

高级编程--数据类型(原子向量)
1 R 语言回顾
R是一种面向对象的、实用的数组编程语言,其中的对象是专门的数据结构,存储在RAM中,通过名称或符号访问。对象的名称由大小写字母、数字0~9、句号和下划线组成。名称是区分大小写的,而且不能以数字开头;句号被视为没有特殊含义的简单字符。
不像C和C++语言,在R语言中不能直接得到内存的位置。名称和符号本身是可以被操纵的对象。所有的对象在程序执行时都存储在RAM中,这对大规模数据分析有显著的影响。
每一个对象都有属性:元信息描述对象的特性。属性能通过attributes()函数罗列出来并能通过attr()函数进行设置。一个关键的属性是对象的类。R函数使用关于对象类的信息来确定
如何处理对象。可以使用class()函数来读取和设置对象的类。
1.1 数据类型
有两种最基本的数据类型:原子向量(atomic vector)和泛型向量(generic vector)。原子向量是包含单个数据类型的数组。 泛型向量也称为列表,是原子向量的集合。列表是递归的,因为它们还可以包含其他列表。
与许多语言不同,在R中不必声明对象的数据类型或是分配的空间。数据的类型由对象的内容隐式地决定,并且空间的增大或缩小自动取决于对象包含的类型和元素的数目。
1.1.1 原子向量
原子向量是包含单个数据类型(逻辑类型、实数、复数、字符串或原始类型)的数组。例如,
下面的每个都是一维原子向量:
passed <- c(TRUE, TRUE, FALSE, TRUE)
ages <- c(15, 18, 25, 14, 19)
cmplxNums <- c(1+2i, 0+1i, 39+3i, 12+2i)
names <- c("Bob", "Ted", "Carol", "Alice")
许多R的数据类型是带有特定属性的原子向量。例如,R没有标量型数据。标量是具有单一元素的原子向量,所以k<- 2是k <- c(2)的简写。
矩阵是一个具有维度属性(dim)的原子向量, 包含两个元素(行数和列数)。例如,以一维的数字向量x开始:
x <- c(1,2,3,4,5,6,7,8) class(x)
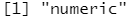
print(x)
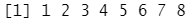
加上一个dim属性:
attr(x, "dim") <- c(2,4)
对象x现在变成了matrix类的2×4矩阵:
print(x)
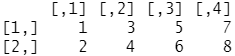
class(x)
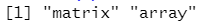
attributes(x)
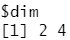
行名和列名可以通过加上一个dimnames属性得到:
attr(x, "dimnames") <- list(c("A1", "A2"), c("B1", "B2", "B3", "B4"))
print(x)

矩阵可以通过去除dim属性来得到一维的向量:
attr(x, "dim") <- NULL class(x)
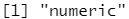
print(x)
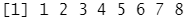
数组是有一个具有dim属性的原子向量,其中包含三个或更多元素。同样,你可以用dim属性来设置维度,还可以为标签赋予dimnames属性。与一维向量一样,矩阵和数组可以是逻辑类型、实数、复数、字符串或原始类型,但是不能把不同的类型放到一个矩阵或数组中。
attr()函数允许你创建任意属性并将其与对象相关联。属性存储关于对象的额外信息,函数能够用属性确定其处理方式。
有很多特定的函数可以用来设置属性,包括dim()、dimnames()、names()、row.names()、
class()和tsp()。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15154183.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号