


Go语言的100个错误使用场景(30-40)|数据类型与字符串使用
 我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第四篇文章,对应书中第30-39个错误场景。
B站视频号:白泽talk,欢迎大家关注~
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第四篇文章,对应书中第30-39个错误场景。
B站视频号:白泽talk,欢迎大家关注~
前言
大家好,这里是白泽。《Go语言的100个错误以及如何避免》是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100个错误使用 Go 语言的场景,带你深入理解 Go 语言。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第四篇文章,对应书中第30-39个错误场景。
🌟 当然,如果您是一位 Go 学习的新手,您可以在我开源的学习仓库中,找到针对《Go 程序设计语言》英文书籍的配套笔记,其他所有文章也会整理收集在其中。
📺 B站:白泽talk,公众号【白泽talk】,聊天交流群:622383022,原书电子版可以加群获取。
前文链接:
4. 控制结构
🌟 章节概述:
- range 循环如何赋值
- 处理 range 循环和引用
- 避免遍历 map 导致问题
- 在循环内使用 defer
4.1 忽视元素在range循环中是拷贝(#30)
range 循环允许遍历的数据类型:
- String
- 数组
- 数组的指针
- 切片
- Map
- channel 中取值
s := []string{"a", "b", "c"}
// 保留值
for _, v range s {
fmt.Println("value=%s\n", v)
}
// 保留索引
for i := range s {
fmt.Println("index=%d\n", i)
}
🌟 值拷贝:
type account struct {
balance float32
}
accounts := []account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000
}
// 打印accounts切片,得到的结果为 [{100}, {200}, {300}],赋值没有影响到切片
[{100}, {200}, {300}]
Go 语言当中,所有的赋值都是拷贝:
- 如果函数返回一个结构体,表示这个结构体的拷贝。
- 如果函数返回一个结构体的指针,表示一个内存地址的拷贝。
因此上述 range 循环赋值的过程,只是将 1000 添加到了 a 这个拷贝的变量上。
🌟 修正方案:
for i := range accounts {
accounts[i].balance == 1000
}
for i := 0; i < len(accounts); i++ {
accounts[i].balance == 1000
}
如果业务逻辑简单,则推荐第一种,因为编码更少,如果逻辑复杂则推荐第二种,因为可能需要对 i 的大小进行逻辑判断。
特殊情况:
accounts := []*account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000
}
// 打印accounts切片
[{1100}, {1200}, {1300}]
遍历指针类型的 accounts 可以将修改在切片上生效,因为指向的内存是同一份。但是性能会比直接修改 struct 更低,这一点将在(#91)讲 CPU 缓存时着重讲解。
4.2 忽略在 range 循环中如何评估表达式(#31)
range 循环使用需要一个表达式,例如 for i in range exp,表达式只会在 range 循环前确定,循环中不会变更。
s := []int{0, 1, 2}
// 这个循环只会执行3次,而不会永无止境
for range s {
s = append(s, 10)
}
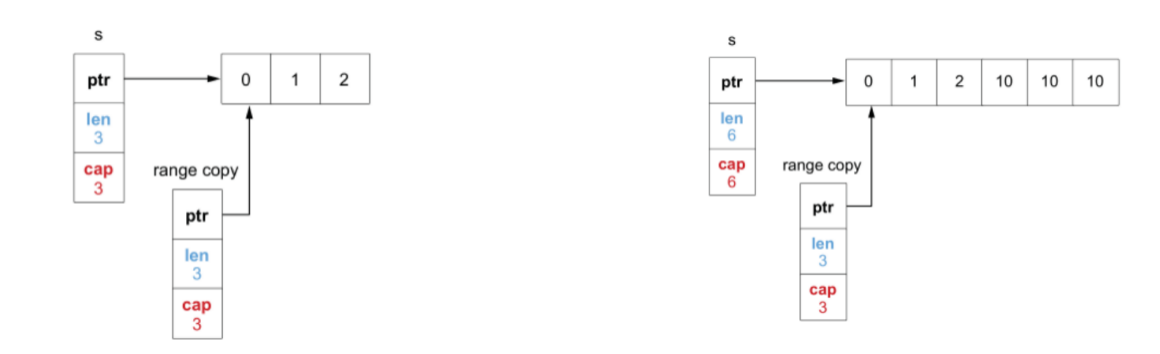
因为真正参与 range 遍历的,是 s 切片的一个拷贝,指向同一份底层数组,因此遍历结束后,s 切片确实增加了3的长度。
反例:
s := []int{0, 1, 2}
// 这个循环只会执行3次,而不会永无止境
for i := 0; i < len(s); i++ {
s = append(s, 10)
}
使用传统方式遍历切片,不断追加10会导致循环永远无法结束,因为表达式 len(s) 每次循环都会重新确定一次值。range 只会在循环开始前确定一次。
⚠️ 注意:range 的行为与具体表达式部分的数据类型也有关系,下面分析 channel 和 array。
channel:
ch1 := make(chan int, 3)
go func() {
ch1 <- 0
ch1 <- 1
ch1 <- 2
close(ch1)
}()
ch2 := make(chan int, 3)
go func() {
ch2 <- 10
ch2 <- 11
ch2 <- 12
close(ch2)
}()
ch := ch1
for v := range ch {
fmt.Println(v)
ch = ch2
}
// 结果输出
0 1 2
与上面提到的 range 表达式值确定规则一样,这里只会在 range 开始前将一个 ch 的拷贝变量参与到 range 循环当中,循环内部 ch = ch2 确实修改了外部 ch 的指向,所以如果有代码执行 close(ch) 则会关闭 ch2。
Array:
a := [3]int{0, 1, 2}
for i, v := range a {
a[2] = 10
if i == 2 {
fmt.Println(v)
}
}
// 输出结果2,而不是10
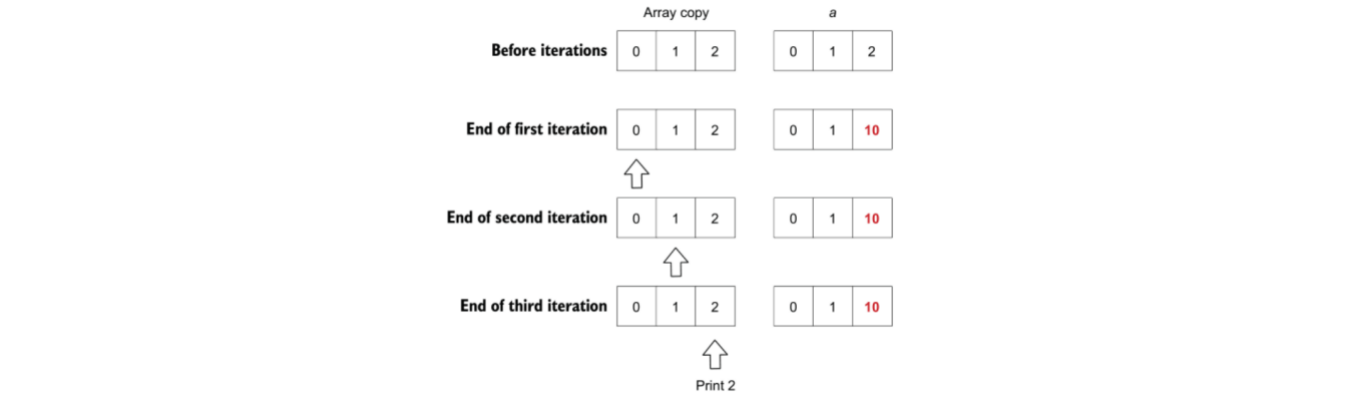
按照 range 的表达式渲染规则,循环之前会有一个长度为3的数组的拷贝创建用于参与循环,因为赋值操作针对的是 a 数组,所以对拷贝的数组没有影响,因为只会在循环前确定一次值。
a := [3]int{0, 1, 2}
for i, v := range &a {
a[2] = 10
if i == 2 {
fmt.Println(v)
}
}
通过获取数组 a 的地址,则即使发生一次拷贝,其指向的还是原来的 a 数组地址,所以 v 变量打印就是10。
4.3 忽略在 range 中使用指针元素的影响(#32)
错误示例:
type Customer struct {
ID string
Balance float64
}
type Sotre struct {
m map[string]*Customer
}
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
s.m[customer.ID] = &customer
}
}
--------------------------------------------
// 假设以如下代码运行
s.storeCustomers([]Customer{
{ID: "1", Balance: 10},
{ID: "2", Balance: -10},
{ID: "3", Balance: 0},
})
// 打印这个 map 将得到
key=1 value=&main.Customer{ID: "3", Balance: 0}
key=1 value=&main.Customer{ID: "3", Balance: 0}
key=1 value=&main.Customer{ID: "3", Balance: 0}
因为在 range 循环的时候,循环内的 customer 创建一次,是一个固定的地址,它不断被 range 表达式的拷贝变量赋值。
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
fmt.Printf("%p\n", &customer)
s.m[customer.ID] = &customer
}
}
// 输出结果
0xc000096029
0xc000096029
0xc000096029
因此循环结束之后,三个 key 指向的 value 都是同一个地址,自然也得到重复的3份内容。
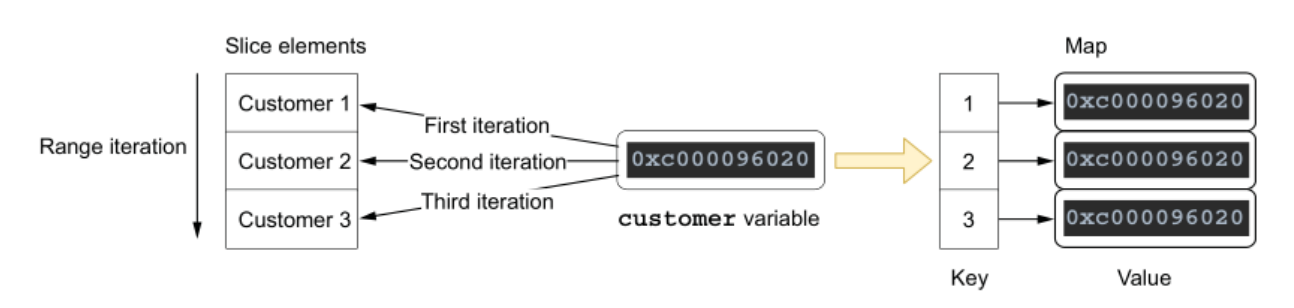
🌟 修正版本:
// 方法一
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
current := customer // 创建新的临时变量,确保地址唯一
s.m[current.ID] = ¤t
}
}
// 方法二
func (s *Store) storeCustomers(customers []Customer) {
for i := range customers {
customer := &customers[i] // 通过索引获取不同地址的 customer,因此也能确保地址唯一
s.m[customer.ID] = customer
}
}
4.4 对 map 遍历的错误假设(#33)
- Map 任何时候都不能在使用时假设它的顺序
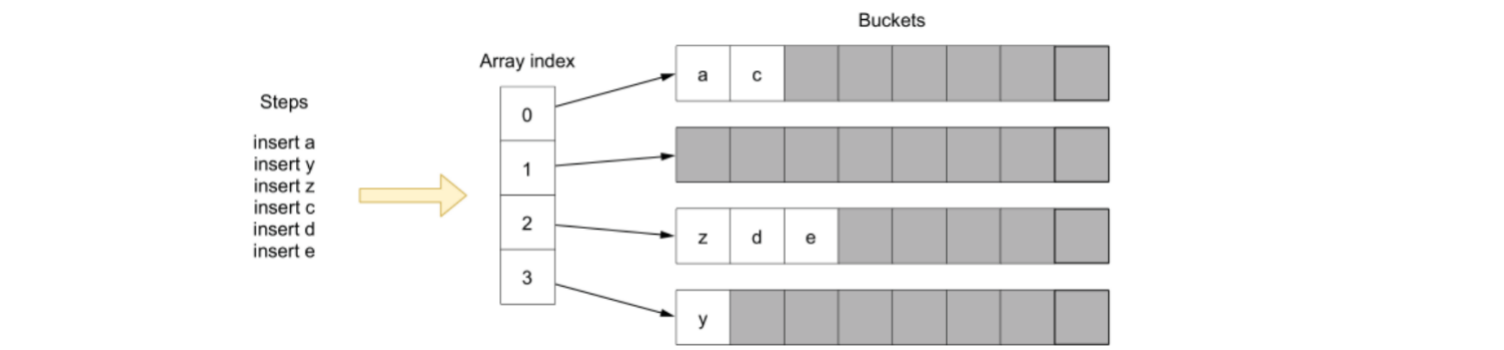
即使 map 已经被创建好了,两次不同的遍历都会出现不同的结果。这是设计者设计用于警示开发者:任何时候都不要依赖 map 的顺序。
- 在迭代的过程中插入 map
m := map[int]bool {
0: true,
1: false,
2: true,
}
for k, v := range m {
if v {
m[k+10] = true
}
}
fmt.Println(m)
// 运行3次得到不同答案
map[0: true 1:false 2:true 10: true 12:true 20:true 22:true 30:true]
map[0: true 1:false 2:true 10: true 12:true 20:true 22:true 30:true 32:true]
map[0: true 1:false 2:true 10: true 12:true 20:true]
结果不同的原因:在遍历 map 的时候,向 map 插入元素,可能会成功,可能会被忽略,不可预计。
修正方案:
m := map[int]bool {
0: true,
1: false,
2: true,
}
m2 := copyMap(m)
for k, v := range m {
m2[k] = v
if v {
m2[k+10] = true
}
}
fmt.Println(m2)
// 结果
map[0: true 1:false 2:true 10: true 12:true]
通过拷贝一个新的 m2,将新增的元素添加到新的 map 上即可。
4.5 忽略 break 的作用(#34)
概念:break 会结束 for、switch、select 的循环。
错误示例:
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2: // 当索引是2的时候,结束循环
break
}
}
上述代码无法在索引为2的时候终止循环,因为 break 只会结束 switch 的逻辑,不会影响到外部的 for。
修正方案:
loop:
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2: // 当索引是2的时候,结束循环
break loop
}
}
这种携带标签 loop 的 break 与 goto 不同之处在于,loop 可以替换成其他名称,使开发者可读性更友好,是 Go 中的地道用法。
针对 select 的示例:
loop:
for {
select {
case <-ch:
// Do something
case <-ctx.Done():
break loop
}
}
4.6 在循环中使用 defer(#35)
错误示例:
func readFiles(ch <-chan string) error {
for path := range ch {
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close()
// 处理 file
}
return nil
}
上述代码 file.Close() 需要等到 readFiles 函数 return 返回之前执行,如果不 return,则所有的文件描述符 file 将一直保持 Open 状态,不断以栈的方式堆积(后进先出),造成内存泄漏。
修正方案:
func readFiles(ch <-chan string) error {
for path := range ch {
if err := readFile(path); err != nil {
return err
}
}
return nil
}
func readFile(path string) error {
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close()
// 处理 file
return nil
}
通过将读取文件处理的步骤封装成一个函数,则可以在文件处理完成之后,在函数返回前,单独调用 defer,关闭 file。
通过必包实现:
func readFiles(ch <-chan string) error {
for path := range ch {
err := func() error {
// ...
defer file.Close()
// ...
}()
if err != nil {
return err
}
}
return nil
}
使用闭包的本质是一样的,前一个方式更加清晰,也方便添加单测。
5. 字符串
🌟 章节概述:
- 了解 rune 的概念
- 避免常见的字符串遍历和截取造成的错误
- 避免由于字符串拼接和转换造成的低效代码
- 避免获取子字符串造成的内存泄漏
5.1 不理解 rune 的概念(#36)
在 Go 语言当中,一个 rune 是一个 Unicode 的码点(code point),比如说“汉”这个字符,在 Unicode 字符集中,使用 U+6C49 这个 code point 定义,在 UTF-8 编码当中,使用:0xE6,0xB1,0x89 三个字节表示。
UTF-8 编码格式将字符用1-4个字节表示,最多32位,因此 Go 语言当中,一个 rune 是 int32 的别名。
type rune = int32
打印字符串的长度:
s := "汉"
fmt.Println(len(s))
// 结果3
因为 Go 语言内置的 len 函数,获取字符串的长度,计算的是这个字符串底层字节数组的字节数量。
5.2 不准确的字符串迭代(#37)

针对这张图片中的字符串(第二个字符占用两个字节),尝试遍历:
// 方式一
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
// 方式二
for i, v := range s {
fmt.Printf("position %d: %c\n", i, v)
}
// 方式三
runes := []rune(s)
for i, v := range runes {
fmt.Printf("position %d: %c\n", i, v)
}
🌟 结果展示:

方式一:range 遍历的是 s 的长度,每次遍历增加一个 code point 的长度,遍历的是每个码点的起始索引,因此1之后就是3了。因此打印 s[1] 无法对应字符串中第二个完整的 code point,而是打印出了底层字符数组的对应内容。
方式二:通过 range 可以直接遍历 code point(rune)。
方式三:先将字符串转换成 rune 切片,此时遍历则会一一对应。但是转换成 rune 切片会有额外 O(N) 的空间和时间开销,如果只是希望遍历 rune,则方式二即可,如果是希望获取 rune 的索引编号,则再使用方式三。
5.3 误用裁剪函数(#38)
fmt.Println(strings.TrimRight("123oxo", "xo")) // 123
fmt.Println(strings.TrimSuffix("123xoxo", "xo")) // 123xo
fmt.Println(strings.TrimLeft("xox123", "xo")) // 123
fmt.Println(strings.TrimPrefix("xoxo123", "xo")) // xo123
fmt.Println(strings.Trim("oxo123oxo", "xo")) // 123
代码一:从右边开始截取出现在 xo 字符集合中的 rune,直到不存在。
代码二:从右边开始截取一次,不会重复操作。
代码三:从左边截取出现在 xo 字符集合中的 rune,直到不存在。
代码四:从左边开始截取一次,匹配到才会裁剪,同样不会重复操作。
代码五:从整个字符串中去匹配出现在 xo 字符集合中的 rune,全部裁剪。
5.4 优化不足的字符串拼接(#39)
错误示例:
func concat1(values []string) string {
s := ""
for _, value := range values {
s += value
}
return s
}
由于 Go 语言的字符串是不可变的,因此上述循环中,会不断的重新分配内存去存储拼接后的字符串,性能较低。
修正方案:
func concat2(values []string) string {
sb := strings.Builder{}
for _, value := range values {
// 关于 error 的处理和忽略,将在(#53)讲解
_, _ = sb.WriteString(value)
}
return sb.String()
}
strings.Builder{} 在底层会通过字符切片存放字符串,并且不断的通过 append 方法追加字符切片。
注意点:
- 不可以并发调用
- 注意性能问题
func concat3(values []string) string {
tatal := 0
for i := 0; i < len(values); i++ {
total += len(values[i])
}
sb := strings.Builder{}
sb.Grow(total)
for _, value := range values {
// 关于 error 的处理和忽略,将在(#53)讲解
_, _ = sb.WriteString(value)
}
return sb.String()
}
在拼接字符串之前,调用 Grow 方法,为底层字符切片分配 total 的长度空间,这样可以避免字符切片扩容造成的开销。
拼接1000个字符串,每个1000字节,性能比较(banchmark):
concat1 16 72291485 ns/op
concat2 1188 878962 ns/op
concat3 5922 190340 ns/op
🌟 最佳实践:
在字符串个数超过5个的时候,使用 strings.Builder{},并且在总长度可以预计的情况下,优先使用 Grow 方法预分配空间。
小结
你已完成全书学习进度40%,再接再厉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号