Python网络爬虫——起点小说粉丝打赏榜
(一)、选题的背景
为什么要选择此选题?
对网络小说的涉猎和认识比较有兴趣
要达到的数据分析的预期目标是什么?(10 分)
排行榜是如何构建以及小说粉丝的经济程度
从社会、经济、技术、数据来源等方面进行描述(200 字以内)
疫情期间在家办公,多数人开始在网上发表大量的文章,从2020年度网络文学发展报告可以得知网络小说的数量飞涨,是文化领域的一次突破性变化,大量的文化输入不仅解决了一部分人的停工问题,也丰富了人们在家中的娱乐活动,在增加新生代作家输入的同时也引入了许多读者的加入,通过起点阅读网阅文集团小说的数据看出在期间小说经济主要来源的打赏记录分析。
(二)、主题式网络爬虫设计方案
1.起点读书小说粉丝打赏排行的数据爬取和分析
2.主题式网络爬虫爬取的内容与数据特征分析
从起点小说排行榜中获取粉丝打赏的数据,从排行前一百的数据集中可以看出在前十名的粉丝打赏差距比较大,在第十名以后就普遍趋于一个比较平稳的状态,从而能够体现出粉丝打赏方面也出现极端现象。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
从起点网站之中爬取相关的内容和数据,并进行程序代码的分析和数据分析从而得出对粉丝打赏榜的可观分析。
(三)、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
2.Htmls 页面解析
3.节点(标签)查找方法与遍历方法

(四)、网络爬虫程序设计(60分)
1、数据爬取与采集
#-*- coding = utf-8 -*- from bs4 import BeautifulSoup #进行网页解析 import re #进行文字匹配 import urllib.request,urllib.error #制定URL,获取网页数据 import xlwt #进行excel操作 import sqlite3 #进行SQLite数据库操作 def main(): askURL("https://www.qidian.com/rank/fans/datetype2/") datalist = getData(url) savepath = ".\\苏和祥.xls" saveData(datalist,savepath) def getData(url): datalist = [] html = askURL(url) soup = BeautifulSoup(html,"html.parser") i=1 for item in soup.find_all('li'): data = [] item = str(item) # print(item) findname = re.compile(r'target="_blank" title="(.*?)">') name = re.findall(findname, item) if name == []: continue else: pm = i i=i+1 data.append(pm) name1=name[0] data.append(name1) findlink = re.compile(r'</em><a href="(.*?)" target=') link = re.findall(findlink, item)[0] data.append(link) findnum = re.compile(r'</a><i>(.*?)</i> </li>') num = re.findall(findnum, item)[0] data.append(num) datalist.append(data) return datalist def saveData(datalist,savepath): book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象 sheet = book.add_sheet('苏和祥',cell_overwrite_ok=True) #创建工作表 col = ("排名","粉丝ID","粉丝主页链接","打赏数额") for i in range(0,4): sheet.write(0,i,col[i]) #列名 for i in range(0,100): #测试 print("第%d条" %(i+1)) data = datalist[i] for j in range(0,4): sheet.write(i+1,j,data[j]) #数据 book.save(savepath) print('已输出表格!') def askURL(url): head = { "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" } request = urllib.request.Request(url, headers=head) html = "" try: response = urllib.request.urlopen(request) html = response.read().decode("utf-8") except urllib.error.URLError as e: if hasattr(e, "code"): print(e.code) if hasattr(e, "reason"): print(e.reason) return html url = "https://www.qidian.com/rank/fans/datetype2/" main() print("爬取完毕!")
输出结果:
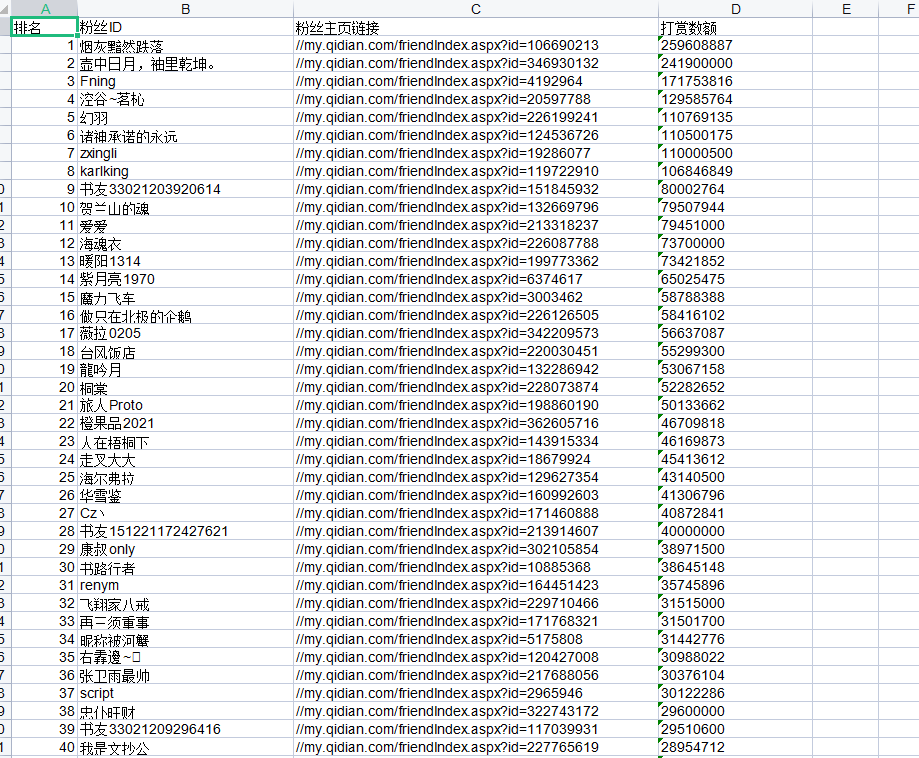
输出表格:
(2)数据可视化
#直方图
#直方图 import matplotlib.pyplot as plt import pandas as pd import numpy as np qidian_df=pd.read_excel(r'C:\Users\1\起点粉丝榜.xls') data=np.array(qidian_df['打赏数额'][0:10]) #索引 index=np.arange(1,11) #用来正常显示中文标签 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] #修改x轴字体大小为12 plt.xticks(fontsize=12) #修改y轴字体大小为12 plt.yticks(fontsize=12) print(data) print(index) #x标签 plt.xlabel('排名') #y标签 plt.ylabel('打赏数额') s = pd.Series(data, index) s.plot(kind='bar',color='g') plt.grid() plt.show()
输出结果:

#散点图、折线图
#散点图、折线图 qidian_df=pd.read_excel(r'C:\Users\1\起点粉丝榜.xls') plt.rcParams['font.sans-serif']=['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False plt.xticks(fontsize=12) plt.yticks(fontsize=12) #散点 plt.scatter(qidian_df.排名, qidian_df.打赏数额,color='r') #折线 plt.plot(qidian_df.排名, qidian_df.打赏数额,color='b') #x标签 plt.xlabel('排名') #y标签 plt.ylabel('打赏数额') plt.show()
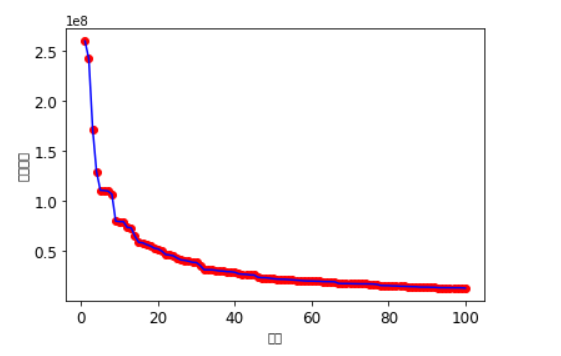
输出结果:
#回归方程
#排名与打赏数额的线性回归图 import seaborn as sns sns.regplot(qidian_df.排名,qidian_df.打赏数额) plt.xlabel('排名')#x标签 plt.ylabel('打赏数额')#y标签
输出结果:
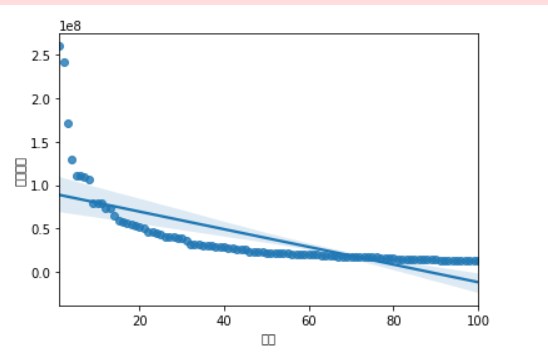
相关系数分析:
纵轴为打赏数额,横轴为排名,从回归方程可以看出前十名的打赏数额差距会比较大一些,而之后的打赏数额会逐渐趋于一个相对稳定的值,从此图也可以看出经济趋于一个相对稳定的状态。
(3)完整代码
1 #-*- coding = utf-8 -*- 2 from bs4 import BeautifulSoup 3 #进行网页解析 4 5 import re 6 #进行文字匹配 7 8 import urllib.request,urllib.error 9 #制定URL,获取网页数据 10 11 import xlwt 12 #进行excel操作 13 14 import sqlite3 15 #进行SQLite数据库操作 16 17 def main(): 18 askURL("https://www.qidian.com/rank/fans/datetype2/") 19 20 datalist = getData(url) 21 savepath = ".\\苏和祥.xls" 22 saveData(datalist,savepath) 23 24 def getData(url): 25 datalist = [] 26 27 html = askURL(url) 28 soup = BeautifulSoup(html,"html.parser") 29 i=1 30 31 for item in soup.find_all('li'): 32 data = [] 33 item = str(item) 34 # print(item) 35 36 37 38 findname = re.compile(r'target="_blank" title="(.*?)">') 39 name = re.findall(findname, item) 40 if name == []: 41 continue 42 else: 43 pm = i 44 i=i+1 45 data.append(pm) 46 name1=name[0] 47 data.append(name1) 48 findlink = re.compile(r'</em><a href="(.*?)" target=') 49 link = re.findall(findlink, item)[0] 50 data.append(link) 51 findnum = re.compile(r'</a><i>(.*?)</i> </li>') 52 num = re.findall(findnum, item)[0] 53 data.append(num) 54 datalist.append(data) 55 56 return datalist 57 58 def saveData(datalist,savepath): 59 60 book = xlwt.Workbook(encoding="utf-8",style_compression=0) 61 #创建workbook对象 62 sheet = book.add_sheet('苏和祥',cell_overwrite_ok=True) 63 64 #创建工作表 65 col = ("排名","粉丝ID","粉丝主页链接","打赏数额") 66 67 for i in range(0,4): 68 sheet.write(0,i,col[i]) #列名 69 70 for i in range(0,100): 71 72 #测试 print("第%d条" %(i+1)) 73 74 data = datalist[i] 75 for j in range(0,4): 76 sheet.write(i+1,j,data[j]) 77 #数据 78 79 book.save(savepath) 80 81 print('已输出表格!') 82 83 84 def askURL(url): 85 head = { 86 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 87 } 88 request = urllib.request.Request(url, headers=head) 89 html = "" 90 try: 91 response = urllib.request.urlopen(request) 92 html = response.read().decode("utf-8") 93 except urllib.error.URLError as e: 94 if hasattr(e, "code"): 95 print(e.code) 96 97 if hasattr(e, "reason"): 98 print(e.reason) 99 return html 100 101 102 url = "https://www.qidian.com/rank/fans/datetype2/" 103 main() 104 print("爬取完毕!") 105 #直方图 106 import matplotlib.pyplot as plt 107 108 import pandas as pd 109 110 import numpy as np 111 112 qidian_df=pd.read_excel(r'C:\Users\1\起点粉丝榜.xls') 113 data=np.array(qidian_df['打赏数额'][0:10]) 114 115 #索引 116 index=np.arange(1,11) 117 118 #用来正常显示中文标签 119 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 120 121 plt.xticks(fontsize=12)#修改x轴字体大小为12 122 123 plt.yticks(fontsize=12)#修改y轴字体大小为12 124 print(data) 125 print(index) 126 127 #x标签 128 plt.xlabel('排名') 129 #y标签 130 plt.ylabel('打赏数额') 131 132 s = pd.Series(data, index) 133 134 s.plot(kind='bar',color='g') 135 136 plt.grid() 137 138 plt.show() 139 140 141 #散点图、折线图 142 qidian_df=pd.read_excel(r'C:\Users\1\起点粉丝榜.xls') 143 144 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 145 146 plt.rcParams['axes.unicode_minus']=False 147 148 plt.xticks(fontsize=12) 149 150 plt.yticks(fontsize=12) 151 152 plt.scatter(qidian_df.排名, qidian_df.打赏数额,color='r')#散点 153 154 plt.plot(qidian_df.排名, qidian_df.打赏数额,color='b')#折线 155 156 plt.xlabel('排名')#x标签 157 158 plt.ylabel('打赏数额')#y标签 159 160 plt.show() 161 162 163 #排名与打赏数额的线性回归图 164 import seaborn as sns 165 166 sns.regplot(qidian_df.排名,qidian_df.打赏数额) 167 168 plt.xlabel('排名')#x标签 169 170 plt.ylabel('打赏数额')#y标签
(五)、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
经过对主题数据的分析与可视化,可以得到从起点小说排行榜中获取粉丝打赏的数据,从排行前一百的数据集中可以看出在前十名的粉丝打赏差距比较大,在第十名以后就普遍趋于一个比较平稳的状态,从而能够体现出粉丝打赏方面也出现极端现象,虽然起初是想爬取作者与月票榜的关系,但由于月票实时更新的不定性太大本人实力太过局限于是无法爬取到相关数据,对于粉丝打赏榜的数据爬取也可以看出得到一些想要的目的。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
完成里本次课程设计,对爬虫有了更深刻的了解,对小说写作方面来源于粉丝方面的经济来源有了更近一步的了解,在自己对Python的了解也加深了一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号