可编程网络实验室2023暑期纳新——第二次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2023summer |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2023summer/homework/12995 |
| 这个作业的目标 | 学习利用scapy处理数据包,TCP/IP协议等计算机网络知识,count-min sketch对网络流量处理 |
一、、使用scapy工具实现数据包的构造、发送和接收
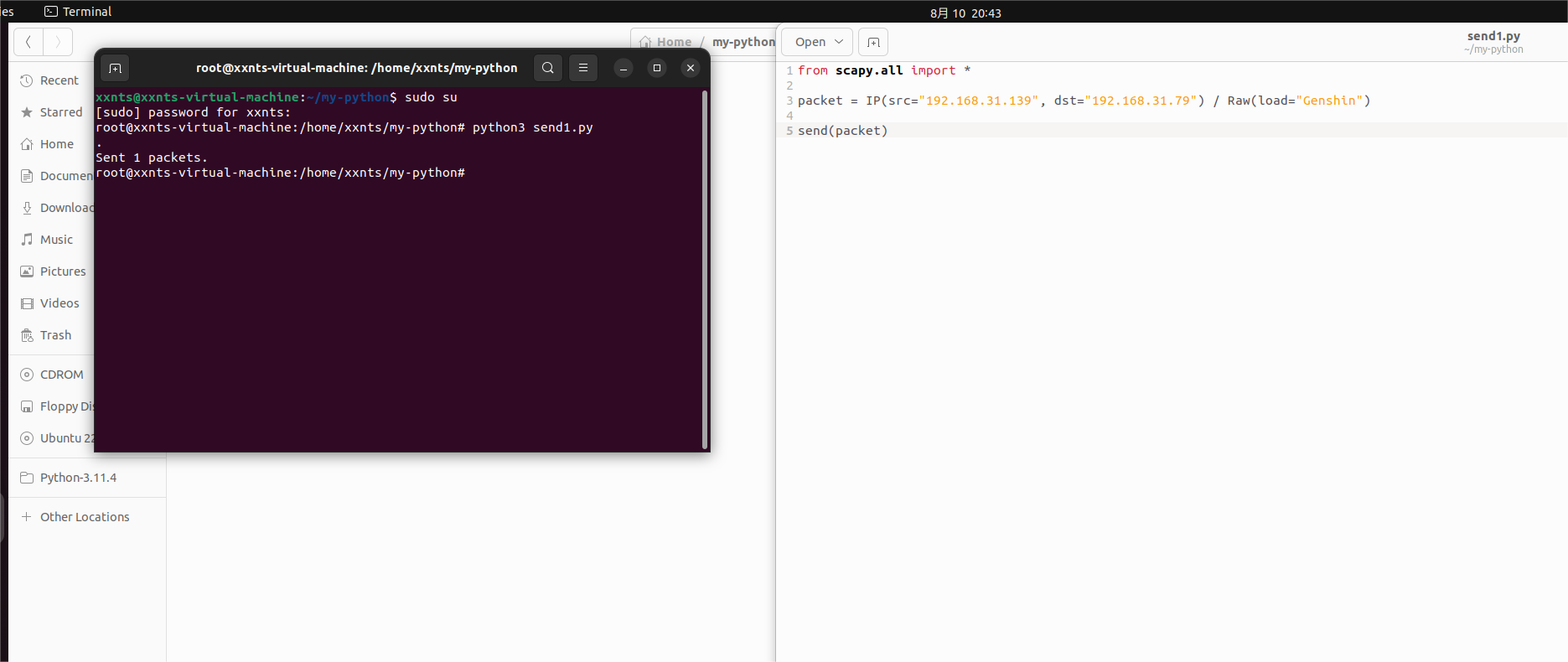
1、在虚拟机1号上构造一个数据包并发送
![]()
2、在虚拟机2号上利用sniff函数接受数据包并查看
并用wrapcap捕获数据包,将其保存
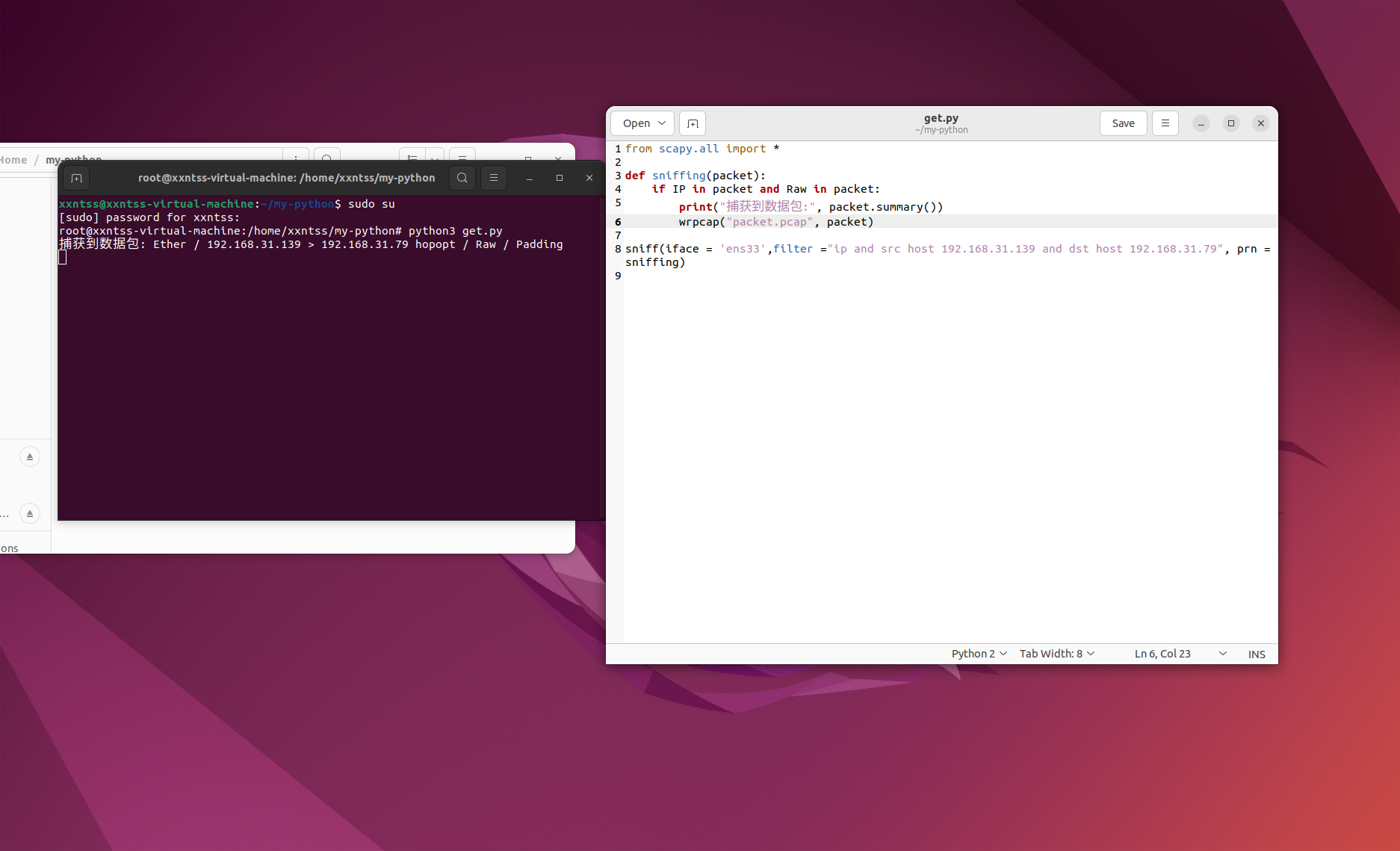
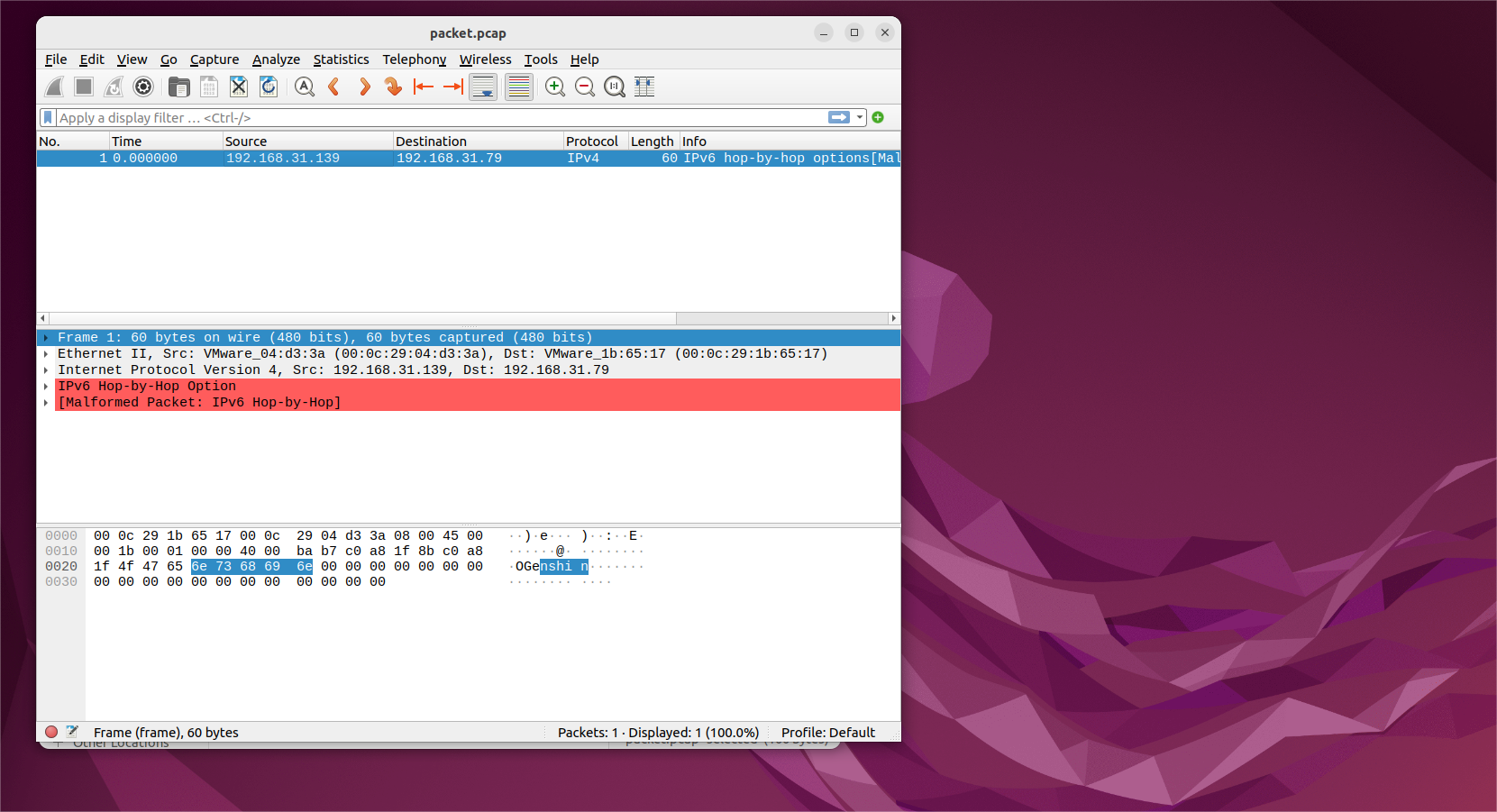
3、利用wireshark查看被捕获的数据包
二、、创建发送一个数据集并计算精准频率
利用random函数,先简单构造包含100个数据包的流不同的数据集,并发送
![]()
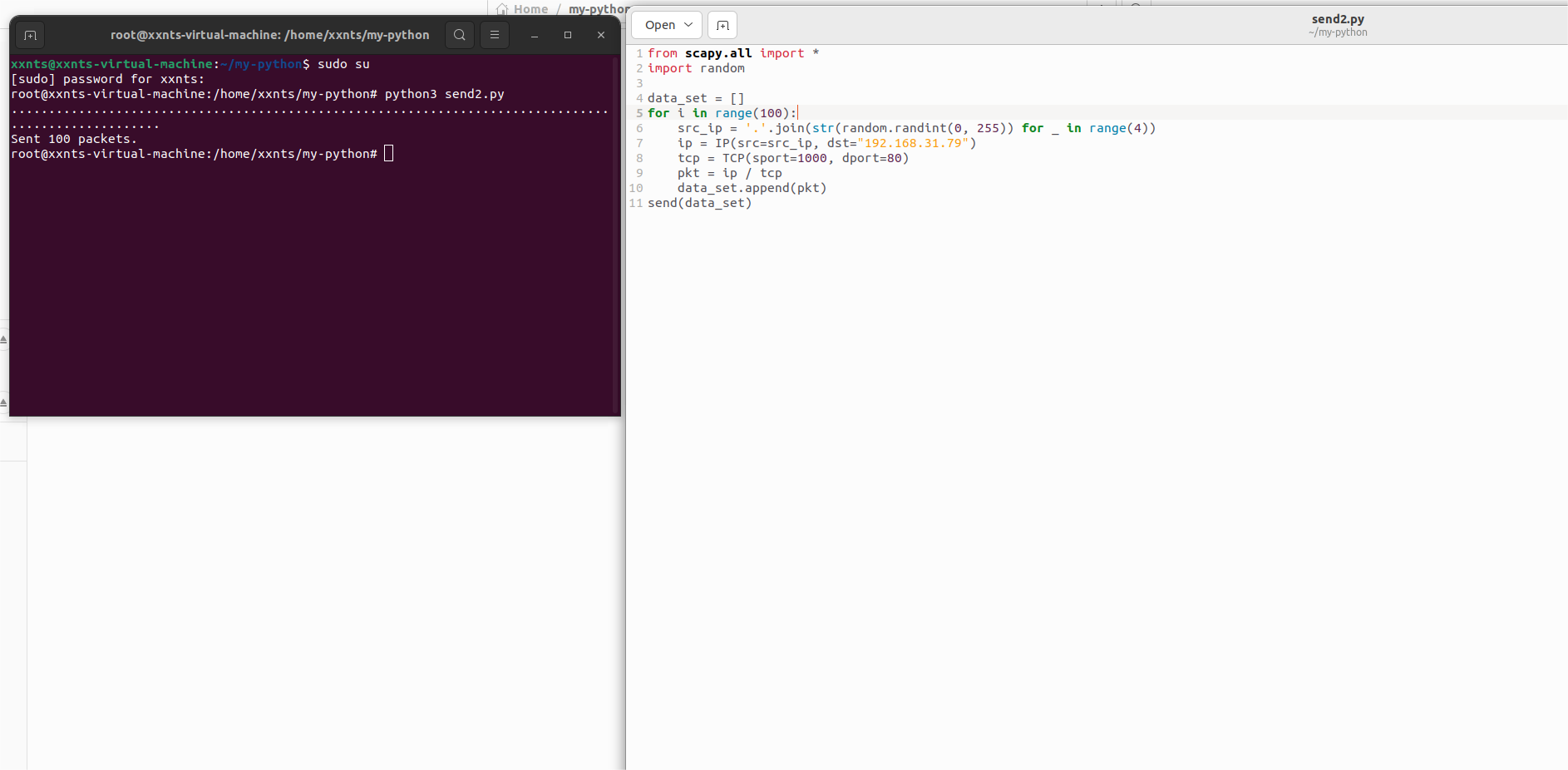
然后遍历数据集中的数据包,利用字典来统计每个流的精确频率
并将包保存下来用于后面
并

。。。丢包
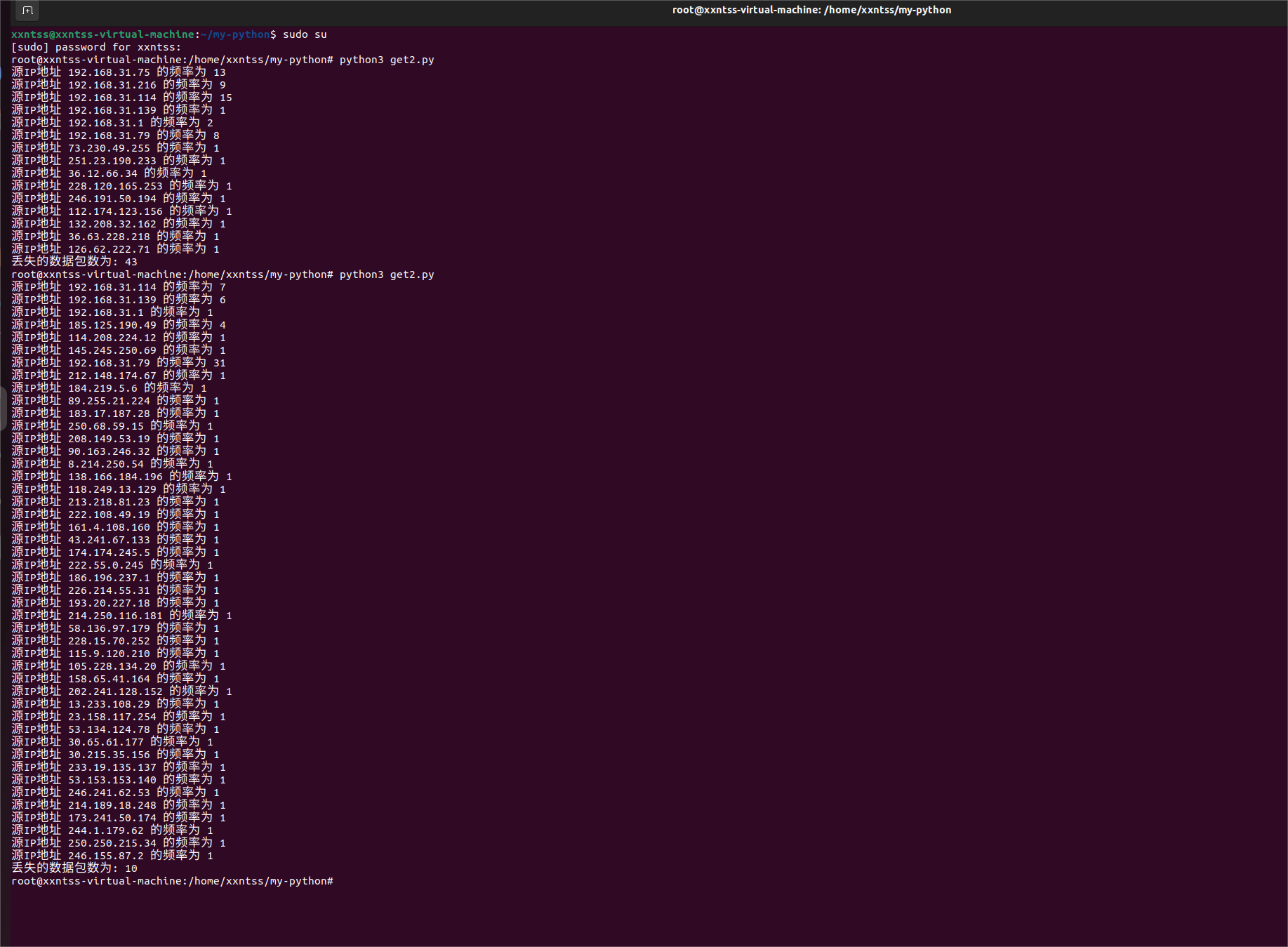
三、用count-min sketch来估算频率**
Count-min sketch 算法是一个可以用来计数的算法,在数据大小非常大时,能够通过牺牲准确性来提高效率。
没学过数据结构,先来学下哈希表和哈希函数。
哈希表,也叫散列表,根据关键字key和值value 直接进行访问的数据结构。其通过关键字key和映射函数Hash(key)(就是哈希函数)来求出对应的值value,然后把键值对映射到表中的一个位置来访问记录,加快查找速度。
哈希函数将key的对应值放到区块,而搜索关键字则要在对应的区块中搜索key,从而减少工作量。
Hash(key1) 不等于Hash(key2),则key1,key2一定不相等 而Hash(key1)=Hash(key2),则key1,key2可能相等,可能不相等,即发生哈希碰撞。
即:key1不等于key2,Hash(key1)可能等于Hash(key2)
count-min sketch是通过设置哈希函数,将具有相同value的键值对数据key存入相同的区块中,从而减少空间开销。而到网络流量估算上,则是将具有相同哈希值的网路流归为一类,并用同一个计数器计数。
count-min sketch由多个哈希函数(f1....fn)和一个二维表(m*n)构成。二维哈希表的每个区块都存有一个计数器;每个哈希函数(n个)分别对应二维表中的每一行。
当一个网络流到来时,需要经过每个哈希函数f1.....fn的处理,根据处理得到的哈希值分别存入每一行对应哈希值的计数器。
有几个哈希函数,就要计算几次,算完后,取m个计数器中的最小值作为测量最终值。
估算值只会偏大
。。。
总而言之,想象一个二维哈希表在你眼前,
有宽度width,即哈希表列数,也即是哈希表中每行的计数器个数,
和深度depth,即哈希表行数,每一行都使用不同的哈希函数,每个哈希函数将输入元素映射到哈希表的不同位置,通过对多个哈希函数计数器的叠加,可以对元素的出现次数进行估计。
在某神奇软件的帮助下也算是实现了代码吧
实现:
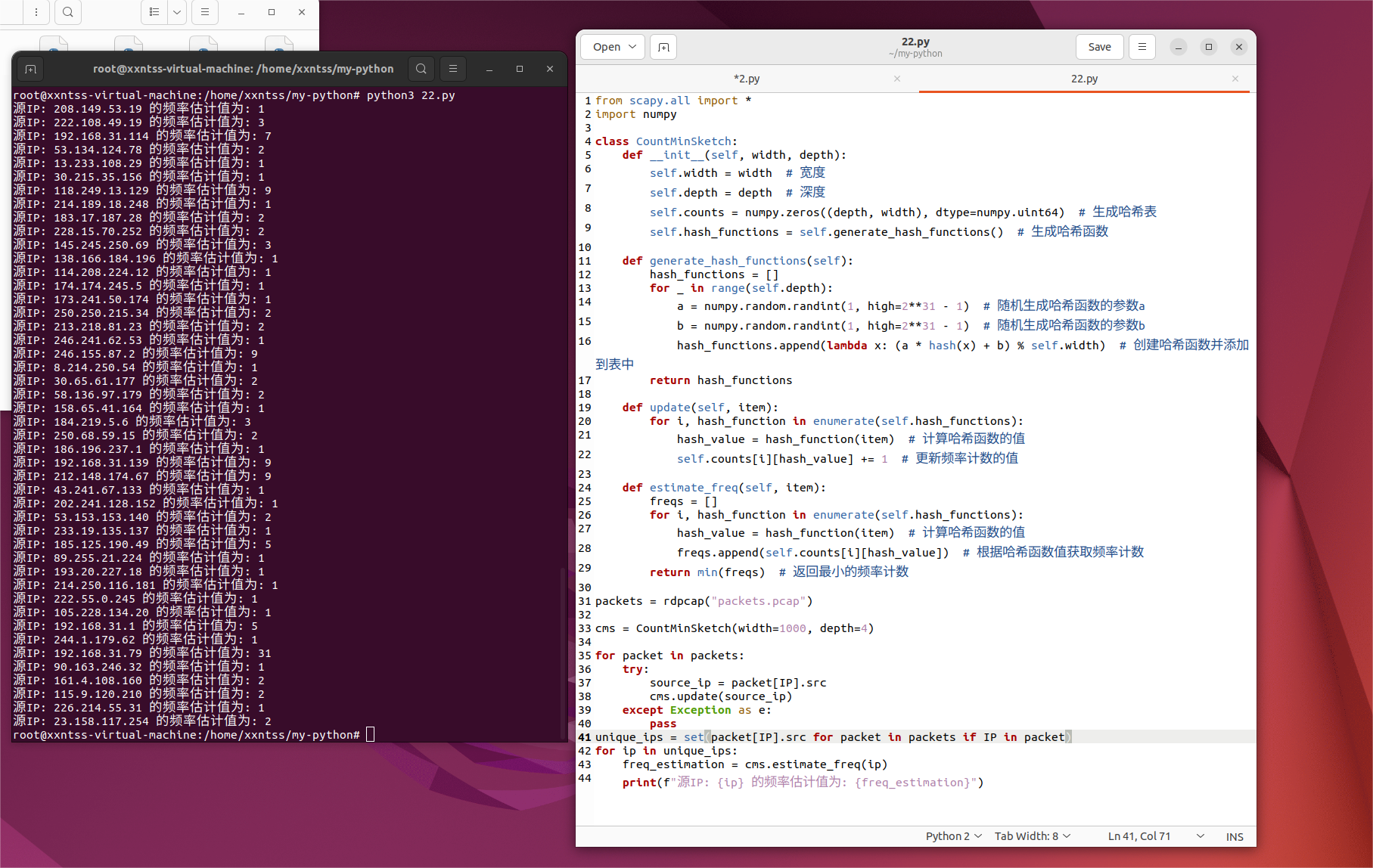
人工对比了一下上面的准确值和估计值,暂时没误差
改成10000个试一下
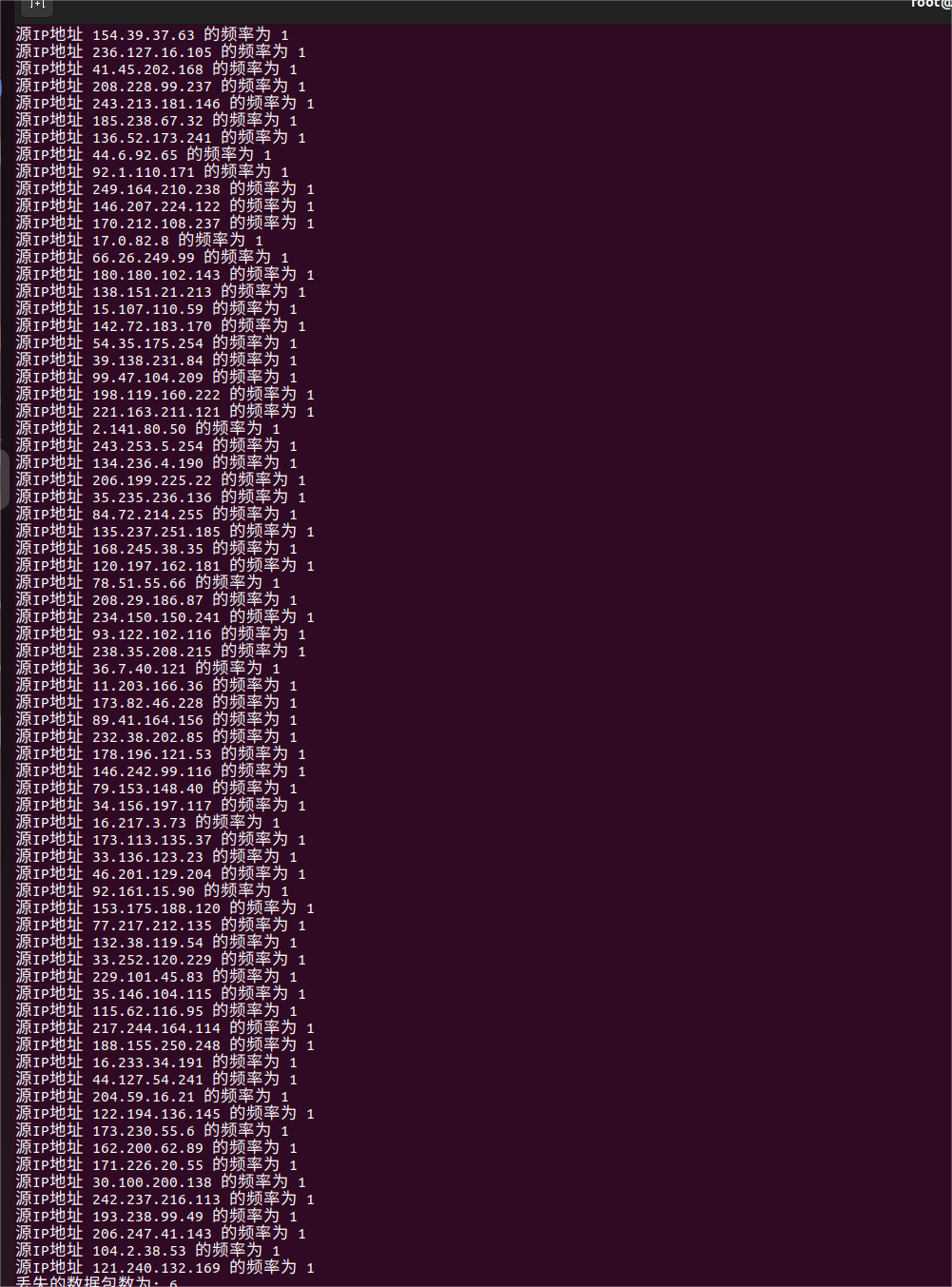
emmmmm 应该是我前面构造数据包的时候流的范围太大,255的4次方的内随机,现在反过来影响了,现在将其重写成最后一位随机。。。。。
改
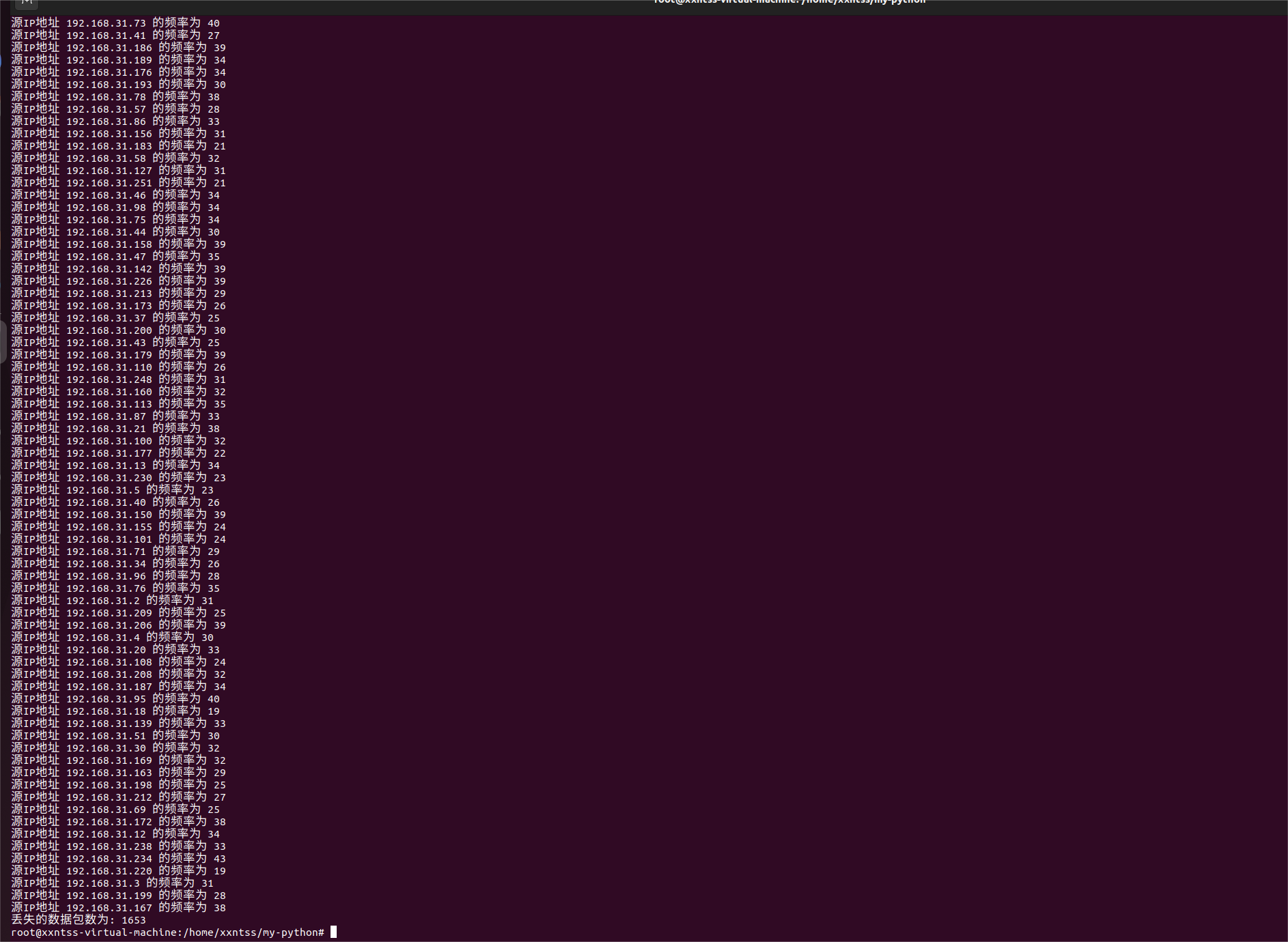
改大后存在一定的误差
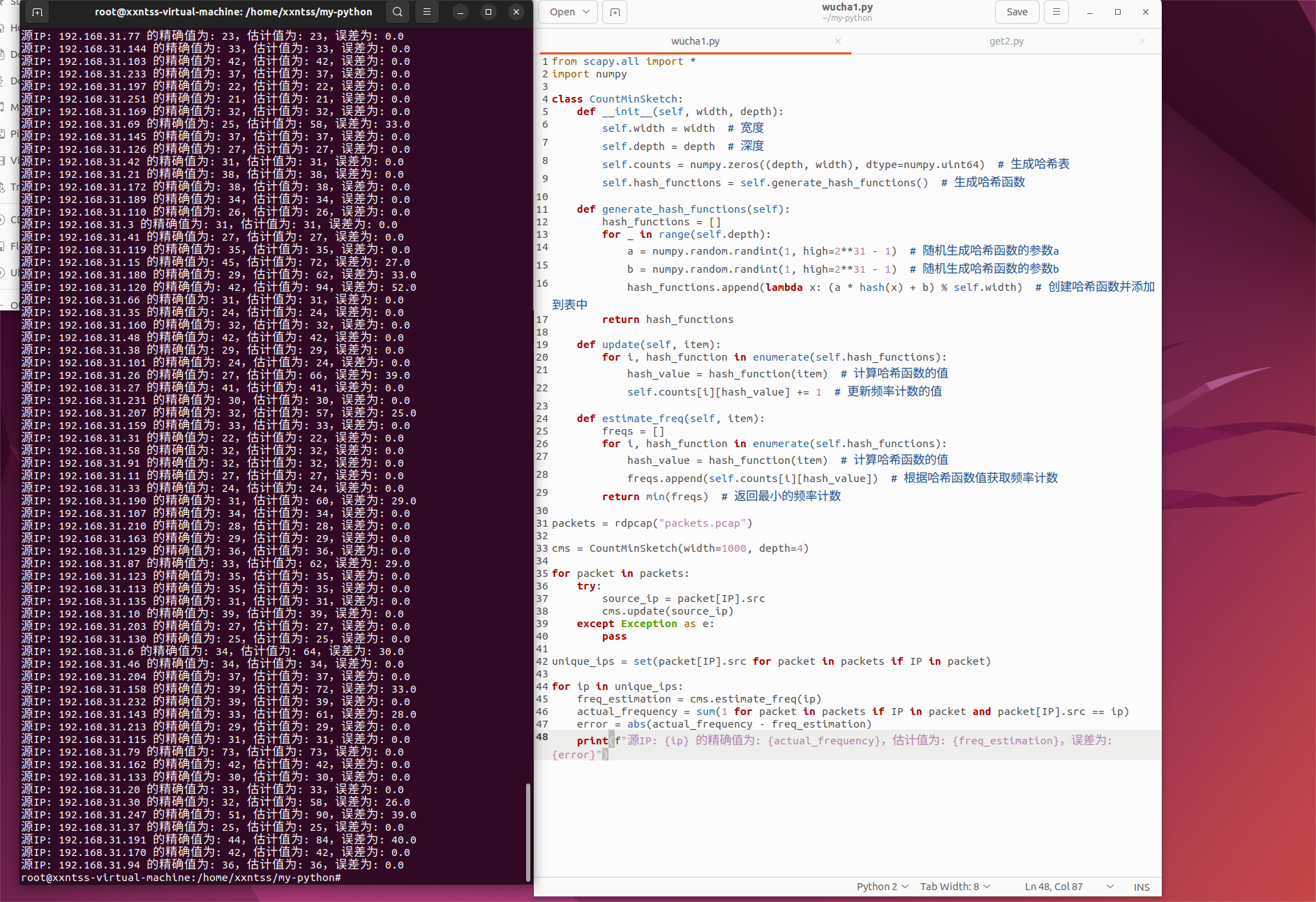
这时应该可以增大width和depth来减少误差,不过也会相应的增加占用内存和耗时
test一下 将width改为2000,depth改为10
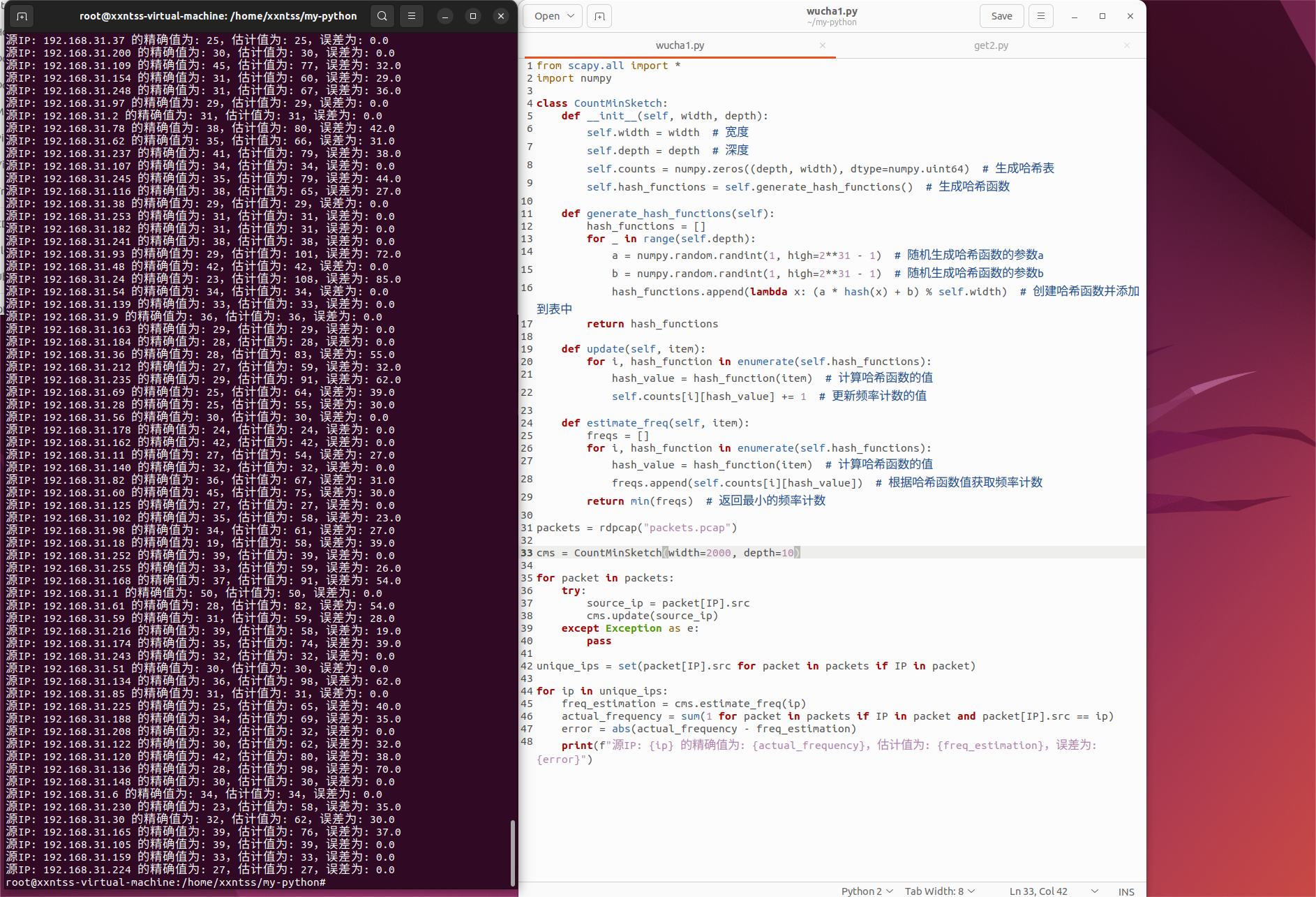
然后神奇的事情出现了,误差不仅没减小反而增大了
不知道是不是代码的问题
不懂
生活区问答题
第一问:在人生道路上,你有没有专长的技能获取的成功经验?
专长技能,人生早期的专长获取大多都是被动或者兴趣驱动,比较容易点歪技能树,比如我。
随着人长大嘛,获取专长最重要的成功要素是要发挥人的主动性,不管带有理想主义还是功利主义色彩,只要能走出舒适圈去培养提高自己,就是成功的。
其次就是要持之以恒。
第二问:你有什么技能比大多数人(70%以上)更好?
技能树点歪了能重新洗点吗
第三问:你是如何学习C语言的,与你的高超技能相比,C语言的学习有什么经验和教训?
c语言感觉是门相对枯燥、繁琐却又极其重要的语言
我是先学的c++再后面慢慢补的c语言
接触的较晚,花的时间比较少,在细节方面有些遗漏吧
c语言更需要人付出时间与耐心,但其重要性是毋庸置疑的,要多加练习才能学好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号