

聚类分析(避免不存在的类)
避免不存在的类
聚类分析是一种旨在识别数据集子组的方法,并且在此方面十分擅长。事实上,它甚至能发现不存在的类。
install.packages("fMultivar")
library(fMultivar)
set.seed(1234)
df <- rnorm2d(1000, rho=.5)
df <- as.data.frame(df)
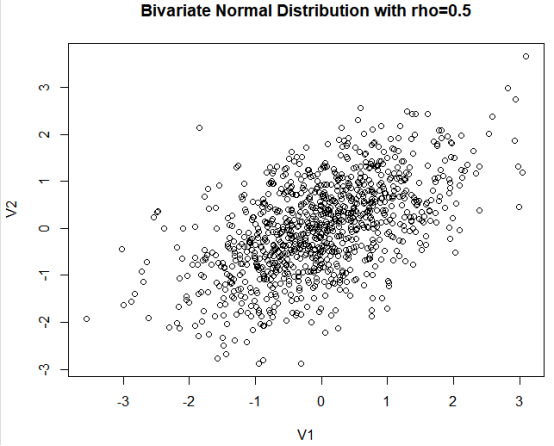
结果分析:fMultivar包中的rnorm2d()函数用来从相关系数为0.5的二元正态分布中抽取1000个观测值。所得的曲线显示在上图中。很显然,数据中没有类。
随后,使用wssplot()和Nbclust()函数来确定当前聚类的个数:
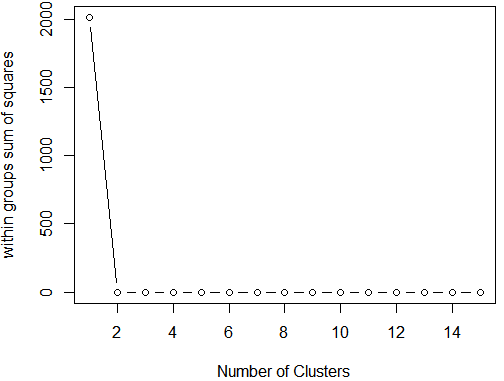
wssplot(df)
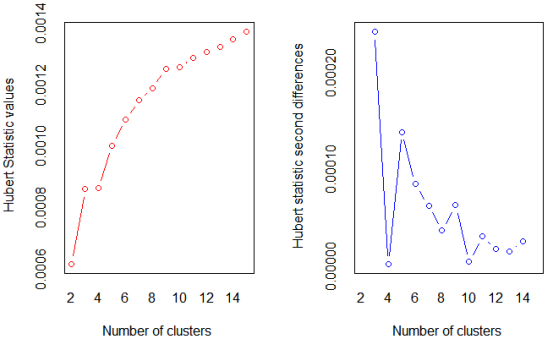
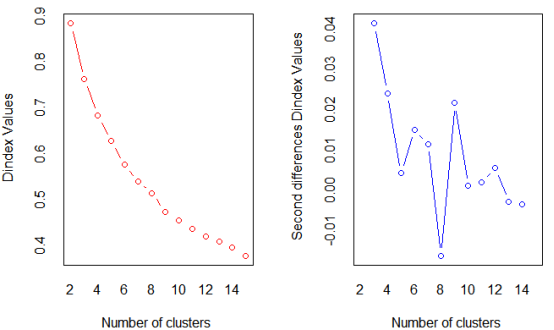
library(NbClust) nc <- NbClust(df, min.nc=2, max.nc=15, method="kmeans")
dev.new() barplot(table(nc$Best.n[1,]), xlab="Number of Clusters", ylab="Number of Criteria", main="Number of Clusters Chosen by 26 Criteria")
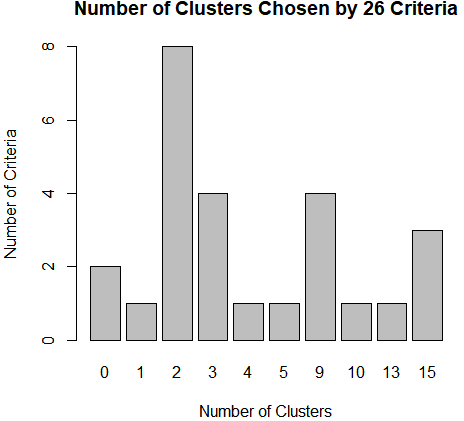
结果分析:使用Nbclust包中的判别准则推荐的二元数据的聚类数据,推荐的类数为2 或3。
wssplot()函数建议聚类的个数是3,然而NbClust函数返回的准则多数支持2类或3类。如果利用PAM法进行双聚类分析:
library(ggplot2)
library(cluster)
fit <- pam(df, k=2)
df$clustering <- factor(fit$clustering)
ggplot(data=df, aes(x=V1, y=V2, color=clustering, shape=clustering)) + #图是采用串联起来(+)号函数创建的
geom_point() + ggtitle("Clustering of Bivariate Normal Data")
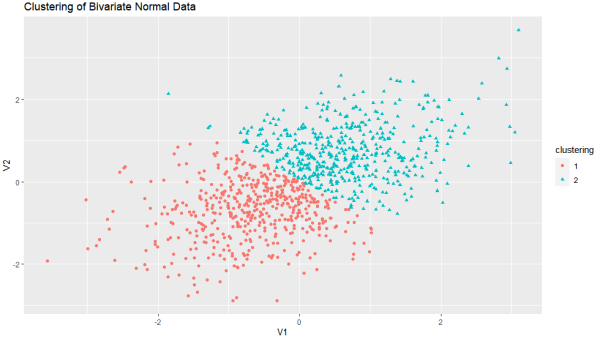
结果分析:对于二元数据的PAM聚类分析,提取两类。
plot(nc$All.index[,4], type="o", ylab="CCC", xlab="Number of clusters", col="blue")
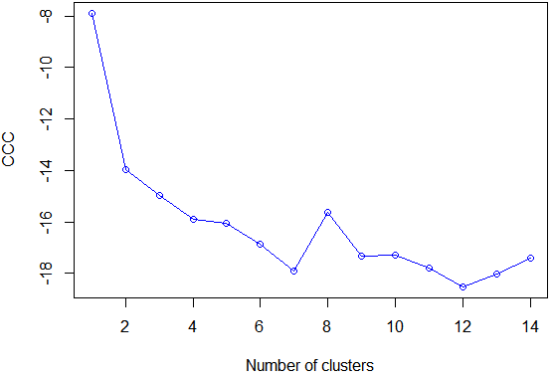
结果分析:现NbClust包中的立方聚类规则(Cubic Cluster Criteria,CCC)往往可以帮助我们揭示不存在的结构。当CCC的值为负并且对于两类或是更多的类递减时,就是典型的单峰分布。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15138213.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号