Redis 切片集群模式
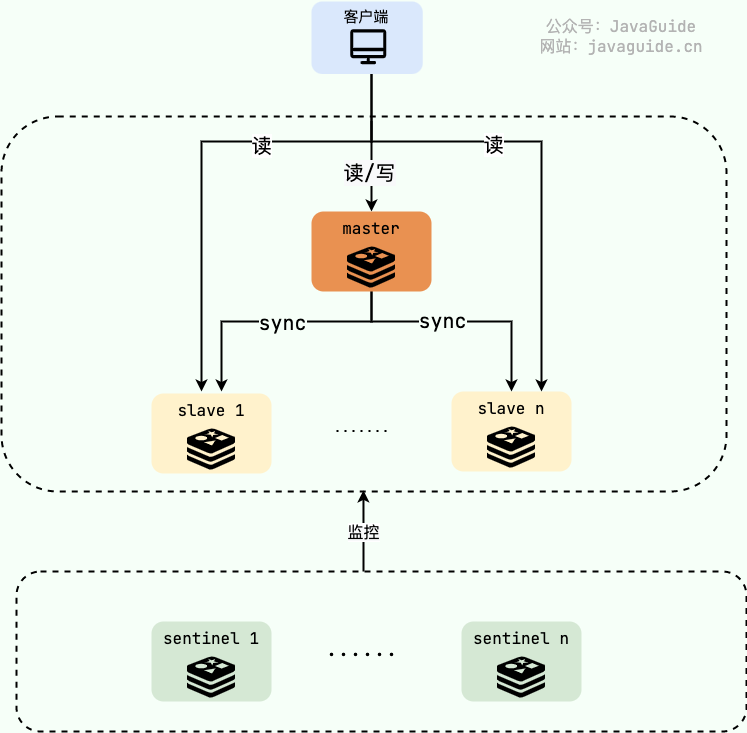
Redis主从模式和哨兵模式都实现了读负载均衡,但是依然存在单点故障和写操作无法均衡问题。Redis切片集群是部署多个主节点,每个主节点都有若干从节点,主节点之间地位平等,每个主节点存储部分数据。
| 哨兵集群 | 切片集群 |
|---|---|
 |
 |
切片集群原生支持水平横向扩展,天然支持分布式,当集群现有节点无法支持数据存储或负载压力较大的时候,可以直接通过增加机器节点解决。切片集群的动态扩缩容是其最大的优势。
分片规则
Redis集群在初始化时会创建16384个哈希槽,并将这些哈希槽均匀分配给每个主节点,对于每一个key计算CRC-16校验码对16384取模即为存储该key的哈希槽。
为什么是16384呢?Redis节点之间通过Gossip协议进行通信,定期发送心跳包,心跳包包含了节点的元数据,如果哈希槽过多,心跳消息过大,网络通信效率差
集群扩缩容
当有新的主节点加入或主节点退出时,会触发集群的扩/缩容机制,要分配/收回变动节点的哈希槽,整个数据迁移过程属于平滑迁移,扩/缩容期间可以正常对外提供服务,过程如下:
- 标记源节点的迁移槽位为MIGRATING状态,目标节点的迁移槽位为IMPORTING状态
- 数据迁移,每个key的迁移是原子性的,MIGRATE命令实现
扩/缩容期间,集群可以正常响应客户端请求,如果请求的key对应的哈希槽正处于迁移期间,则发送临时重定向消息,如果已经迁移完成,发送永久重定向。
故障检测机制
Redis切片集群采用基于Gossip协议的故障检测机制,每个节点只会与集群中的若干节点通信,久而久之达到最终一致性的状态。
- 节点A会随机地向其他若干节点发送PING消息,如果限定时间内没有收到回复,标记节点B为主观下线
- 节点A通过Gossip协议,在它后续发送给其他节点的PING/PONG消息中,附带一条节点B主观下线地信息
- 其他节点收到后,会去主动判断节点B是否下线,并通过Gossip协议进行二次传播
- 当某一个主节点收到的PONG消息中,有超过半数的主节点达成共识,都认为节点B下线,标记为客观下线
- 首先达成共识的主节点向集群广播节点B下线,所有节点同步这条消息
注意!!只有主节点有投票权,超过半数的主节点认为下线才能标记为客观下线。从流程也可以看出,从主观下线到客观下线延迟很高,因为Gossip是一个局部协议,每次只会同步给若干节点,再由这些节点去同步其他节点。
graph TD
A[节点A向节点B发送PING] --> B{在cluster-node-timeout内<br/>收到PONG回复?}
B -- 是 --> C[通信正常,状态更新]
B -- 否 --> D[节点A将节点B标记为<br/>主观下线PFAIL]
D --> E[节点A通过Gossip协议<br/>向集群传播此信息]
E --> F[其他主节点验证<br/>与节点B的连接状态]
F --> G{超过半数的主节点<br/>同意节点B主观下线?}
G -- 否 --> H[维持PFAIL状态,继续观察]
G -- 是 --> I[节点B被标记为<br/>客观下线FAIL]
I --> J[触发故障转移流程]
故障恢复机制
- 从节点收到自己的主节点下线的广播消息后,同步自身数据,标记主节点下线
- 从节点不会立刻开始选举,而是根据自身的复制偏移量计算一个延迟等待时间,复制偏移量越大,延迟时间越小(保证复制进度快的节点更快发起选举)
- 从节点延迟时间过后,纪元数+1,向其他主节点发送消息请求投票
- 所有主节点收到要求投票的消息后,会在该纪元内将选票投出,所以发起选举的时间越早,越容易获得选票
- 如果从节点在集群配置纪元内收到了超过半数主节点的同意票,它就赢得了选举,成为新的主节点,向集群广播消息,其他节点收到消息后,会更新自己的本地配置
flowchart TD
A[主节点被标记为客观下线 FAIL] --> B[从节点发起选举<br>增加纪元并投票]
B --> C{获得超过半数<br>主节点的投票?}
C -- 是 --> D[赢得选举<br>从节点执行晋升操作]
C -- 否 --> E[选举失败<br>等待超时后重新发起]
D --> F[新主节点接管<br>原主节点的哈希槽]
F --> G[新主节点广播<br>PONG消息通知集群]
G --> H[更新集群配置<br>客户端重定向到新主节点]
H --> I[恢复完成<br>集群恢复正常服务]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号