

Go语言的100个错误使用场景(21-29)|数据类型
 我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第三篇文章,对应书中第21-29个错误场景。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第三篇文章,对应书中第21-29个错误场景。
前言
大家好,这里是白泽。《Go语言的100个错误以及如何避免》是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100个错误使用 Go 语言的场景,带你深入理解 Go 语言。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第三篇文章,对应书中第21-29个错误场景。
🌟 当然,如果您是一位 Go 学习的新手,您可以在我开源的学习仓库中,找到针对《Go 程序设计语言》英文书籍的配套笔记,期待您的 star。
公众号【白泽talk】,聊天交流群:622383022,原书电子版可以加群获取。
前文链接:
3. Data types
🌟 章节概述:
- 基本类型涉及的常见错误
- 掌握 slice 和 map 的基本概念,避免使用时产生 bug
- 值的比较
3.5 低效的切片初始化(#21)
实现一个 conver 方法,将一个切片 Foo 转换成另一个类型的切片 Bar,这里给出三种实现方式:
// 方式一
func convert(foos []Foo) []Bar {
bars := make([]Bar, 0)
for _, foo := range foos {
bars = append(bars, fooToBar(foo))
}
return bars
}
// 方式二
func convert(foos []Foo) []Bar {
n := len(foos)
// 设置容量但是不设置长度,此时append调用会从0索引开始为底层数组赋值
bars := make([]Bar, 0, n)
for _, foo := range foos {
bars = append(bars, fooToBar(foo))
}
return bars
}
// 方式三
func convert(foo []Foo) []Bar {
n := len(foo)
// 设置len之后,会初始化这部分的值为Foo的零值,此时append会追加在len之后,触发扩容
bars := make([]Bar, n)
for i, foo := range foos {
bars[i] = fooToBar(foo)
}
return bars
}
- 方式一:由于没有初始化切片的长度,因此切片随着 append 逐渐扩容,不断替换底层数组,增加 GC 压力,在已知切片长度的时候,不推荐使用。
- 方式二和方式三:单就性能来说方式三会更好一点,因为不用调用 append 操作。但是在大多数情况下方式二的表述更为清晰。因为如果遇到 convert 方法内有复杂逻辑,直接使用索引去为 bars[i] 设置值不太方便。
🌟 如果有一个场景是需要将一个 Foo 切片转换成一个两倍长度的 Bar 切片,则使用索引复制的方式看起来将不太清晰,且不易维护:
// 方式二
func convert(foos []Foo) []Bar {
n := len(foos)
// 设置容量但是不设置长度,此时append调用会从0索引开始为底层数组赋值
bars := make([]Bar, 0, 2*n)
for _, foo := range foos {
bars = append(bars, fooToBar(foo))
bars = append(bars, fooToBar(foo))
}
return bars
}
// 方式三
func convert(foo []Foo) []Bar {
n := len(foo)
// 设置len之后,会初始化这部分的值为Foo的零值,此时append会追加在len之后,触发扩容
bars := make([]Bar, 2*n)
for i, foo := range foos {
bars[2*i] = fooToBar(foo)
bars[2*i+1] = fooToBar(foo)
}
return bars
}
3.6 切片为 nil 与为空混淆(#22)
两个概念:
- 一个切片为空,如果它的长度是0
- 一个切片为nil,如果这个切片等于nil
func main {
var s []string // 方式一
long(1, s)
s = []string(nil) // 方式二
log(2, s)
s = []string{} // 方式三
log(3, s)
s = make([]string, 0) // 方式四
log(4, s)
}
func log(i int, s []string) {
fmt.Printf("%d: empty=%t\tnil=%t\n", i, len(s) == 0, s == nil)
}
// 输出结果
1: empty=true nil=true // 方式一
2: empty=true nil=true // 方式二
3: empty=true nil=false // 方式三
4: empty=true nil=false // 方式四
所有切片的 len 都是0,因此 nil 切片也是空切片。在探究哪种初始化切片之前,需要提示两点:
- 空切片和 nil 切片的区别在于是否分配地址,初始化一个 nil 切片不会发生地址分配(底层数组)。
- 无论切片是空还是 nil,内置的 append 方法都可以直接调用。
因此如果需要初始化一个 nil 切片,推荐上述方式一(var s []string);如果需要初始化一个长度为0的空切片,则使用方式四(make([]string, 0))。
当然如果你需要初始化一个已知长度的切片,不仅仅是空切片,也推荐方式四:
func intsToStrings(ints []int) []string {
// 使用 make([]string, 0, len(ints)) 以及 append 的方式也是可以的
s := make([]string, len(ints))
for i, v := range ints {
s[i] = strconv.Itoa(v)
}
}
- 方式二的意义:
s := append([]string(nil), "32")
类似语法糖的用法,可以用一行代码完成切片初始化和添加元素的编写。
- 方式三使用场景分析:
s := []string{"1", "2", "3"}
如果初始化切片但是不设置初始元素 s := []string{},则不如使用方式一 var s []string 进行初始化。方式三应该用在需要指定初始化值的切片时。
留意空切片(empty but non-nil)和 nil 切片(empty and nil)在一些库中会发生不同处理:
encoding/json库中,针对marshal序列化方法,空切片序列化为 [],而 nil 切片序列化为 null。- 标准库
reflect.DeepEqual方法中,比较 nil 和 空切片返回 false。
3.7 没有正确检查切片是否为空(#23)
示例代码1:
func handleOperations(id string) {
operations := getOperations(id)
if operations != nil {
handle(operations)
}
}
func getOperations(id string) []float32 {
operations := make([]float32, 0)
if if == "" {
return operations
}
// ... 相关逻辑
return operations
}
假设调用 getOperations 得到 []float32 切片后,通过判断它是否为 nil 来决定是否执行 handle 方法,但事实上,getOperations 方法从来都不会返回 nil,因此这种情况下 handle(operations) 一定会触发。
此时有两种修改方式:
- 修改被调用方(不推荐):
func getOperations(id string) []float32 {
operations := make([]float32, 0)
if if == "" {
return nil // 返回一个 nil 切片
}
return operations
}
此时调用方代码中 operations != nil 确实可以生效,但是作为被调用方的函数来说,本身是无法预计所有被调用的场景的,并且什么时候返回 nil,什么时候返回空,不应该通过习惯去约束。
🌟 而应该在在调用方 handleOperations 侧做更通用的判断。
- 修改调用方:
func handleOperations(id string) {
operations := getOperations(id)
if len(operations) != 0 {
handle(operations)
}
}
因为无论切片是 nil 还是空,都会满足 len(operations) != 0 这个条件。
3.8 错误的切片拷贝(#24)
错误示例:
src := []int{0, 1, 2}
var dst []int
copy(dst, src)
fmt.Println(dst) // 输出 [] 而不是 [0, 1, 2]
原因在于内置的 copy 函数,拷贝的切片的元素个数等于:min(len(dst), len(src))
修正方案:
src := []int{0, 1, 2}
dst := make([]int, len(src))
copy(dst, src)
fmt.Println(dst) // 输出 [0, 1, 2]
通过 append 方法实现拷贝切片的功能:
src := []int{0, 1, 2}
dst := append([]int(nil), src...)
通过这种方式,将一个切片追加到一个 nil 切片之中,此时 dst 切片的长度和容量都为3。
3.9 切片使用 append 的副作用(#25)
示例代码:
s1 := []int{1, 2, 3}
s2 := s1[1:2]
s3 := append(s2, 10)
fmt.Println(s1, s2, s3) // [1, 2, 10] [2] [2, 10]

当执行完上述第三行代码,s1 切片的第三个元素也发生了修改。
这种情况也发生在将切片作为参数传递给某个函数:
func main() {
s := []int{1, 2, 3}
f(s[:2])
fmt.Println(s) // [1, 2, 10]
}
func f(s []int) {
_ = append(s, 10)
}
🌟 有两种方法可以避免这个问题。
方法一:
func main() {
s := []int{1, 2, 3}
sCopy := make([]int, 2)
copy(sCopy, s)
f(sCopy)
fmt.Println(s) // [1, 2, 3]
}
在传入切片之前,将其通过 copy 函数拷贝一份,则无论其是否在 f 中被改动,将不会影响 s。
方法二:
func main() {
s := []int{1, 2, 3}
f(s[:2:2])
}
切片截取 s[low:high:max] 前两个参数左闭右开控制切片区间,第三个参数控制新切片的容量(max-low)。
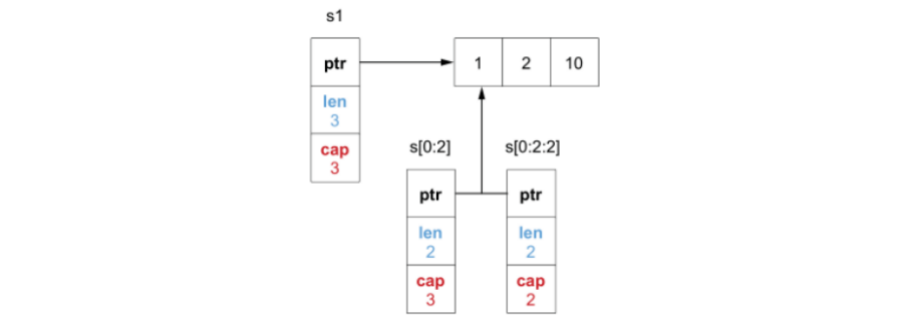
由于此时通过 s[:2:2] 创建的切片容量是2,如果在 f 函数内对其进行 append 操作时,由于 len 已经等于 cap,将触发扩容,导致其底层数组将引用一个新的二倍扩容后的数组。
3.10 切片和内存泄漏(#26)
🌟 场景一:切片容量泄漏
func consumeMessages() {
for {
msg := receiveMessage() // 假设每次msg都是一个长度为1000000的字节切片
storeMessageType(getMessageType(msg))
}
}
// 字符切片截取函数,截取前5个字符
func getMessageType(msg []byte) []byte {
return msg[:5]
}
这个场景不断输入大小为 1M 的字节切片,截取前五个字节存储。如果一共有1000个切片传入,程序运行之后,内存占用将达到1G。
分析原因:
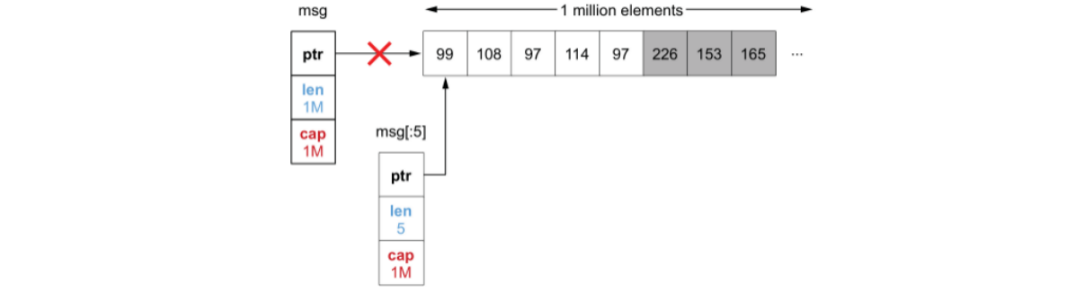
for 循环内,getMessageType() 函数每次在调用之后,虽然 msg 切片变量已经不在被引用,从而被 GC 回收,但是底层的数组没有收到影响。
即 getMessageType() 函数每次截取前5个字符,但是 msg[:5] 切片的 cap 值依旧是1M,Go 语言并不会自动回收其余部分的内存占用。
解决方案:
// 有效方案
func getMessageType(msg []byte) []byte {
msgType := make([]byte, 5)
copy(msgType, msg)
return msgType
}
// 无效方案
func getMessageType(msg []byte) []byte {
return msg[:5:5]
}
通过 copy 创建新的切片存放5个字节,使得原 msg 以及底层数组解除引用从而在 for 循环后被 GC 回收。但是通过 msg[:5:5] 方式创建切片,虽然限制了索引5之后的位置的访问,但是 Go 语言目前不支持自动回收这部分无法访问的内存。
🌟 场景二:切片和引用
type Foo struct {
v []byte
}
func main() {
foos := make([]Foo, 1_000)
printAlloc()
for i := 0; i < len(foos); i++ {
foos[i] = Foo{
v: make([]byte, 1024*1024),
}
}
printAlloc()
two := keepFirstTwoElementsOnly(foos)
runtime.GC()
printAlloc()
runtime.KeepAlive(two) // 保持对变量two的引用
}
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
return foos[:2]
}
func printAlloc() {
var m runtime.MemStats // 记录内存分配
runtime.ReadMemStats(&m)
fmt.Printf("%d KB\n", m.Alloc/1024)
}
// 结果展示
95 KB // 分配了1000个零值的 Foo 结构
1024098 KB // 为长度为1000的 Foo 切片的 v 属性分配内存1024*1024
1024101 KB // 虽然截取前两个元素,但是后998个Foo以及其内部v的内存依旧占用
⚠️ 注意:如果切片的元素是引用类型或者是一个内部有引用类型的结构,在这个元素被回收之前,则这个元素所指向内容将不会被 GC 自动回收。(引用链依旧存在)
解决方案:
// 方式一
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
res := make([]Foo, 2)
copy(res, foos)
return res
}
// 方式二
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
for i := 2; i < len(foos); i++ {
foos[i].v = nil
}
return foos[:2]
}
方式一:通过上面反复提及的 copy 创建一个新的切片实现赋值,此时新切片 len 和 cap 都是2。原切片 foos 由于不再被引用,则整体全部被 GC 回收,包括每个 Foo 结构的 v 切片。
方式二:通过手动将索引2至999的 Foo 结构的 v 切片手动设置为 nil,此时后998个 Foo 元素的 v 切片底层数组失去引用,会被 GC 回收。与方式一的区别在于,for 循环之后,foos[:2] 新切片 len 为2但是 cap 依旧为1000。

🌟 使用这两种方案自行权衡效率,方案一需要遍历0至i-1的元素,方案二需要遍历i至n-1的元素。
3.11 低效的 Map 初始化(#27)
🌟 map 的实现:

map 本质是一个 hash table,以数组的形式组织一系列的 bucket,每个 bucket 固定存放8个键值对,根据 key 的 hash 结果,决定这个 key-value 存放在哪个索引的 bucket 中。
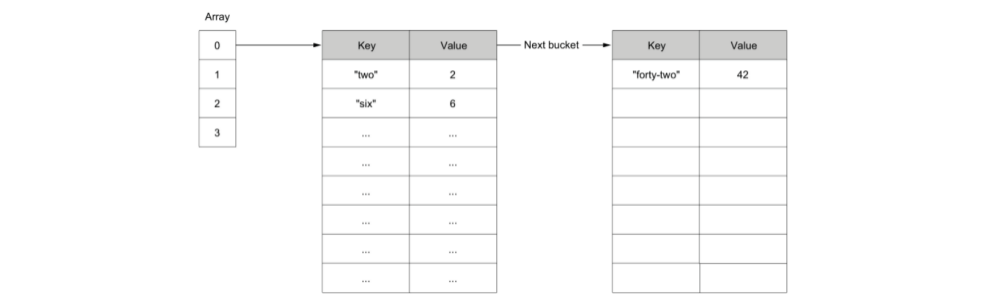
如果相同 hash 值的键值对超过8个,则会创建一个新的 bucket,被前一个 bucket 链式引用,因此最差情况下,查询效率会退化成 O(p),p 等价于这个 bucket 链条中键值对的个数。
🌟 map 的初始化:
mp := map[string]int {
"1": 1,
"2", 2,
"3", 3
}
当逐渐向这个 map 添加 1_000_000 个键值对,达到某些条件时会触发 map 的扩容,因为 map 的设计上不会允许 hash 值相同的 bucket 链无限延长,这失去了 hash table 的效率。
🌟 扩容时机:
- 负载因子:当 bucket 的平均容量超过6.5。
- 太多的 bucket 溢出(包含超过8个键值对)。
在这两种情况下,map 会触发扩容,增加 hash array 的长度,并重建整个 map,重新整理和平衡各个 bucket 链。这种情况下,会导致绝大多数键值对重新分配,因此简单的一次 insert 操作,性能可能就跌落为 O(N),N 为当前 map 的所有键值对数量。
🌟 高效的初始化:
mp := make(map[string]int, 1_000_000)
与切片的初始化类似,通过指定希望存放的键值对的个数,map 的内置初始化流程会根据输入的容量,创建一个合适大小的 map。这为后续存入 1_000_000 免去了 map 扩容导致的重建开销。
同样的,指定 1_000_000 大小,不意味着这个 map 只能存放这么多键值对,这只是提示给 Go runtime 去分配至少能容纳 1_000_000 键值对的空间。
// 分配1_000_000容量的 banchmarks,性能相差约60%
InitiateMapWithoutSize 6 227413490 ns/op
InitiateMapWithSize 13 91174193 ns/op
3.12 Map 和内存泄漏(#28)
概念:Go 语言的 Map 只能增长大小,并不能自动收缩,即使内部元素被删除。
场景分析:
n := 1_000_000
m := make(map[int][128]byte)
printAlloc()
for i := 0; i < n; i++ {
m[i] = randBytes() // 获取长度128的字符切片
}
printAlloc()
for i := 0; i < n; i++ {
delete(m, i)
}
runtime.GC()
printAlloc()
runtime.KeepAlive(m) // 保持对m的引用,避免被回收
// 打印结果展示
0 MB
461 MB
293 MB
第一次打印:由于初始化的是空的切片,因此没有分配内存。
第二次打印:添加了一百万个字符数组。
第三次打印:虽然从 map 中删除了这一百万个字符数组,但是内存占用依旧很大。
🌟 原因分析:
type hmap struct {
B uint8 // 2^B 个 buckets
// ...
}
Go 语言的 map 底层实现是一个 hmap 结构,有一个 B 字段存放 map 的 buckets 的个数,这个场景下,存放 1_000_000 个键值对,B == 18,2^18 == 262144 个 buckets。
当 delete 1_000_000 个键值对之后,B 依旧是18,意味着 buckets 没有减少,只是将 bucket 对应的插槽设置为0值。
因此如果用 map 做缓存,当 map 某一时间段扩容到很大情况时,后续访问量下降,这个 map 还是占用很大的内存空间。
🌟 解决方案:
- 方案一:使用 map 做缓存,则根据时间,定期新创建一个 map,去存放旧 map 的元素,人工去释放旧 map。(缺点在于在下次 GC 触发之前,会占用两倍内存,并且拷贝 map 中元素也需要花费时间,同时需要考虑并发安全)。
- 方案二:将键值对的值元素使用指针替换:
map[int]*[128]byte,这种情况下,bucket 中 value 占用的内存将限制在一个指针的大小(bucket 的插槽变小了),通过 delete 操作删除所有键值对,最后即使 map 的 bucket 数量无法减少,但是占用内存减少比较明显。(因为实际指向的[128]byte数组失去了引用,被回收)。

⚠️ 注意:当使用 map 时,如果 key/value 的长度超过 128 bytes,Go 将会默认使用指针存放 bucket 的键值对。
3.13 错误的值比较方式(#29)
使用逻辑运算符不可比较的数据类型:
- 切片
- map
使用逻辑运算符可比较的数据类型:
- 布尔型:比较两个 Booleans 是否相等
- 数值型:比较数值是否相等
- Strings:比较字符串是否相等
- Channels:比较两个 channel 是否通过相同的 make 创建,或者是否都是 nil
- Interfaces:比较两个接口的动态类型和动态值,或者是否都是 nil
- Pointers:比较两个指针指向的内存中的 value 是否相等,或者是否都是 nil
- 结构体和数组:整合上述可比较的数据类型,依次比较
针对不可使用逻辑运算符比较的数据类型,可以使用 Go 的反射去实现运行时的比较(递归),使用前建议阅读文档:
cust1 := customer{id: "x", operations: []float64{1.}}
cust2 := customer{id: "x", operations: []float64{1.}}
fmt.Println(reflect.DeepEqual(cust1, cust2)) // true
此时即使结构体存在不可比较的切片类型,依旧可以打印出 true。
🌟 使用反射比较需要注意的点:
- 集合为空和集合为 nil 是不同的概念(这在 #22 中提到了),需要留意。
- 反射是在运行时确定值的,因此性能很差,通常来说比 == 差两个数量级(100倍)。因此反射可以使用在单元测试中,而不是程序运行时。
自定义 compare 方法代替 reflect.DeepEqual():
func (a customer) equal(b customer) bool {
if a.id != b.id {
return false
}
if len(a.operations) != len(b.operations) {
return false
}
for i := 0; i < len(a.operations); i++ {
if a.operations[i] != b.operations[i] {
return false
}
}
return true
}
经过 benchmark 测试,使用自定义的 equal 方法比较两个切片是否相等,比使用反射快96倍。
📒 提示:针对数据类型的比较,可以选择开源的第三方的库。
小结
你已完成全书学习进度30/100,喝杯咖啡休息一下吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号