DeepFake的安装和测试(二)
接上文,在
DeepFake的安装和测试(一)
中,我们测试了deepfake的extraction部分,抽取了图片的部分人脸。现在我们研究train部分。train部分顾名思义,是训练一个模型,用以更换source和target的脸,比如很多营销号鼓吹的杨幂换朱茵或者18禁换脸视频的哪些操作。
Train部分概览
DeepFake的基本神经网络模型是比较经典的端到端模型,包含一个encoder和一个decoder。从作者给出的教程来看,encoder主要用于编码输入的人脸。decoder则是将encoder的脸部编码还原为最接近原图的脸部。非常经典的cv方法。优化方法也很传统,计算loss并简单的更新权重。

上述NN的目的是生成一个与原图非常相似的图片,其目的自然是希望换脸之后生成的脸部更加自然。而换脸操作也依赖于该模型,其做法为共享encoder。

如图所示,作者将source face和target face视为两个数据集,但这两个数据集A B使用同一个encoder进行编码(也就是将两种图片在同一向量空间表示),然后输入不同的decoder中,单个decoder只负责生成单一的图片种类,在训练过程中,数据A由deocoderA解码生成A脸,但在换脸中则由decoderB生成B脸。也是非常常规和经典的cv操作。
回到软件
参数设定
首先是一些global参数的设定。在GUI软件中设置这些参数相当简单,首先进入Settings>Configure Train Plugins:

可以看到所有的global参数
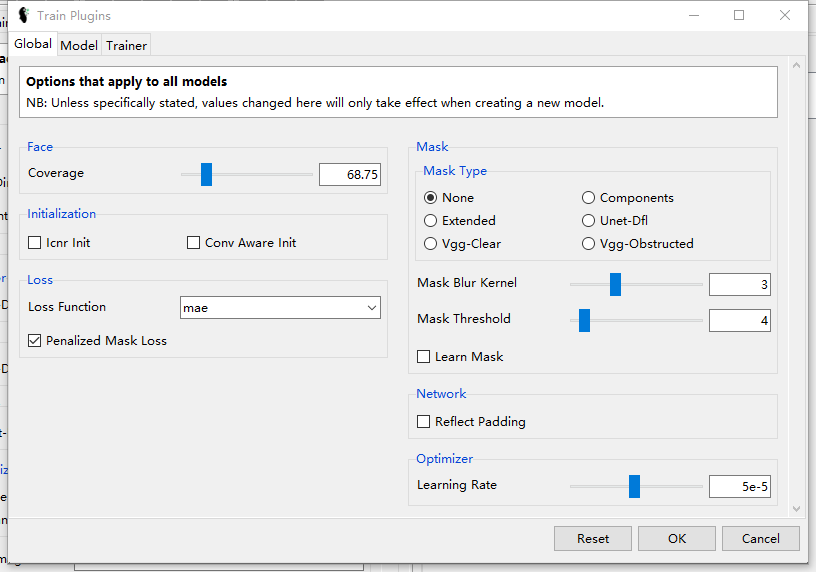
分块解释这些参数含义:
Global
- Face:输入模型的脸部选项
- Coverage:裁剪率。也就是裁剪输入脸部的多少进入训练。具体的裁剪质量如下所示:
![]()
- Mask:用以选择训练过程中mask的生成。
- Mask的任务是通过遮挡告诉模型输入的脸部哪部分是我们关注的需要swap的部分,哪部分是无关紧要的。教程给出了一个例子:


-
- 上述例子中,红色部分是算法给出的不重要的部分,也即是“masked out”部分,而中间没有红色覆盖的部分称为“masked in”,是我们关注的重要部分。
注意:如果使用mask,则需要在extraction时给出mask的相关选项并写入alignment文件中。
- initialization:模型初始化选项,给了两个选项可以一起选。这并不是一个很复杂的模型,实际运行中我们发现初始化位置对最终结果的影响并不太大。
- Network:附加网络层的选择。给了两个选项,基本上是对一些特定网络的补充。
![]()
-
Subpixel Upscaling-放大图片的方法,作者已不建议使用
-
Reflect Padding-处理DFL-SAE模型会出现灰边问题的补充方案。
-
- Loss:Loss function的选择
- Optimizer:选learing rate。常规选择,建议保持默认。

Model:对于特定模型的参数选择,建议直接保持默认。
Trainer:对于训练部分的最后的数据扩充,包括增强色差,修改分辨率等。如果不是expert建议不要乱改。
开始训练
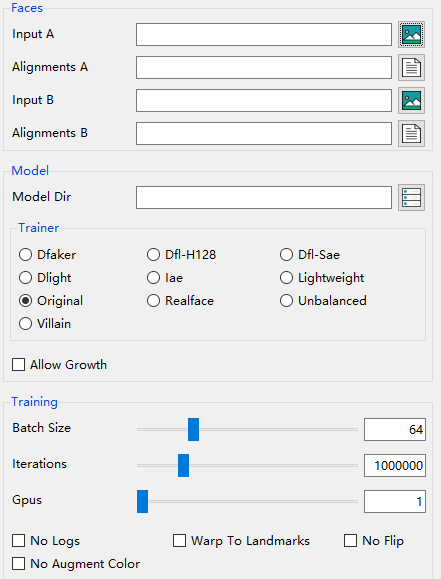
相当简单的选择,选择图片位置,选择模型类型,选择Batch Size和循环次数,都是常规参数。参数选择完可以直接开始训练,作者很贴心的给了preview界面可以实时的看到训练效果。
Convert部分
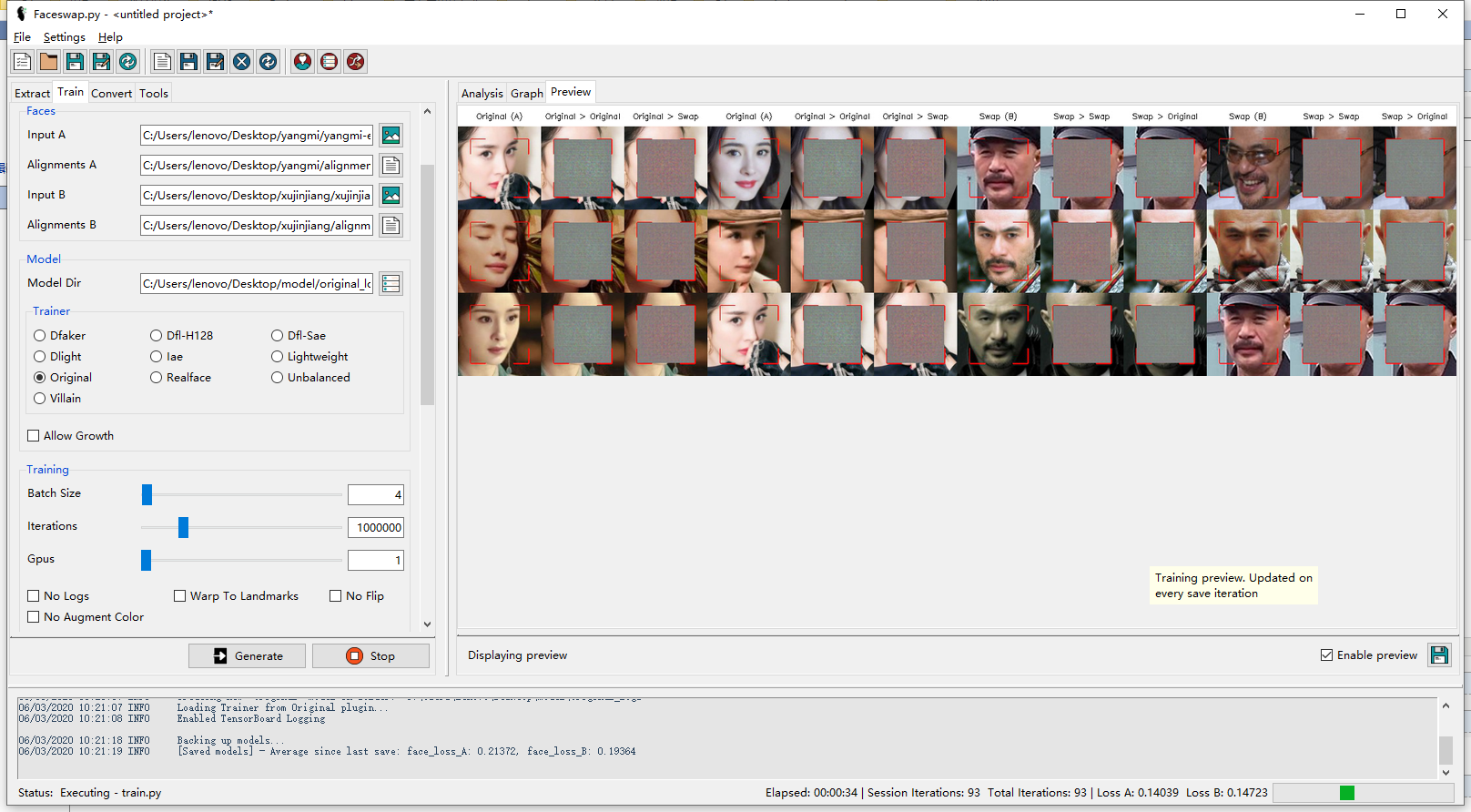
Convert部分作者没有给出详细的使用指南, 事实上也不需要给出, 实际上Convert部分就是我们深度学习中的test或者evaluation部分. 使用训练好的模型进行脸部的交换. 界面如下所示:

我们只需要给出简单的文件位置, 工具就可以自动的选取模型进行脸部转换. 前面分析Train部分代码的时候我们可以发现, 这个模型一次只训练两个简单的decoder, 这也就代表着如果一次训练得到的模型只能换一种脸. 举例来说, 我在训练中换的是杨幂和徐锦江, 那么在测试中不管我的输入脸部是杨幂, 是杨紫还是张一山, 都只会换成徐锦江的脸. 这也是DeepFake一个比较大的问题所在了, 缺少泛化.
下面是测试的示意图:




由于训练并不充分并且数据量不足, 所以会很模糊,但可以看得出来有徐锦江的样子(.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号