

高级编程--索引
高级编程--索引
任何数据对象中的元素都可以通过索引来提取。提取元素可以使用object[index],其中object是向量,index是一个整数向量。如果原子向量中的元素已经被命名,index也可以是这些名字中的字符串向量。需要注意的是,R中的索引从1开始,而不是像其他语言一样从0开始。
下面是一个例子,使用这种方法来分析没有命名的原子变量元素:
x <- c(20, 30, 40) x[3]
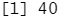
对于有命名的原子变量元素,可以使用:
x <- c(A=20, B=30, C=40) x[c(2,3)]

对列表来说,可以使用object[index]来提取成分(原子向量或其他列表),其中index是一个整数向量。下面的例子使用了上节中kmeans的fit对象:
fit[c(2,7)]

返回的是以列表形式出现的成分,为了得到成分中的元素,使用object[[integer]]:
fit[2]

如果想获取单个的命名成分,可以使用$符号。在这种情况下,object[[integer]]和
object$name是等价的:
fit$centers

可以组合这些符号以获得成分内的元素,例如:
fit[[2]][1,]

通过提取函数返回的成分和列表的元素,你可以获得结果并且继续深入。比如,你可以使用下面的代码画出聚类中心的线图。
(1)画出K均值聚类分析的中心:
set.seed(1234)
fit <- kmeans(iris[1:4], 3) #聚类:数据选1到4列,设置聚成3类
means <- fit$centers #获取聚类均值
library(reshape2) #矩阵通过reshape包被重塑成了长格式
dfm <- melt(means)
names(dfm) <- c("Cluster", "Measurement", "Centimeters")
dfm$Cluster <- factor(dfm$Cluster)
head(dfm)

library(ggplot2)
ggplot(data=dfm,
aes(x=Measurement, y=Centimeters, group=Cluster)) +
geom_point(size=3, aes(shape=Cluster, color=Cluster)) +
geom_line(size=1, aes(color=Cluster)) +
ggtitle("Profiles for Iris Clusters")
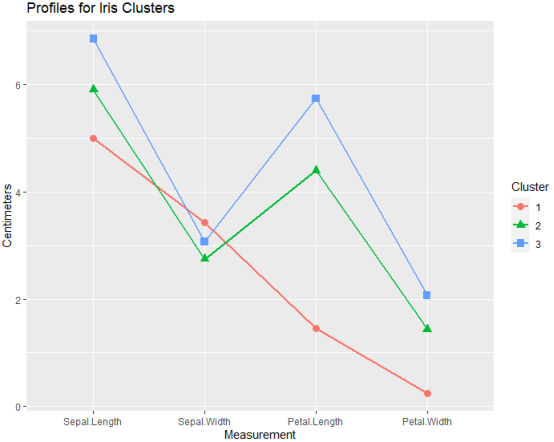
结果分析:出现这种类型的图形是可能的,因为所有的变量作图使用相同的测量单位(厘米)。如果聚类分析涉及不同尺度的变量,你需要在绘图前标准化数据,并标记y轴为标准化得分。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15154204.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号