Base64编码的原理
Base64编码可以对字符串(中英文),字节集进行编码转换,核心思想就是3个字节一组进行处理,到最后不足3个字节,用00代替,被代替的用字符=来表示。
下面举三个例子就能立马明白:
例1、 "Bug"(正好3个字节,最简单的一种):
- 先转化成ASCII编码,如下图

- 图中的为十六进制,我们需要把他们转换成二进制分别为:
01000010,01110101,01100111
注意这里二进制是8位的,前面的0不能少 - 我们把3个二进制合并一下变成
010000100111010101100111 - 在把他们平均分割成四等份,四个新的二进制数诞生了,结果如下:
010000/100111/010101/100111
010000,100111,010101,100111 - 继续把这四个二进制数转换成十进制数,结果如下:
16,39,21,39 - 根据Base64 编码表,查找相对应的字符即可,最后得出结果:
QnVn
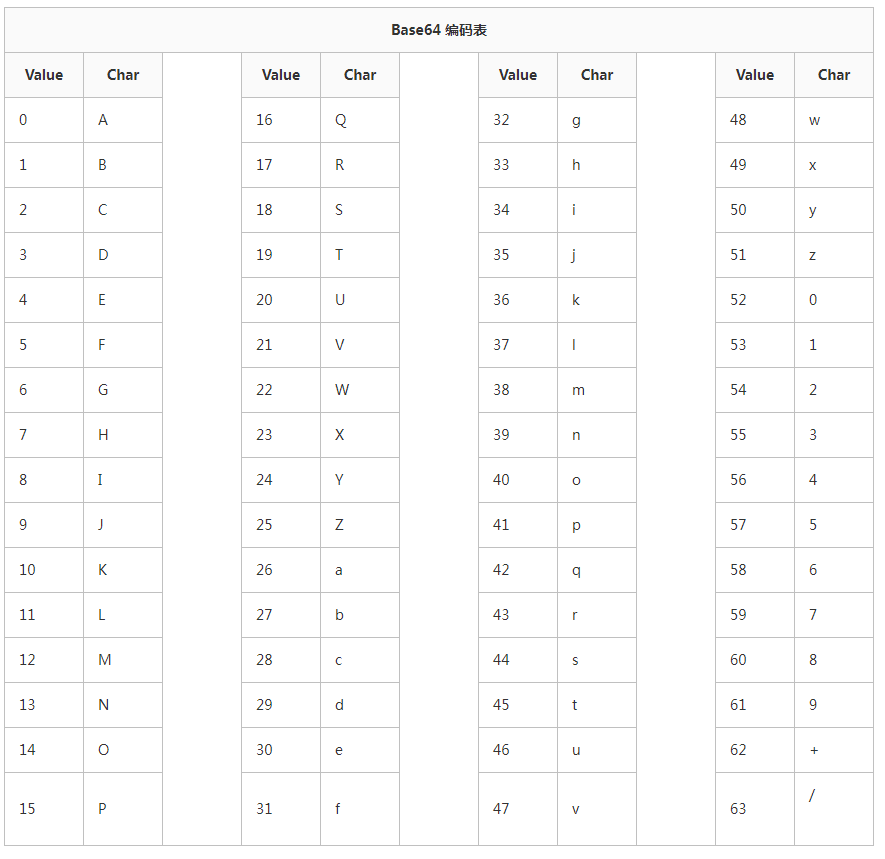
例2、 "算法"(正好4个字节,需要补全两个字节):
- 先转化成ASCII编码,如下图

- 前三个字节转换方法与例1相同,这里不再分析,直接得出结果y+O3,我们看下最后一个字节A8,补全成3字节如下:
A8,00,00 - 把他们转换成二进制分别为:
10101000,00000000,00000000 - 合并后分割成四等份
101010 000000 000000 000000
42,0,0,0 - 由于我们在后面补全了两个字节,所以后面必须得有两个=号。42与第一个0可以去表中查询,后面的两个0可以理解成异常用=表示,得出结果
qA== - 最终结果:
y+O3qA==
例3、 一张GIF图片(选取一张特别小的图片研究,最后需补全一个字节):
- 前面33个字节直接略过,得出结果:
R0lGODlhAQABAIAAAAUEBAAAACwAAAAAAQABAAACAkQB
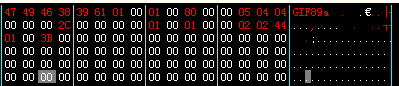
- 剩下两个字节补全成3个字节如下:
00,3B,00 - 把他们转换成二进制数,结果如下:
00000000,00111011,00000000 - 合并后分割成四等份
000000 000011 101100 000000
0,3,44,0 - 由于最后补全了一个字节,所以最后一位为=号,前面三位去表中查询,得出结果
ADs= - 最终结果:
R0lGODlhAQABAIAAAAUEBAAAACwAAAAAAQABAAACAkQBADs=
补充:(解码还原)
- 这里就举一个例子,逆着编码的思想来。以
T0s=为例
从表中查询对于编码为:
19,52,44,00 - 转换为二进制数如下:
10011,110100,101100,000000 - 合并后分成三等份并转换为十六进制ASCII码:
1001111 01001011 00000000
4F,4B - 由于补全了一位,最后就前两个ASCII码有效,最终结果如下:
源码:
最后cnPack已经为我们提供了现成的编码与解码单元,引用就可以编码或解码。正所谓学习偷懒两不误。
unit CnBase64;
{* |<PRE>
================================================================================
* 软件名称:开发包基础库
* 单元名称:Base64编码算法单元
* 单元作者:詹葵(Solin) solin@21cn.com; http://www.ilovezhuzhu.net
* wr960204
* 备 注:该单元有两个版本的Base64实现,分别属移植改进而来。
* 开发平台:PWin2003Std + Delphi 6.0
* 兼容测试:暂未进行
* 本 地 化:该单元无需本地化处理
* 修改记录:2019.12.12 V1.5
* 支持 TBytes
* 2019.04.15 V1.4
* 支持 Win32/Win64/MacOS
* 2018.06.22 V1.3
* 修正解出的原始内容可能包含多余 #0 或原始尾部 #0 被错误移除的问题
* 2016.05.03 V1.2
* 修正字符串中包含#0时可能会被截断的问题
* 2006.10.25 V1.1
* 增加 wr960204 的优化版本
* 2003.10.14 V1.0
* 创建单元
================================================================================
|</PRE>}
interface
uses
SysUtils, Classes;
function Base64Encode(InputData: TStream; var OutputData: string): Byte; overload;
{* 对流进行 Base64 编码,如编码成功返回 BASE64_OK
|<PRE>
InputData: TStream - 要编码的数据流
var OutputData: AnsiString - 编码后的数据
|</PRE>}
function Base64Encode(const InputData: AnsiString; var OutputData: string): Byte; overload;
{* 对字符串进行 Base64 编码,如编码成功返回 BASE64_OK
|<PRE>
InputData: AnsiString - 要编码的数据
var OutputData: AnsiString - 编码后的数据
|</PRE>}
function Base64Encode(InputData: Pointer; DataLen: Integer; var OutputData: string): Byte; overload;
{* 对数据进行 Base64 编码,如编码成功返回 BASE64_OK
|<PRE>
InputData: AnsiString - 要编码的数据
var OutputData: AnsiString - 编码后的数据
|</PRE>}
//{$IFDEF TBYTES_DEFINED}
//
//function Base64Encode(InputData: TBytes; var OutputData: string): Byte; overload;
//{* 对 TBytes 进行 Base64 编码,如编码成功返回 BASE64_OK
//|<PRE>
// InputData: TBytes - 要编码的数据流
// var OutputData: AnsiString - 编码后的数据
//|</PRE>}
//
//{$ENDIF}
function Base64Decode(const InputData: AnsiString; var OutputData: AnsiString;
FixZero: Boolean = True): Byte; overload;
{* 对数据进行 Base64 解码,如解码成功返回 BASE64_OK
|<PRE>
InputData: AnsiString - 要解码的数据
var OutputData: AnsiString - 解码后的数据
FixZero: Boolean - 是否移去尾部的 #0
|</PRE>}
function Base64Decode(const InputData: AnsiString; OutputData: TStream;
FixZero: Boolean = True): Byte; overload;
{* 对数据进行 Base64 解码,如解码成功返回 BASE64_OK
|<PRE>
InputData: AnsiString - 要解码的数据
var OutputData: TStream - 解码后的数据
FixZero: Boolean - 是否移去尾部的 #0
|</PRE>}
//{$IFDEF TBYTES_DEFINED}
//
//function Base64Decode(InputData: string; var OutputData: TBytes;
// FixZero: Boolean = True): Byte; overload;
//{* 对数据进行 Base64 解码,如解码成功返回 BASE64_OK
//|<PRE>
// InputData: string - 要编码的数据流
// var OutputData: TBytes - 解码后的数据
// FixZero: Boolean - 是否移去尾部的 0
//|</PRE>}
//
//{$ENDIF}
// 原始移植的版本,比较慢
function Base64Encode_Slow(const InputData: AnsiString; var OutputData: AnsiString): Byte;
// 原始移植的版本,比较慢
function Base64Decode_Slow(const InputData: AnsiString; var OutputData: AnsiString): Byte;
const
BASE64_OK = 0; // 转换成功
BASE64_ERROR = 1; // 转换错误(未知错误) (e.g. can't encode octet in input stream) -> error in implementation
BASE64_INVALID = 2; // 输入的字符串中有非法字符 (在 FilterDecodeInput=False 时可能出现)
BASE64_LENGTH = 3; // 数据长度非法
BASE64_DATALEFT = 4; // too much input data left (receveived 'end of encoded data' but not end of input string)
BASE64_PADDING = 5; // 输入的数据未能以正确的填充字符结束
implementation
var
FilterDecodeInput: Boolean = True;
const
Base64TableLength = 64;
Base64Table:string[Base64TableLength]='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
Pad = '=';
//------------------------------------------------------------------------------
// 编码的参考表
//------------------------------------------------------------------------------
EnCodeTab: array[0..64] of AnsiChar =
(
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/',
'=');
//------------------------------------------------------------------------------
// 解码的参考表
//------------------------------------------------------------------------------
{ 不包含在 Base64 里面的字符直接给零, 反正也取不到}
DecodeTable: array[#0..#127] of Byte =
(
Byte('='), 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00,
00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00,
00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 00, 62, 00, 00, 00, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 00, 00, 00, 00, 00, 00,
00, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 00, 00, 00, 00, 00,
00, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 00, 00, 00, 00, 00
);
// 原始移植的版本,比较慢
function Base64Encode_Slow(const InputData: AnsiString; var OutputData:AnsiString): Byte;
var
i: Integer;
CurrentB,PrevB: Byte;
c: Byte;
s: AnsiChar;
InputLength: Integer;
function ValueToCharacter(Value: Byte; var Character: AnsiChar): Boolean;
//******************************************************************
// 将一个在 0..Base64TableLength - 1 区间内的值,转换为与 Base64 编
// 码相对应的字符来表示,如果转换成功则返回 True
//******************************************************************
begin
Result := True;
if (Value > Base64TableLength - 1) then
Result := False
else
Character := AnsiChar(Base64Table[Value + 1]);
end;
begin
OutPutData := '';
InputLength := Length(InputData);
i:=1;
if (InputLength = 0) then
begin
Result := BASE64_OK;
Exit;
end;
repeat
// 第一次转换
CurrentB := Ord(InputData[i]);
Inc(i);
InputLength := InputLength-1;
c := (CurrentB shr 2);
if not ValueToCharacter(c, s) then
begin
Result := BASE64_ERROR;
Exit;
end;
OutPutData := OutPutData + s;
PrevB := CurrentB;
// 第二次转换
if InputLength = 0 then
CurrentB := 0
else
begin
CurrentB := Ord(InputData[i]);
Inc(i);
end;
InputLength := InputLength-1;
c:=(PrevB and $03) shl 4 + (CurrentB shr 4); //取出 XX 后 4 位并将其左移4位与 XX 右移 4 位合并成六位
if not ValueToCharacter(c,s) then //检测取得的字符是否在 Base64Table 内
begin
Result := BASE64_ERROR;
Exit;
end;
OutPutData := OutPutData+s;
PrevB := CurrentB;
// 第三次转换
if InputLength<0 then
s := pad
else
begin
if InputLength = 0 then
CurrentB := 0
else
begin
CurrentB := Ord(InputData[i]);
Inc(i);
end;
InputLength := InputLength - 1;
c := (PrevB and $0F) shl 2 + (CurrentB shr 6); //取出 XX 后 4 位并将其左移 2 位与 XX 右移 6 位合并成六位
if not ValueToCharacter(c, s) then //检测取得的字符是否在 Base64Table 内
begin
Result := BASE64_ERROR;
Exit;
end;
end;
OutPutData:=OutPutData+s;
// 第四次转换
if InputLength < 0 then
s := pad
else
begin
c := (CurrentB and $3F); //取出 XX 后6位
if not ValueToCharacter(c, s) then //检测取得的字符是否在 Base64Table 内
begin
Result := BASE64_ERROR;
Exit;
end;
end;
OutPutData := OutPutData + s;
until InputLength <= 0;
Result:=BASE64_OK;
end;
// 原始移植的版本,比较慢
function Base64Decode_Slow(const InputData: AnsiString; var OutputData: AnsiString): Byte;
var
i: Integer;
InputLength: Integer;
CurrentB, PrevB: Byte;
c: Byte;
s: AnsiChar;
Data: AnsiString;
function CharacterToValue(Character: AnsiChar; var Value: Byte): Boolean;
//******************************************************************
// 转换字符为一在 0..Base64TableLength - 1 区间中的值,如果转换成功
// 则返回 True (即字符在 Base64Table 中)
//******************************************************************
begin
Result := True;
Value := Pos(Character, Base64Table);
if Value=0 then
Result := False
else
Value := Value - 1;
end;
function FilterLine(const InputData: AnsiString): AnsiString;
//******************************************************************
// 过滤所有不在 Base64Table 中的字符,返回值为过滤后的字符
//******************************************************************
var
f: Byte;
i: Integer;
begin
Result := '';
for i := 1 to Length(InputData) do
if CharacterToValue(inputData[i], f) or (InputData[i] = Pad) then
Result:=Result + InputData[i];
end;
begin
if (InputData = '') then
begin
Result := BASE64_OK;
Exit;
end;
OutPutData := '';
if FilterDecodeInput then
Data := FilterLine(InputData)
else
Data := InputData;
InputLength := Length(Data);
if InputLength mod 4 <> 0 then
begin
Result := BASE64_LENGTH;
Exit;
end;
i := 0;
repeat
// 第一次转换
Inc(i);
s := Data[i];
if not CharacterToValue(s, CurrentB) then
begin
Result := BASE64_INVALID;
Exit;
end;
Inc(i);
s := Data[i];
if not CharacterToValue(s, PrevB) then
begin
Result := BASE64_INVALID;
Exit;
end;
c := (CurrentB shl 2) + (PrevB shr 4);
OutPutData := {$IFDEF UNICODE}AnsiString{$ENDIF}(OutPutData + {$IFDEF UNICODE}AnsiString{$ENDIF}(Chr(c)));
// 第二次转换
Inc(i);
s := Data[i];
if s = pad then
begin
if (i <> InputLength-1) then
begin
Result := BASE64_DATALEFT;
Exit;
end
else
if Data[i + 1] <> pad then
begin
Result := BASE64_PADDING;
Exit;
end;
end
else
begin
if not CharacterToValue(s,CurrentB) then
begin
Result:=BASE64_INVALID;
Exit;
end;
c:=(PrevB shl 4) + (CurrentB shr 2);
OutPutData := OutPutData+{$IFDEF UNICODE}AnsiString{$ENDIF}(chr(c));
end;
// 第三次转换
Inc(i);
s := Data[i];
if s = pad then
begin
if (i <> InputLength) then
begin
Result := BASE64_DATALEFT;
Exit;
end;
end
else
begin
if not CharacterToValue(s, PrevB) then
begin
Result := BASE64_INVALID;
Exit;
end;
c := (CurrentB shl 6) + (PrevB);
OutPutData := OutPutData + {$IFDEF UNICODE}AnsiString{$ENDIF}(Chr(c));
end;
until (i >= InputLength);
Result:=BASE64_OK;
end;
// 以下为 wr960204 改进的快速 Base64 编解码算法
function Base64Encode(InputData: TStream; var OutputData: string): Byte; overload;
var
Mem: TMemoryStream;
begin
Mem := TMemoryStream.Create;
try
Mem.CopyFrom(InputData, InputData.Size);
Result := Base64Encode(Mem.Memory, Mem.Size, OutputData);
finally
Mem.Free;
end;
end;
function Base64Encode(InputData: Pointer; DataLen: Integer; var OutputData: string): Byte; overload;
var
Times, I: Integer;
x1, x2, x3, x4: AnsiChar;
xt: byte;
begin
if (InputData = nil) or (DataLen <= 0) then
begin
Result := BASE64_LENGTH;
Exit;
end;
if DataLen mod 3 = 0 then
Times := DataLen div 3
else
Times := DataLen div 3 + 1;
SetLength(OutputData, Times * 4); //一次分配整块内存,避免一次次字符串相加,一次次释放分配内存
for I := 0 to Times - 1 do
begin
if DataLen >= (3 + I * 3) then
begin
x1 := EnCodeTab[(Ord(PAnsiChar(InputData)[I * 3]) shr 2)];
xt := (Ord(PAnsiChar(InputData)[I * 3]) shl 4) and 48;
xt := xt or (Ord(PAnsiChar(InputData)[1 + I * 3]) shr 4);
x2 := EnCodeTab[xt];
xt := (Ord(PAnsiChar(InputData)[1 + I * 3]) shl 2) and 60;
xt := xt or (Ord(PAnsiChar(InputData)[2 + I * 3]) shr 6);
x3 := EnCodeTab[xt];
xt := (Ord(PAnsiChar(InputData)[2 + I * 3]) and 63);
x4 := EnCodeTab[xt];
end
else if DataLen >= (2 + I * 3) then
begin
x1 := EnCodeTab[(Ord(PAnsiChar(InputData)[I * 3]) shr 2)];
xt := (Ord(PAnsiChar(InputData)[I * 3]) shl 4) and 48;
xt := xt or (Ord(PAnsiChar(InputData)[1 + I * 3]) shr 4);
x2 := EnCodeTab[xt];
xt := (Ord(PAnsiChar(InputData)[1 + I * 3]) shl 2) and 60;
x3 := EnCodeTab[xt ];
x4 := '=';
end
else
begin
x1 := EnCodeTab[(Ord(PAnsiChar(InputData)[I * 3]) shr 2)];
xt := (Ord(PAnsiChar(InputData)[I * 3]) shl 4) and 48;
x2 := EnCodeTab[xt];
x3 := '=';
x4 := '=';
end;
OutputData[I shl 2 + 1] := Char(X1);
OutputData[I shl 2 + 2] := Char(X2);
OutputData[I shl 2 + 3] := Char(X3);
OutputData[I shl 2 + 4] := Char(X4);
end;
OutputData := Trim(OutputData);
Result := BASE64_OK;
end;
function Base64Encode(const InputData: AnsiString; var OutputData: string): Byte; overload;
begin
if InputData <> '' then
Result := Base64Encode(@InputData[1], Length(InputData), OutputData)
else
Result := BASE64_LENGTH;
end;
//{$IFDEF TBYTES_DEFINED}
//
//function Base64Encode(InputData: TBytes; var OutputData: string): Byte; overload;
//begin
// if Length(InputData) > 0 then
// Result := Base64Encode(@InputData[0], Length(InputData), OutputData)
// else
// Result := BASE64_LENGTH;
//end;
//
//{$ENDIF}
function Base64Decode(const InputData: AnsiString; OutputData: TStream; FixZero: Boolean): Byte; overload;
var
Str: AnsiString;
begin
Result := Base64Decode(InputData, Str, FixZero);
OutputData.Size := Length(Str);
OutputData.Position := 0;
if Str <> '' then
OutputData.Write(Str[1], Length(Str));
end;
//{$IFDEF TBYTES_DEFINED}
//
//function Base64Decode(InputData: string; var OutputData: TBytes;
// FixZero: Boolean): Byte; overload;
//var
// InStr, OutStr: AnsiString;
//begin
// Result := Base64Decode(AnsiString(InputData), OutStr, FixZero);
// if Result = BASE64_OK then
// begin
//{$IFDEF UNICODE}
// OutputData := TEncoding.Default.GetBytes(OutStr);
//{$ELSE}
// SetLength(OutputData, Length(OutStr));
// if Length(OutStr) > 0 then
// Move(OutStr[1], OutputData[0], Length(OutStr));
//{$ENDIF}
// end;
//end;
//
//{$ENDIF}
function Base64Decode(const InputData: AnsiString; var OutputData: AnsiString; FixZero: Boolean): Byte;
var
SrcLen, DstLen, Times, i: Integer;
x1, x2, x3, x4, xt: Byte;
C, ToDec: Integer;
Data: AnsiString;
function FilterLine(const Source: AnsiString): AnsiString;
var
P, PP: PAnsiChar;
I: Integer;
begin
SrcLen := Length(Source);
GetMem(P, Srclen); //一次分配整块内存,避免一次次字符串相加,一次次释放分配内存
PP := P;
FillChar(P^, Srclen, 0);
for I := 1 to SrcLen do
begin
if Source[I] in ['0'..'9', 'A'..'Z', 'a'..'z', '+', '/', '='] then
begin
PP^ := Source[I];
Inc(PP);
end;
end;
SetString(Result, P, PP - P); //截取有效部分
FreeMem(P, SrcLen);
end;
begin
if (InputData = '') then
begin
Result := BASE64_OK;
Exit;
end;
OutPutData := '';
if FilterDecodeInput then
Data := FilterLine(InputData)
else
Data := InputData;
SrcLen := Length(Data);
DstLen := SrcLen * 3 div 4;
ToDec := 0;
// 尾部有一个等号意味着原始数据补了个 #0,两个等号意味着补了两个 #0,需要去掉也就是缩短长度
// 注意这不等同于原始数据的尾部是 #0 的情况,后者无须去掉
if Data[SrcLen] = '=' then
begin
Inc(ToDec);
if (SrcLen > 1) and (Data[SrcLen - 1] = '=') then
Inc(ToDec);
end;
SetLength(OutputData, DstLen); // 一次分配整块内存,避免一次次字符串相加,一次次释放分配内存
Times := SrcLen div 4;
C := 1;
for i := 0 to Times - 1 do
begin
x1 := DecodeTable[Data[1 + i shl 2]];
x2 := DecodeTable[Data[2 + i shl 2]];
x3 := DecodeTable[Data[3 + i shl 2]];
x4 := DecodeTable[Data[4 + i shl 2]];
x1 := x1 shl 2;
xt := x2 shr 4;
x1 := x1 or xt;
x2 := x2 shl 4;
OutputData[C] := AnsiChar(Chr(x1));
Inc(C);
if x3 = 64 then
Break;
xt := x3 shr 2;
x2 := x2 or xt;
x3 := x3 shl 6;
OutputData[C] := AnsiChar(Chr(x2));
Inc(C);
if x4 = 64 then
Break;
x3 := x3 or x4;
OutputData[C] := AnsiChar(Chr(x3));
Inc(C);
end;
// 根据补的等号数目决定是否删除尾部 #0
while (ToDec > 0) and (OutputData[DstLen] = #0) do
begin
Dec(ToDec);
Dec(DstLen);
end;
SetLength(OutputData, DstLen);
// 再根据外部要求删除尾部的 #0,其实无太大的实质性作用
if FixZero then
begin
while (DstLen > 0) and (OutputData[DstLen] = #0) do
Dec(DstLen);
SetLength(OutputData, DstLen);
end;
Result := BASE64_OK;
end;
end.
赏
 微信打赏
微信打赏
 支付宝打赏
支付宝打赏
微信打赏
支付宝打赏
如果觉得文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
作者:YXGust
出处:https://www.cnblogs.com/YXGust/p/16611570.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
本博文版权归本博主所有,转载请注明原文链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号