丢弃所有以 # 开头的行:
read_csv("The first line of metadata
The second line of metadata
x,y,z
1,2,3", skip = 2)

read_csv("# A comment I want to skip
x,y,z
1,2,3", comment = "#")
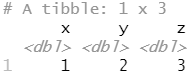
数据没有列名称。可以使用 col_names = FALSE 来通知 read_csv() 不要将第一行作为列标题,而是将各列依次标注为 X1 至 Xn:
read_csv("1,2,3\n4,5,6", col_names = FALSE)
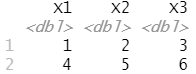
可以向 col_names 传递一个字符向量,以用作列名称:
read_csv("1,2,3\n4,5,6", col_names = c("x", "y", "z"))
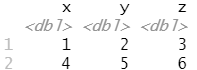
na 它设定使用哪个值(或哪些值)来表示文件中的缺失值:
read_csv("a,b,c\n1,2,.", na = ".")
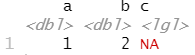
1.2.1 与R基础包进行比较
readr 中的函数,一般来说,它们比基础模块中的函数速度更快(约快 10 倍)。
1.3 解析向量
parse_*() 函数族。这些函数接受一个字符向量,并返回一个特定向量,如逻辑、整数或日期向量:
str(parse_logical(c("TRUE", "FALSE", "NA")))

str(parse_integer(c("1", "2", "3")))
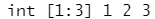
str(parse_date(c("2010-01-01", "1979-10-14")))
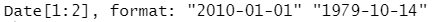
na 参数设定了哪些字符串应该当作缺失值来处理:
parse_integer(c("1", "231", ".", "456"), na = ".")
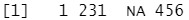
该使用 problems() 函数来获取完整的失败信息集合。这个函数会返回一个 tibble。
problems(x)
1.3.1 数值类型
readr 使用了“地区”这一概念,这是可以按照不同地区设置解析选项的一个对象。通过创建一个
新的地区对象并设定 decimal_mark 参数,可以覆盖 . 的默认值:
parse_double("1.23")
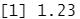
parse_double("1,23", locale = locale(decimal_mark = ","))
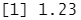
parse_number() 解决了第二个问题:它可以忽略数值前后的非数值型字符。这个函数特别
适合处理货币和百分比,也可以提取嵌在文本中的数值:
parse_number("$100")
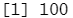
parse_number("20%")
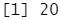
parse_number("It cost $123.45")
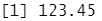
1.3.2 字符串类型
在 R 中,我们可以使用 charToRaw() 函数获得一个字符串的底层表示:
charToRaw("Hadley")
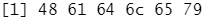
每个十六进制数表示信息的一个字节:48 是 H、61 是 a 等。
readr 全面支持 UTF-8:当读取数据时,它假设数据是 UTF-8 编码的,并总是使用 UTF-8
编码写入数据。
x1 <- "El Ni\xf1o was particularly bad this year" x2 <- "\x82\xb1\x82\xf1\x82\xc9\x82\xbf\x82\xcd"
在 parse_character() 函数中设定编码方式:
parse_character(x1, locale = locale(encoding = "Latin1"))
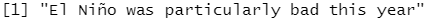
parse_character(x2, locale = locale(encoding = "Shift-JIS"))
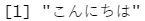
readr 提供了 guess_encoding() 函数来帮助你找出编码方式。
guess_encoding(charToRaw(x1))
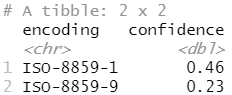
guess_encoding(charToRaw(x2))

1.3.3 因子类型
名义型变量,有序型变量,连续型变量
因子,在R中名义型变量和有序型变量成为因子,factor,这些分类变量的可能值称为一个水平,level,例如good,better,best,都称为一个level。由这些水平值构成的向量就称为因子。
#这个语句可以显示出各个变量是什么意思

使用这个符号$取出某一列数据,cyl这一列可以作为因子类型
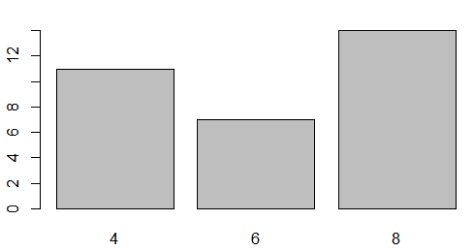
使用table()函数进行频数统计,这里的意思是分为三种类型(因子的level是4,6,8):4,6,8;下面一行是对应的数量分别为11,7,14

将向量转换为因子使用factor()函数


ordered=T 指定水平之间的顺序

生成一个因子

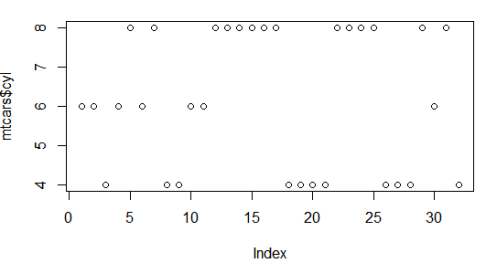
分别对向量和因子进行绘图
运用cut()函数进行有规律的分组,每隔10个,cut(num,c(seq(0,100,10)))

查看类型用class()函数

R 使用因子表示取值范围是已知集合的分类变量。要存在向量中没有的值,就会生成一条警告:
fruit <- c("apple", "banana")
parse_factor(c("apple", "banana", "bananana"), levels = fruit)

1.3.4 日期、日期时间与时间
parse_datetime() 期待的是符合 ISO 8601 标准的日期时间。ISO 8601 是一种国际标准,其中日期的各个部分按从大到小的顺序排列,即年、月、日、小时、分钟、秒:
parse_datetime("2010-10-01T2010")
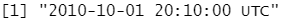
# 如果时间被省略了,那么它就会被设置为午夜
parse_datetime("20101010")
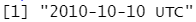
parse_date() 期待的是四位数的年份、一个 - 或 /、月、一个 - 或 /,然后是日:
parse_date("2010-10-01")
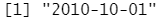
parse_time() 期待的是小时、:、分钟、可选的 : 和秒,以及一个可选的 a.m./p.m. 标识符:
library(hms)
parse_time("01:10 am")
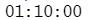
parse_time("20:10:01")
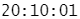
年: %Y(4 位数);%y(2 位数;00-69 → 2000-2069、70-99 → 1970-1999)。
月: %m(2 位数);%b(简写名称,如 Jan);%B(完整名称,如 January)。
日: %d(1 位或 2 位数);%e(2 位数)
时间: %H(0-23 小时);%I(0-12 小时,必须和 %p 一起使用);%p(表示 a.m./p.m.);%M(分钟);%S(整数秒);%OS(实数秒)。
非数值字符: %.(跳过一个非数值字符);%*(跳过所有非数值字符)。
1.4 解析文件
1.4.1 策略
readr 使用一种启发式过程来确定每列的类型,读取1000行,先使用 guess_parser() 函数返回 readr 最可信的猜测,接着 parse_guess() 函数使用这个猜测来解析列:
guess_parser("2010-10-01")
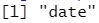
guess_parser("15:01")
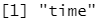
guess_parser(c("TRUE", "FALSE"))
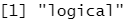
guess_parser(c("1", "5", "9"))

guess_parser(c("12,352,561"))

str(parse_guess("2010-10-10"))
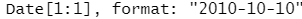
逻辑值:只包括 F、T、FALSE 和 TRUE。
整数:只包括数值型字符(以及 -)。
双精度浮点数:只包括有效的双精度浮点数(也包括 4.5e-5 这样的数值)。
数值:只包括带有分组符号的有效双精度浮点数。
时间:与默认的 time_format 匹配的值。
日期:与默认的 date_format 匹配的值。
日期时间:符合 ISO 8601 标准的任何日期。
1.5 写入文件
readr 还提供了两个非常有用的函数,用于将数据写回到磁盘:write_csv() 和 write_tsv()。如果想要将 CSV 文件导为 Excel 文件,可以使用 write_excel_csv() 函数,该函数会在文件开头写入一个特殊字符(字节顺序标记),告诉 Excel 这个文件使用的是 UTF-8 编码。
write_csv(challenge, "challenge.csv")
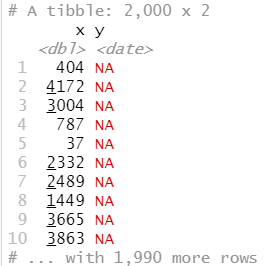
当保存为 CSV 文件时,类型信息就丢失了:
challenge
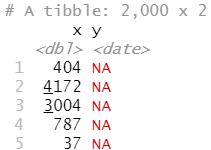
write_rds() 和 read_rds() 函数是对基础函数 readRDS() 和 saveRDS() 的统一包装。前
者可以将数据保存为 R 自定义的二进制格式,称为 RDS 格式:
write_rds(challenge, "challenge.rds")
read_rds("challenge.rds")
feather 包实现了一种快速二进制格式,可以在多个编程语言间共享:
library(feather)
write_feather(challenge, "challenge.feather")
read_feather("challenge.feather")

1.6 其他类型的数据
haven 可以读取 SPSS、Stata 和 SAS 文件;readxl 可以读取 Excel 文件(.xls 和 .xlsx 均可)。对于层次数据,可以使用 jsonlite(由 JeroenOoms 开发)读取 JSON 串,使用 xml2 读取
XML 文件。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15577382.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号