

dplyr包处理关系数据(键、内连接、外连接、筛选连接、集合操作)
使用dplyr处理关系数据
使用 dplyr 的一些函数来研究一下 nycflights13 中的关系数据,这些函数可以在两张数据表间进行操作。
library(tidyverse) library(nycflights13)
1.2 nycflights13
nycflights13 中包含了与 flights 相关的 4 个tibble:
(1) airlines:可以根据航空公司的缩写码查到公司全名。
airlines

(2)airports:给出了每个机场的信息,通过 faa 机场编码进行标识。
airports
(3)planes:给出了每架飞机的信息,通过 tailnum 进行标识。
planes
(4)weather:给出了纽约机场每小时的天气状况。
weather
对于 nycflights13 包中的表来说:
• flights 与 planes 通过单变量 tailnum 相连;
• flights 与 airlines 通过变量 carrier 相连;
• flights 与 airports 通过两种方式相连(变量 origin 和 dest);
• flights 与 weather 通过变量 origin(位置)以及 year、month、day 和 hour(时间)相连。
1.3 键
键的类型有两种。
• 主键:唯一标识其所在数据表中的观测。例如,planes$tailnum 是一个主键,因为其可
以唯一标识 planes 表中的每架飞机。
• 外键:唯一标识另一个数据表中的观测。例如,flights$tailnum 是一个外键,因为其出现在 flights 表中,并可以将每次航班与唯一一架飞机匹配。
一旦识别出表的主键,最好验证一下,看看它们能否真正唯一标识每个观测。一种验证方
法是对主键进行 count() 操作,然后查看是否有 n 大于 1 的记录:
planes %>% count(tailnum) %>% filter(n > 1)

weather %>% count(year, month, day, hour, origin) %>% filter(n > 1)
flights %>% count(year, month, day, flight) %>% filter(n > 1)
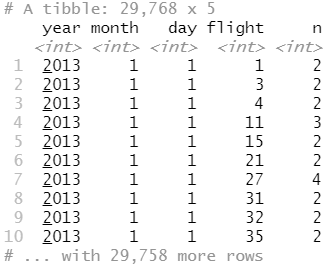
flights %>% count(year, month, day, tailnum) %>% filter(n > 1)
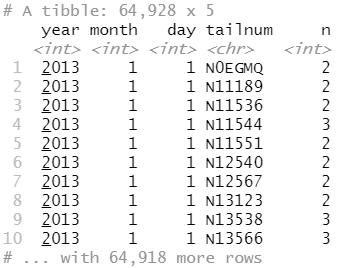
如果一张表没有主键,有时就需要使用 mutate() 函数和 row_number() 函数为表加上一个主键。
1.4 合并连接
合并连接可以将两个表格中的变量组合起来,它先通过两个表格的键匹配观测,然后将一个表格中的变量复制到另一个表格中。和 mutate() 函数一样,连接函数也会将变量添加在表格的右侧,因此如果表格中已经有了很多变量,那么新变量就不会显示出来。
flights2 <- flights %>% select(year:day, hour, origin, dest, tailnum, carrier) flights2
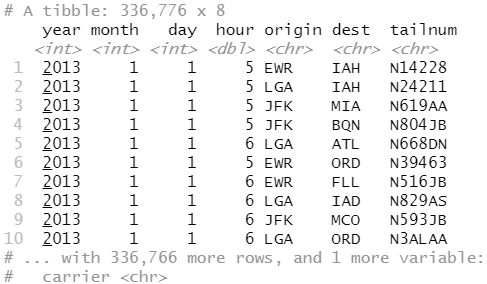
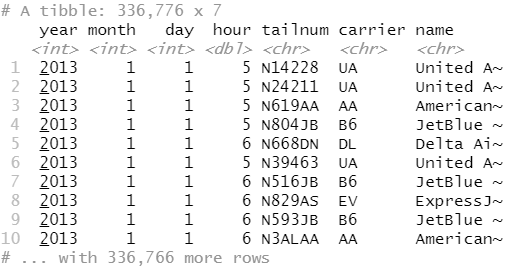
假设想要将航空公司的全名加入 flights2 数据集,你可以通过 left_join() 函数组合airlines 和 flights2 数据框:
flights2 %>% select(-origin, -dest) %>% #负号表示不选择origin和dest left_join(airlines, by = "carrier")
1.4.1 理解连接
x <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 3, "x3" ) y <- tribble( ~key, ~val_y, 1, "y1", 2, "y2", 4, "y3" )


1.4.2 内连接
内连接是最简单的一种连接。只要两个观测的键是相等的,内连接就可以匹配它们。
x %>% inner_join(y, by = "key")
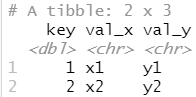
1.4.3 外连接
外连接有 3 种类型。
• 左连接:保留 x 中的所有观测。
• 右连接:保留 y 中的所有观测。
• 全连接:保留 x 和 y 中的所有观测。
最常用的连接是左连接:只要想从另一张表中添加数据,就可以使用左连接,因为它会保
留原表中的所有观测,即使它没有匹配。
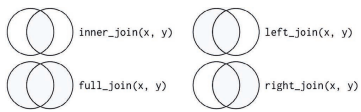
1.4.4 重复键
x <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 2, "x3", 1, "x4" ) y <- tribble( ~key, ~val_y, 1, "y1", 2, "y2" )


left_join(x, y, by = "key")

1.4.5 定义键列
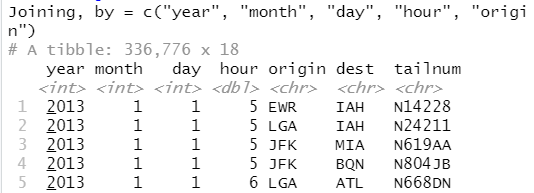
两张表都是通过一个单变量来连接的,这种限制条件是通过 by = "key" 来实现的。默认值 by = NULL。这会使用存在于两个表中的所有变量,这种方式称为自然连接。
flights2 %>% left_join(weather)
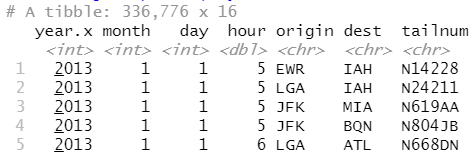
字符向量 by = "x"。这种方式与自然连接很相似,但只使用某些公共变量。
flights2 %>% left_join(planes, by = "tailnum")
命名字符向量 by = c("a" = "b")。这种方式会匹配 x 表中的 a 变量和 y 表中的 b 变量。
输出结果中使用的是 x 表中的变量。
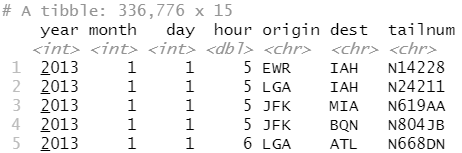
因为每次航班都有起点机场和终点机场,所以需要指定使用哪个机场进行连接:
flights2 %>%
left_join(airports, c("dest" = "faa"))
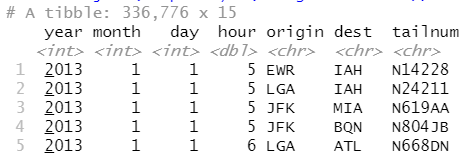
flights2 %>%
left_join(airports, c("origin" = "faa"))
1.5 筛选连接
筛选连接有两种类型。
• semi_join(x, y):保留 x 表中与 y 表中的观测相匹配的所有观测。
• anti_join(x, y):丢弃 x 表中与 y 表中的观测相匹配的所有观测。
假设你已经找出了最受欢迎的前 10 个目的地:
top_dest <- flights %>% count(dest, sort = TRUE) %>% head(10) top_dest

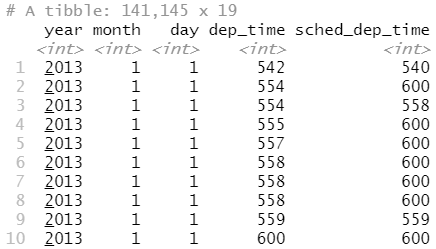
现在想要找出飞往这些目的地的所有航班,你可以自己构造一个筛选器:
flights %>% filter(dest %in% top_dest$dest)
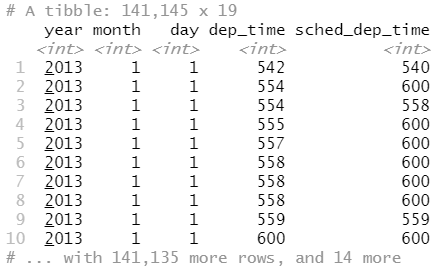
使用半连接,它可以像合并连接一样连接两个表,但不添加新列,而是保留 x表中那些可以匹配 y 表的行:
flights %>% semi_join(top_dest)
反连接可以用于诊断连接中的不匹配。例如,在连接 flights 和 planes 时,你可能想知道
flights 中是否有很多行在 planes 中没有匹配记录:
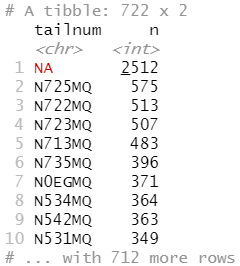
flights %>% anti_join(planes, by = "tailnum") %>% count(tailnum, sort = TRUE)
1.7 集合操作
集合操作需要 x 和 y 具有相同的变量,并将观测按照集合来处理。
intersect(x, y) 返回既在 x 表,又在 y 表中的观测。
union(x, y) 返回 x 表或 y 表中的唯一观测。
setdiff(x, y) 返回在 x 表,但不在 y 表中的观测。
df1 <- tribble( ~x, ~y, 1, 1, 2, 1 ) df2 <- tribble( ~x, ~y, 1, 1, 1, 2 )


intersect(df1, df2)
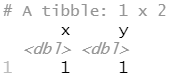
union(df1, df2)

setdiff(df1, df2)

setdiff(df2, df1)
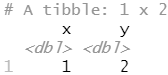
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15576938.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号