前菜-搜索引擎认知
1.搜索引擎是什么
搜索引擎就是帮助用户搜索到他们所需要的信息的计算机程序,换一种说法,搜索引擎把计算机里存储的信息和用户的信息需求相匹配,并把匹配的结果展示出来。
2.倒排索引VS正排索引
正排索引
正排索引是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描每个文档中字的信息找出所有包含查询关键字的文档。
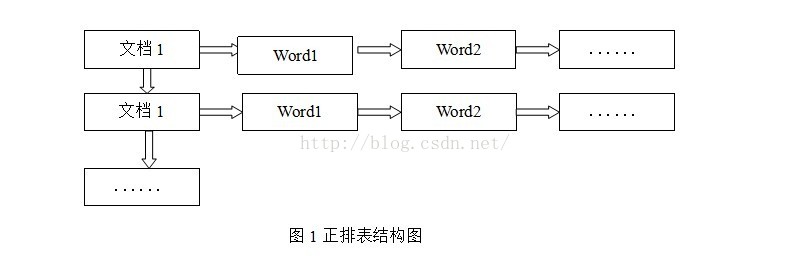
正排索引如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护,因为索引是基于文档建立的,当有新的文档加入时,直接为该文档建立一个新的索引块,挂接在原索引文件的后面。若是有文档删除,直接根据文档的ID找到对应的索引信息,直接将其删除。但是在查询的时候需要对全部文档进行扫描,这样就会使得检索的时间大大延长,效率低下。
倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的信息为出现了这个词或者字的所有文档的ID,以及这些词或字在文档中出现的位置。
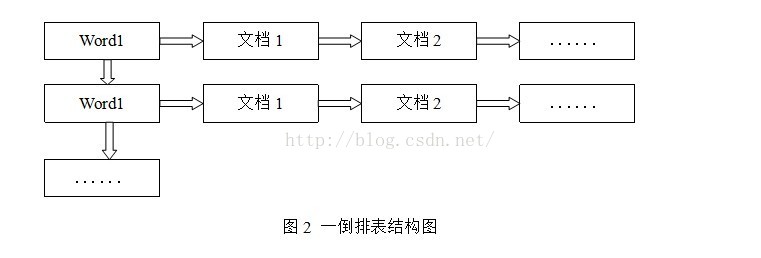
倒排表如图2所示,由于每个字或者词所对应的文档数量都在动态变化,所以倒排表的建立和维护都比较复杂,但是在查询的时候可以一次就获取到查询关键字所对应的所有文档,效率远远高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能指标,由于索引的建立是在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
3.搜索相关性模型
待续..
4.分词
分词器是专门处理分词的组件,Analyzer由三部分组成
- Character Filters(针对原始文本处理,例如去除html)
- Tokenizer(按照规则切分为单词)
- Token Filter(将切分的单词进行加工,小写,增加同义词等)
4.1 中文分词原理
根据分词的算法将一个汉字序列进行切分,等得到一个个单独的词,形成搜索关键字提供搜索服务。分词的效果对信息检索的精准率和召回率有直接的影响。
分词的算法大概可以分为四类
1.基于规则的分词方法
这种方法又叫基于字典的分词方法,按照一定的策略讲待分析的词与一个充分大的词库进行匹配。
2.基于统计的分词方法
词是稳定的组合,因为在上下文中,相邻的字出现的次数越多,越有可能形成一个词。
3.基于语义的分词方法
语义分析..自然语言处理
4.基于理解的分词方法
深度学习..让计算机模拟人对句子的理解,达到识别词的效果
4.2 中文分词开源插件
-
- ik
- ansj
- hanlp
- 结巴
5.检索质量的评价标准
- 精准率
提取出的正确信息条数 / 提取出的信息条数
- 召回率
提取出的正确信息条数 / 样本中的信息条数
有关更多精确率和召回率的资料:https://www.zhihu.com/question/19645541

 浙公网安备 33010602011771号
浙公网安备 33010602011771号