

R语言--六种数据类型
1 向量
1.1 定义向量
向量使用c来赋值,向量中不能混合不同类型的数据
x<-c(2,3,7,6,8) # 数值型num
y<-("one","two","three") #字符型chr
z<-c(TRUE,TRUE,FALSE) #逻辑型logi
查看变量的类型:class(x)
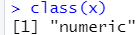
1.2 访问向量
访问中的元素,使用中括号(R语言区分大小写),R语言索引从1开始
访问第二个元素:x[2]
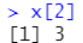
访问第1和第3个元素:x[c(1,3)]
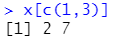
访问第1都第3的元素:x[c(1:3)] 或者x[1:3]

2 矩阵
2.1 定义矩阵
矩阵是二维的,矩阵中的数据类型不能混合
矩阵创建使用matrx():
x<-matrix(1:20,nrow=5,ncol=4) # 1:20定义了矩阵中的数据是1到20,规定了5行4列,默认情况下矩阵按列填充

添加一个字段byrow=T,是否按行填充,设置为TRUE或者T :
x1<-matrix(1:20,nrow=5,ncol=4,byrow=T)

2.2 矩阵的索引
获取第1行:x1[1,]
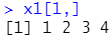
获取第3列:x1[,3]
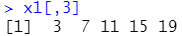
获取第3行第4列:x1[3,4]
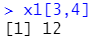
获取第3行第1,2列:x1[3,c(1,2)]

3 数组
3.1 定义数组
数组可以是二维,三维,使用array创建,定义2行3列的4张表
定义变量:
d1<-c("m1","m2")
d2<-c("n2","n2","n3")
d3<-c("p1","p2","p3","p4")
使用array组合成数组:
x2<-array(1:24,c(2,3,4),dimnames = list(d1,d2,d3)) # 1:24用来个创建的数组填充数据,c(2,3,4)用来确定数组的维度,dimnames用来给创建的数组取名字(以下是部分截图)

4 数据框
4.1 定义数据框
数据框可以混合不同类型的数据
首先定义几个变量:
patientID<-c(1,2,3,4)
age<-c(26,30,27,48)
diabetes<-c("type1","type2","type1","type2")
status<-c("poor","improved","excellent","poor")
使用data.frame构成数据框:
pt<-data.frame(patientID,age,diabetes,status)

4.2 访问数据框
访问数据框用中括号,访问第1和第2列:p1<-pt[1:2]

使用列名,访问某列:p2<-pt[c("age","status")]

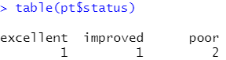
4.3频数表和交叉表
频数分析:table(pt$status)
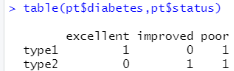
交叉分析:table(pt$diabetes,pt$status)
4.4变量搜索路径指定
(1)用attach将表添加到搜索路径(为了避免每次都要写$):attach(pt)

不需要这个表用detach,语句是:detach(pt)
(2)不想每次写表名,还可以使用with:
with(mtcars,{
+ plot(mpg,disp)
+ plot(mpg,wt)
+ })


在实际应用中建议把表名写清楚,不建议这样做
5 因子factor
5.1名义型变量
diabetes<-c("type1","type2","type1","type2")
diabetes1<-factor(diabetes)

5.2 有序型变量order,值顺序指定level
status<-c("poor","improved","excellent","poor")
status1<-factor(status,ordered = T,levels = c("poor","improved","excellent"))

5.3 案例(作业)
有因子变量在表中:
patientID<-c(1,2,3,4)
age<-c(26,30,27,48)
diabetes<-c("type1","type2","type1","type2")
status<-c("poor","improved","excellent","poor")
diabetes1<-factor(diabetes)
status1<-factor(status,ordered = T,levels = c("poor","improved","excellent"))
Pt1<-data.frame(patientID,age,diabetes1,status1)
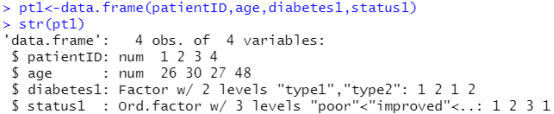
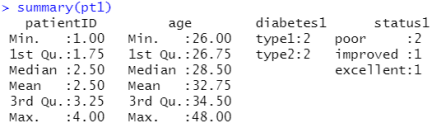
分析这个表使用summary(pt1),patientID和age为数值型,所以计算了它们的最大最小均值等,diabetes1和status1为因子变量,所以统计了它们的属性出现的次数。
6 列表list,可以混合以上各种数据
6.1 列表的定义
首先定义几个变量:
x<-"aaaa"
y<-c(22,44,55)
z<-matrix(1:9,nrow=3)
k<-c("one","two","three")
list1<-list(x,y,z,k)

给列表中的元素赋值:list2<-list(var1=x,var2=y,var3=z,var4=k)

6.2 列表的访问
用两个中括号或者访问名字
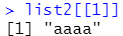
list2[[1]]
list2[["var1"]]

6.3 列表的用途
R语言的很多分析结果,都是以list形式返回的
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/14960594.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号