

使用lattice进行数据可视化-- 分组变量?
使用lattice进行高级绘图-- 分组变量
当你在lattice绘图公式中增加调节变量时,该变量每个水平的独立面板就会产生。如果想添加的结果和每个水平正好相反,可以指定该变量为分组变量。
比方说,我们想利用核密度图展示使用手动和自动变速器时汽车油耗的分布。我们可以使用下面的代码来添加相应的图形:(为什么我的图形没有出现呢,奇怪?)
library(lattice)
mtcars$transmission <- factor(mtcars$am, levels=c(0, 1),
labels=c("Automatic", "Manual"))
densityplot(~mpg, data=mtcars,
groups=transmission,
main="MPG Distribution by Transmission Type",
xlab="Miles per Gallon",
auto.key=list(space="right", columns=1, title="Transmission"))
#选项auto.key=TRUE创建了一个基本的图例并把它放在图的上方。我们可以通过在列表中指定选项对自动的键值进行有限的修改,比如auto.key=list(space="right", columns=1, title="Transmission")。
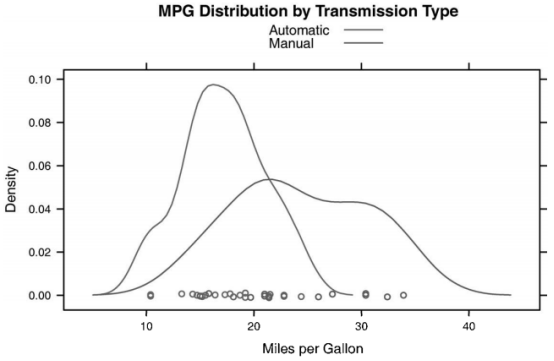
(此图为书上的)
如果想对图例取得更大的控制权,可以使用key=选项。
(2)带有分组变量和自定义图例的核密度估计(我的图为什么没有出现呢?)
library(lattice)
mtcars$transmission <- factor(mtcars$am, levels=c(0, 1),
labels=c("Automatic", "Manual")) #这里绘图符号、线条类型和颜色都被指定为向量
colors <- c("red", "blue")
lines <- c(1,2)
points <- c(16,17)
#自定义图例
key.trans <- list(title="Transmission",
space="bottom", columns=2,
text=list(levels(mtcars$transmission)),
points=list(pch=points, col=colors),
lines=list(col=colors, lty=lines),
cex.title=1, cex=.9)
# 相同的图类型、线条类型和颜色由densityplot()函数指定密度图
densityplot(~mpg, data=mtcars,
group=transmission,
main="MPG Distribution by Transmission Type",
xlab="Miles per Gallon",
pch=points, lty=lines, col=colors,
lwd=2, jitter=.005,
key=key.trans)
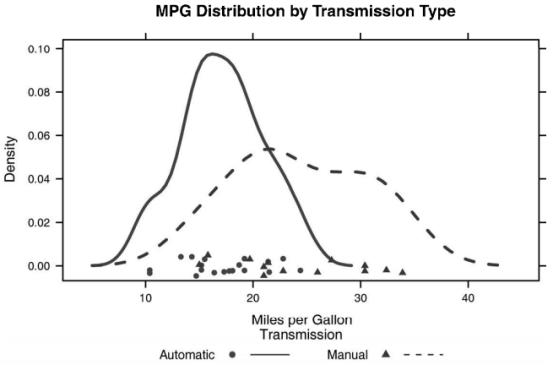
(此图为书上的)
(3)带有分组和调节变量以及自定义图例的xyplot函数
R安装时自带的CO2数据框描述了对Echinochloa crus-galli耐寒性的研究。
这个数据描述了12种植物(Plant)在7种二氧化碳浓度(conc)下的二氧化碳吸收率(uptake)。6种植物来自魁北克(Quebec),6种来自密西西比(Mississippi)。每个产地有3种植物在冷藏条件下研究,3种在非冷藏条件下研究。在这个例子中,Plant是分组变量,Type(魁北克/密西西比)和Treatment(冷藏/非冷藏))是调节变量。下面代码运行的结果见图:
library(lattice)
colors <- "darkgreen" #设置颜色
symbols <- c(1:12) #定义特征12种
linetype <- c(1:3) #定义线的类型有三种
key.species <- list(title="Plant", #图例的标题为Plant
space="right", #图例放置的位置
text=list(levels(CO2$Plant)), #设置图例的显示文本是数据集CO2种的Plant列
points=list(pch=symbols, col=colors)) #设置绘图种的符号有12种不同的标记pch=symbols
xyplot(uptake~conc|Type*Treatment, data=CO2,
group=Plant,
type="o",
pch=symbols, col=colors, lty=linetype,
main="Carbon Dioxide Uptake\nin Grass Plants",
ylab=expression(paste("Uptake ",
bgroup("(", italic(frac("umol","m"^2)), ")"))),
xlab=expression(paste("Concentration ", #使用expression()函数是为了将数学符号添加到坐标轴标签上。
bgroup("(", italic(frac(mL,L)), ")"))),
sub = "Grass Species: Echinochloa crus-galli",
key=key.species)
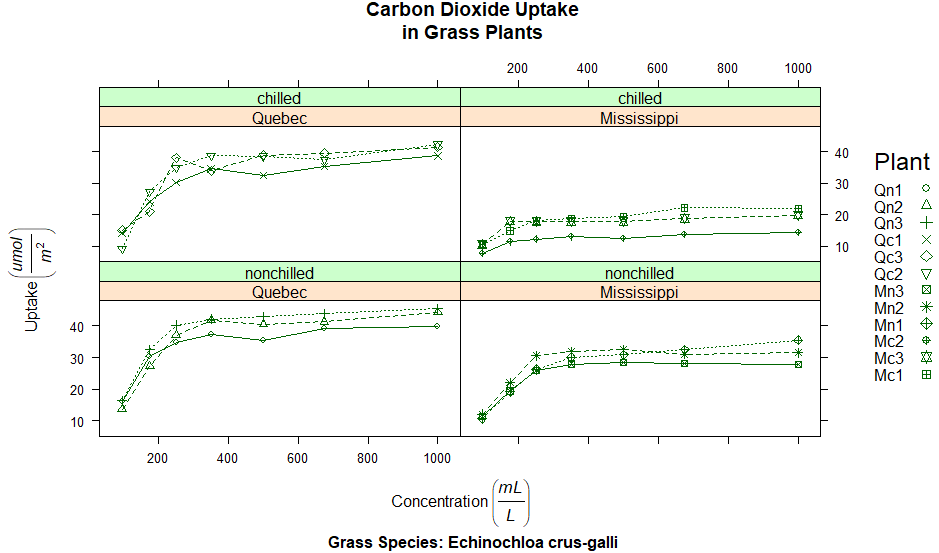
结果分析:Plant是分组变量(“ordered” “factor”即分类因子变量),Treatment和Type是调节变量(“factor”即因子变量),uptake~conc|Type*Treatment表示在给定因子Type和Treatment的水平后,数值变量二氧化碳吸收率uptake和二氧化碳浓度conc的关系。很明显,在冷藏条件下密西西比的植物有显著的不同。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15154381.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号