

深度学习--引言
对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为 CNN。
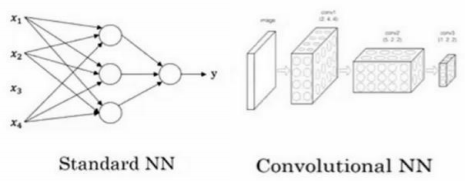
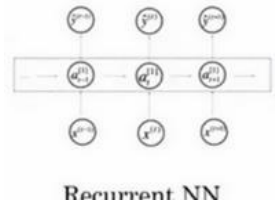
对于序列数据,例如音频,有一个时间组件,随着时间的推移,音频被播放出来,经常使用 RNN,一种递归神经网络(Recurrent Neural Network),递归神经网络(RNN)非常适合这种一维序列,数据可能是一个时间组成部分。
结构化数据意味着数据的基本数据库,例如在房价预测中,你可能有一个数据库,有专门的几列数据告诉你卧室的大小和数量,这就是结构化数据。
非结构化数据是指比如音频,原始音频或者你想要识别的图像或文本中的内容。
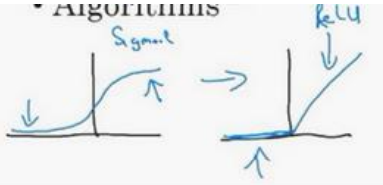
神经网络会使用激活函数,使用 sigmoid 函数和机器学习问题是,在这个区域,也就是这个 sigmoid 函数的梯度会接近零,所以学习的速度会变得非常缓慢,因为当你实现梯度下降以及梯度接近零的时候,参数会更新的很慢,所以学习的速率也会变的很慢,而通过改变这个被叫做激活函数的东西,神经网络换用这一个函数,叫做 ReLU 的函数(修正线性单元),ReLU 它的梯度对于所有输入的负值都是零,因此梯度更加不会趋向逐渐减少到零。而这里的梯度,这条线的斜率在这左边是零,仅仅通过将 Sigmod 函数转换成 ReLU 函数,便能够使得一个叫做梯度下降(gradient descent)的算法运行的更快,这就是一个或许相对比较简单的算法创新的例子。
符号定义 :
x:表示一个nx维数据,为输入数据,维度为(nx, 1);
y:表示输出结果,取值为(0,1);
(x(i), y(i)):表示第i组数据,可能是训练数据,也可能是测试数据,此处默认为训练数据;
x = [x(1), x(2), . . . , x(m)]:表示所有的训练数据集的输入值,放在一个 nx×m的矩阵中,其中m表示样本数目;
y = [y(1), y(2), . . . , y(m)]:对应表示所有训练数据集的输出值,维度为1×m;
训练集将由m个训练样本组成,其中(x(1), y(1))表示第一个样本的输入和输出,(x(2), y(2))表示第二个样本的输入和输出,直到最后一个样本(x(m), y(m)),然后所有的这些一起表示整个训练集。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15049687.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号