Kafka
概念
Kafka是一个高性能消息队列,美团的Mafka也是基于Kafka进行二次研发的。Kafka采用的是发布订阅模型,即消费者通过订阅Topic进行消费。整体的集群架构如下:
| Kafka集群架构 |
|---|
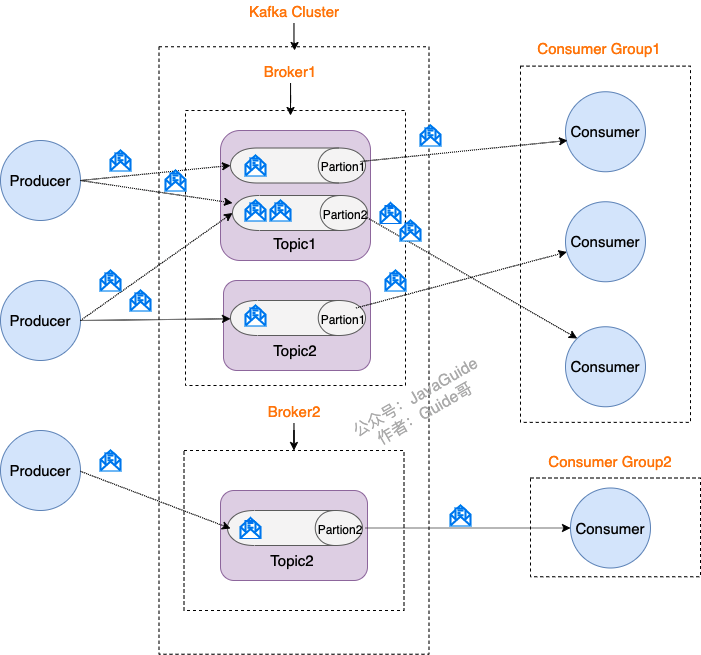 |
介绍下Kafka集群中的几个概念:
- Producer:生产者,负责向消息队列投递消息
- Consumer:消费者,负责消费消息队列的消息
- Topic:消息主题,每一个消息都有对应的topic,生产者根据topic确定投递的队列,消费者根据topic确定消费的数据
- Partation:同一个topic划分成多个Partation存储
- Broker:节点的概念,用于存储消息数据。不同的Partation存储在不同的Broker上,同一个Topic的不同Partation最好存储在不同的Broker
高可用机制 & 高性能机制
持久化机制
Kafka的消息是存储在硬盘上的,确保数据在发生故障或重启时不会丢失。
Kafka的消息持久化通过日志段实现,一个Topic的消息分布在多个Partation中,每个Partation在计算机物理结构上体现为多个日志段,Kafka采用追加写将消息写入到日志段,日志段的引入使 Kafka 能够有效管理磁盘空间,避免日志过大降低性能。
日志段也实现了过期删除压缩机制,当存活时间超过了保留时间,或者日志段大小超过阈值,会进行删除或压缩。
Kafka的持久化机制也实现了索引,为每一个日志段维护一个索引段。索引中保存了对应消息在磁盘中的索引地址,但是其属于稀疏索引,并不是为每条消息都建立索引,而是每个一定的长度建立一个索引节点。
Kafka的持久化使用了DMA+sendfile零拷贝技术,参考零拷贝,提高磁盘I/O效率
多副本机制
每个Partation在集群中都有多个副本,每个副本分布在不同的Broker上,避免单点故障。当某个Broker失效时,Kafka可以自动将领导权(Leader)转移到其他副本上,确保消息的持续可访问性。
Partation分为两种角色,Leader和Follower,Leader负责处理客户端读写请求,而Follower只负责同步Leader的数据;每个Leader都维护了一个动态ISR列表,存储了达到同步要求的Follower副本,只有ISR列表中的Follower才有资格竞选Leader。
多副本机制是Kafka高可用的基石
缓存策略
Kafka提供了缓存策略来优化网络传输带来的性能损耗。
- 生产者缓冲:生产者客户端可以通过配置buffer.memory参数设置缓冲区大小,积累消息后再批量发送,减少了网络交互次数
- 消费者缓冲:消费者批量拉取消息保存在本地顺序消费,进一步减少网络传输时间
故障检测与恢复机制
具体参见Kafka高性能 & 高可用机制
补充一点:生产者的心跳是由Broker维护的,但不需要保证生产者的高可用,维护生产者心跳是为了在生产者宕机后清理网络连接的资源;消费者心跳是由组协调者来维护的,因为需要触发rebalance。
数据重复 & 丢失
消息重复和丢失是kafka中很常见的问题,下面来展开介绍
数据重复
消息重复主要发生在生产端和消费端:
- 生产端消息重复:生产者发送的消息由于网络阻塞导致没有及时响应,触发了消息重试,两条相同的消息发送到集群,这种情况下可开启幂等性机制,每个消息会有一个消息ID,消息ID递增,对于重复的ID,消息不会落盘
- 消费端消息重复:消费端在消费消息的同时,涉及到一个offset提交的问题,如果offset在消费完消息之后提交,可能存在消息重复消费(消费完成,但提交offset时宕机,rebalance之后新的消费者再次消费这条消息),这种情况下,最好是下游接口做好幂等
幂等机制:该机制基于Producer ID (PID) 和Sequence Number (序列号) 两大核心组件实现,生产者实例在初始化时会被分配一个唯一的PID,对于每个PID和Topic分区组合,集群会维护一个递增的序列号,生产者发送消息时会附加消息序列号,以此来实现幂等
幂等机制是保证单个生产者发送的消息不重复,因此使用幂等机制依然有消息重复的风险,设想一种情况,生产者实例发送消息后,集群接收消息落盘,但是生产者在收到响应之前宕机,重启之后会重新向集群申请PID,此时该生产者会重新发送这条消息,因此幂等机制无法完全保证消息不重复,这个缺陷可以由事务弥补
数据丢失
消息丢失可能发生在生产端、Broker以及消费端三处:
- 生产端:消息异步发送,也就是acks参数为0,表示不需要等待集群响应继续发送,消息很容易丢失
- Broker:Leader宕机后,副本节点成为新的Leader,新的Leader消息并没有完全同步
- 消费端:消息提交offset之后再消费,如果消费失败,消息丢失
应对以上三种情况,对于前两种生产端和Broker消息丢失的问题,可以通过配置acks>0解决,保证至少一个Follower副本与Leader完全同步。最后一种情况则是先消费消息再提交offset,或者设置回调函数,消费失败回调失败执行逻辑
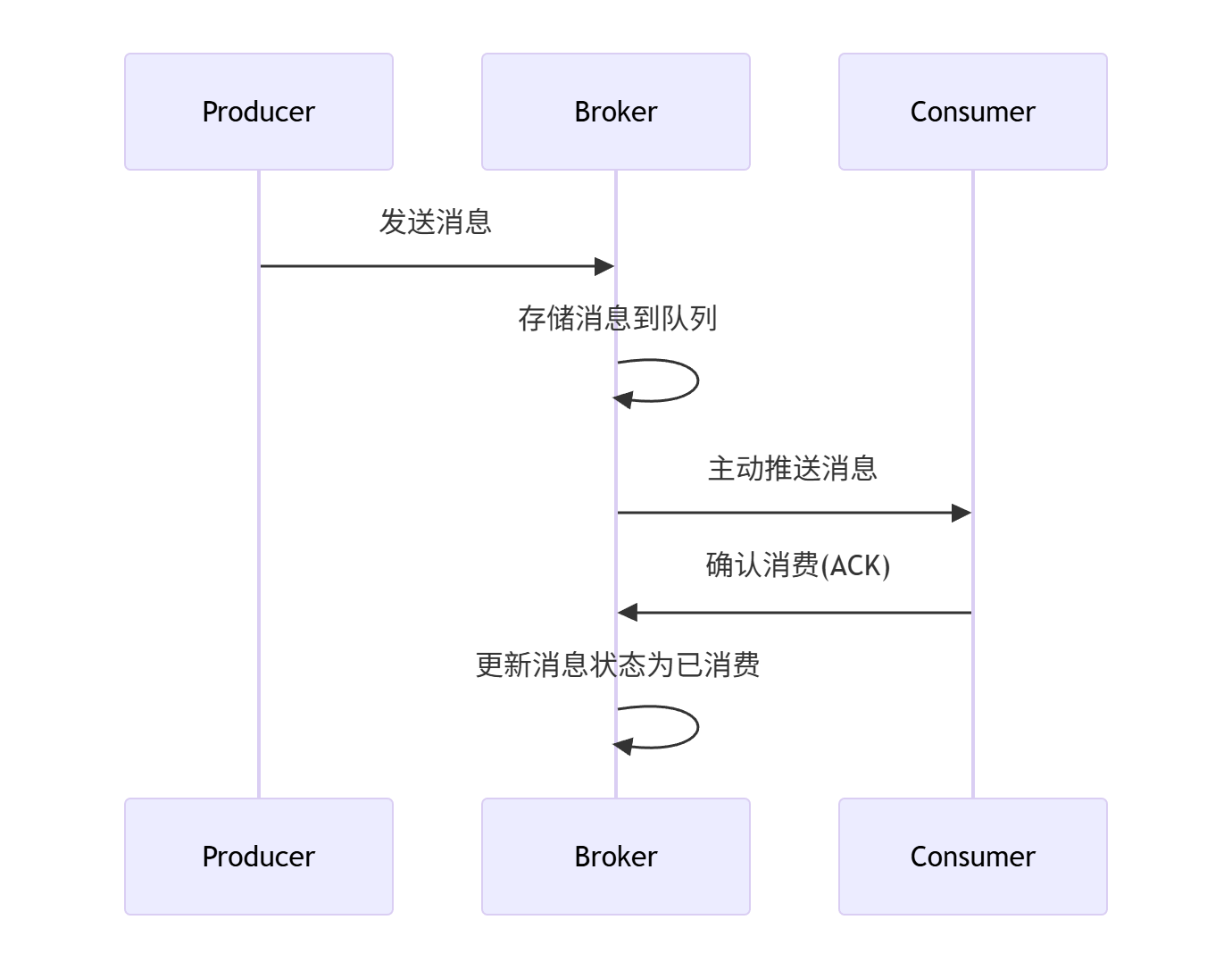
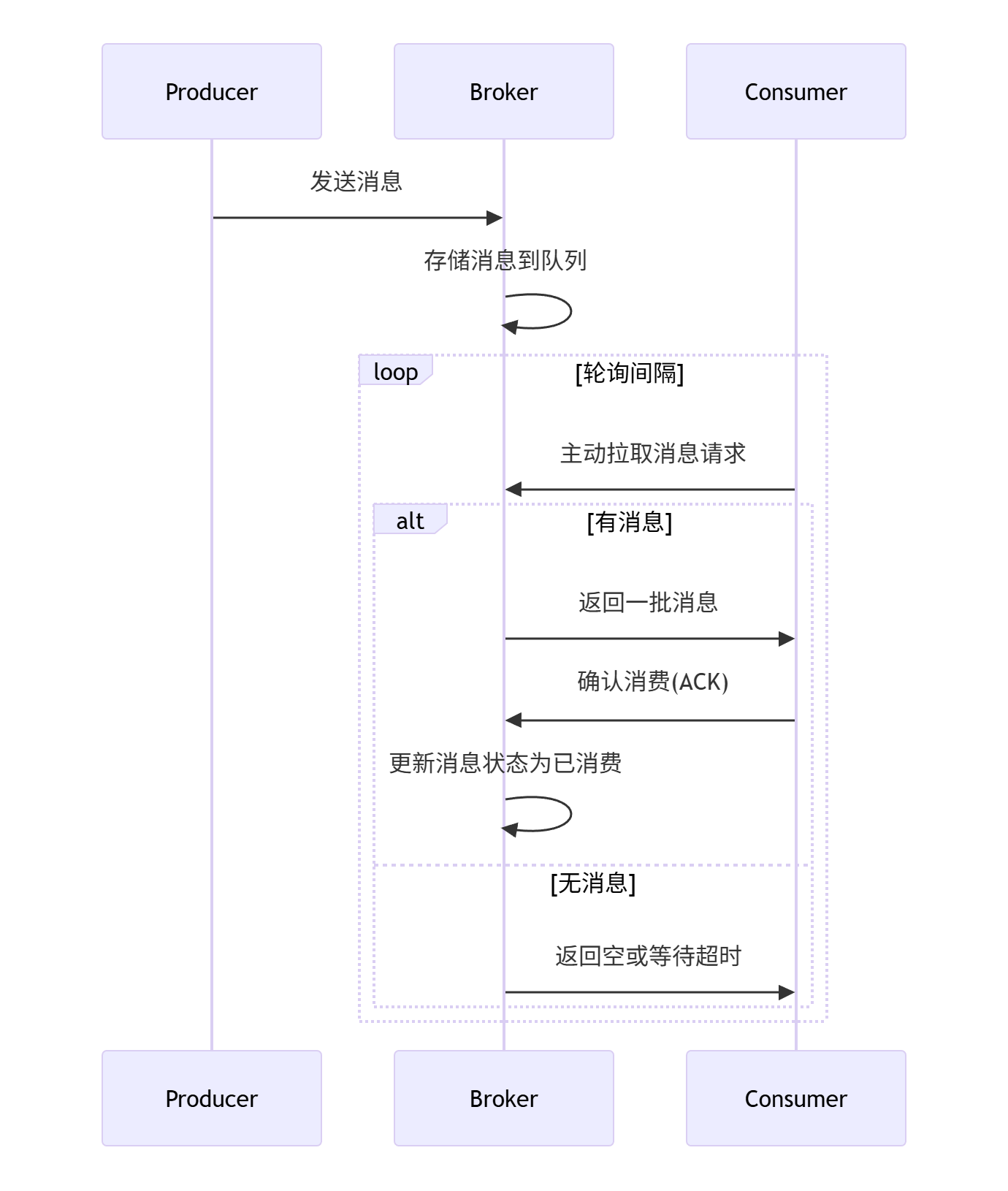
消息队列推拉模型
| 推模型 | 拉模型 |
|---|---|
! |
 |
| 特性 | 推模式 | 拉模式 |
|---|---|---|
| 控制权 | Broker主导 | Consumer主导 |
| 实时性 | 高 | 相对较低 |
| 消费者复杂度 | 简单 | 复杂 |
| 流量控制 | 服务端复杂 | 客户端可控 |
| 适用场景 | 实时通知、高吞吐 | 批处理、流量削峰 |
推模式适合实时、快消费场景,拉模式适合削峰、批处理以及节奏可控的场景。Kafka采用的是拉模式,服务端设计简单,不需要考虑消费者状态,消费速度客户端可控
Kafka采用的长连接拉模式,拉取消息时,如果消息队列为空,会阻塞等待
集群通信机制
集群内部、集群与生产者、消费者之间的通信基于Kafka自定义的TCP二进制协议。
集群与生产者的通信机制
- 在连接建立阶段,生产者启动时会配置集群至少一个Bootstrap Broker的地址,启动时会连接到其中的一个Broker,将集群元数据返回给生产者,任何Bootstrap Broker都能响应元数据请求,因为任何Broker都缓存了完整的元数据
- 生产者根据返回的元数据直连真正的Leader Broker,生产者与Leader Broker建立长连接,后续基于Kafka自定义的TCP二进制协议进行通信
Bootstrap Broker 仅供Kafka客户端(Producer、Consumer)首次连接集群时使用
集群与消费者的通信机制
- 在连接建立阶段,消费者配置集群至少一个Bootstrap Broker的地址,启动时会连接到其中的一个Broker获取完整的元数据
- 消费者根据元数据中的信息,建立与自己的消费者组Group Coordinator的心跳连接并在之后维持心跳消息
- Group Coordinator发现新的消费者后,触发Rebalance机制
- 消费者根据Leader Consumer的分配策略直连自己的Broker,建立长连接用于后续消费
集群内部通信
集群内部的通信主要分为两部分:
- 心跳检测
- 数据同步
数据同步和消费者类似,副本partation会主动拉取leader partation的数据,和消费者拉取消息用的是同一个协议,但Follower使用特殊的Replica ID(通常是负数,如 -1)标识自己是副本同步请求,而非普通消费
心跳检测参考高可用 & 高性能部分的心跳检测以及故障恢复机制
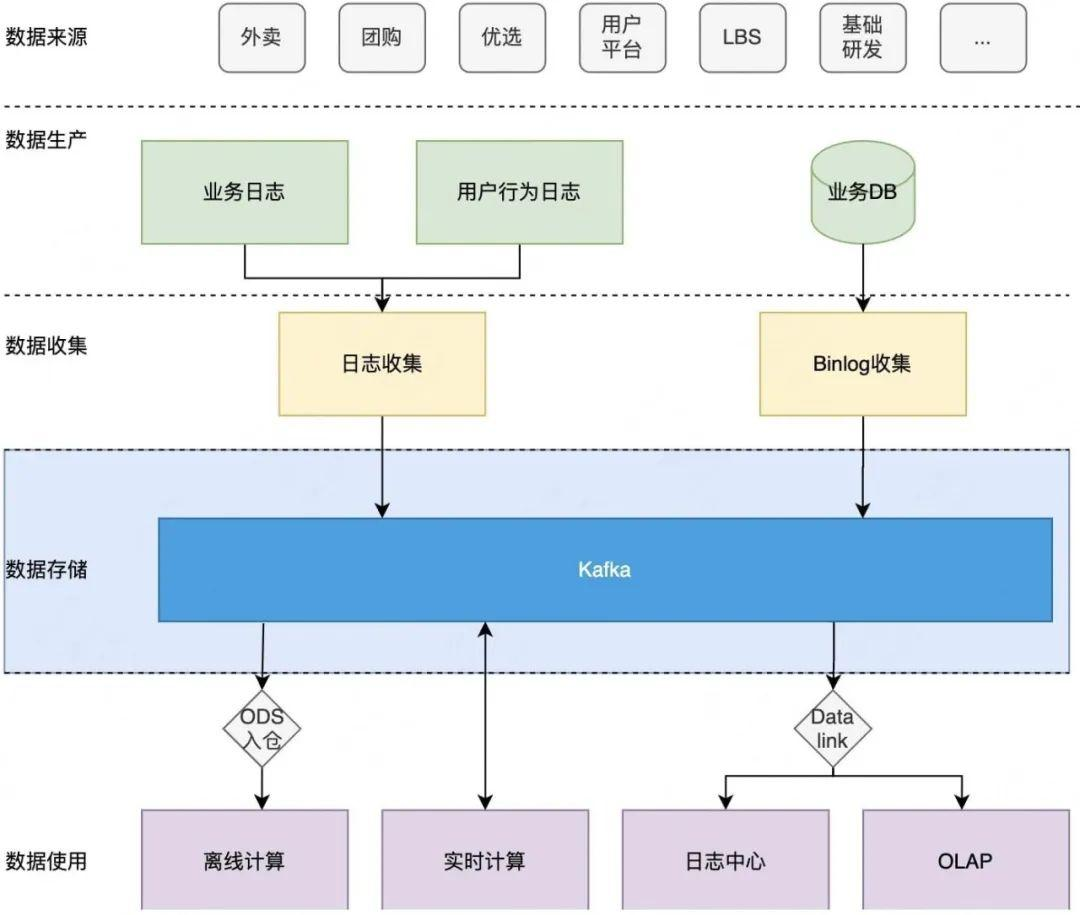
Mafka
美团在Kafka基础上进行了二次研发,诞生了Mafka,在美团实践中Kafka的实战架构如下:
| 美团Kafka |
|---|
 |
慢节点读写问题
在实践中,暴露的主要问题如下:
- 慢节点影响整体读写问题,读写延迟TP99大于300ms的Broker叫做慢节点,导致慢节点产生的原因如下:
- 集群负载不均衡会产生局部热点,导致虽然整个集群硬盘空间很充裕,但某个节点的硬盘即将写满
- PageCache容量,如果消费的数据已经从PageCache刷到了硬盘,就会触发慢速的磁盘访问
- Kafka消费者采用单线程事件循环模型,当Consumer消费的多个分区处于同一Broker时和处于不同Broker时,TP90相差很大。
针对磁盘热点问题,引入了基于空闲磁盘优先的分区迁移计划,整体架构如下
| 分区迁移 |
|---|
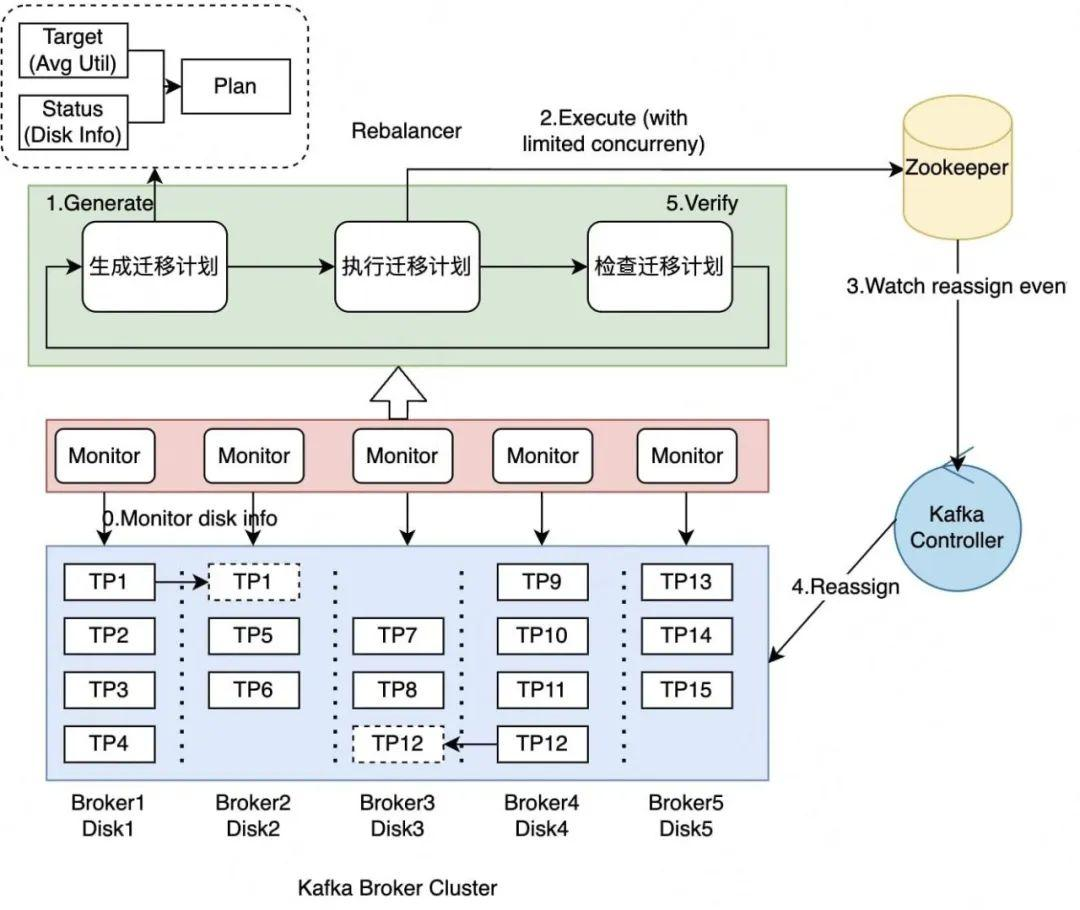 |
- Kafka Monitor负责上报磁盘使用率
- Rebalancer收集Kafka Monitor上报的数据,持续生成当前最佳的分区迁移计划,并将计划上报给Kafka Controller
- Kafka Controller向整个Kafka Broker集群提交Reassign事件,Broker负责执行分区迁移,而Controller负责监控迁移进度
迁移效率可能会很慢,采用了流水线加速技术加速迁移
针对Page Cache容量不足的问题,引入混合存储架构:
基于Kafka的应用层去实现,Kafka的数据按照时间维度存储在不同设备上,对于近实时数据直接放在SSD上,针对较为久远的数据直接放在HDD上,然后Leader直接根据Offset从对应设备读取数据。这种方案的优势是它的缓存策略充分考虑了Kafka的读写特性,确保近实时的数据消费请求全部落在SSD上,保证这部分请求处理的低延迟,同时从HDD读取的数据不回刷到SSD防止缓存污染
针对消费者线程模型的缺陷,改进如下:
引入异步拉取线程。异步拉取线程会及时地拉取就绪的数据,而且原生Kafka并没有限制同时拉取的分区数,需要单独做限速
Kafka的消费者线程模型是,单线程事件循环模型,当一个消费者同时消费多个分区时,拉取消息只要存在消息,就立即返回,后到来的消息会暂时积压在队列,等待下次拉取。Mafka的改进是引入异步线程及时地拉取就绪的消息,避免消息积压
事务消息
和Kafka的原生事务不同,Mafka的事务消息是本地任务+消息投放的原子性,而Kafka原生事务是多个消息投放的原子性。
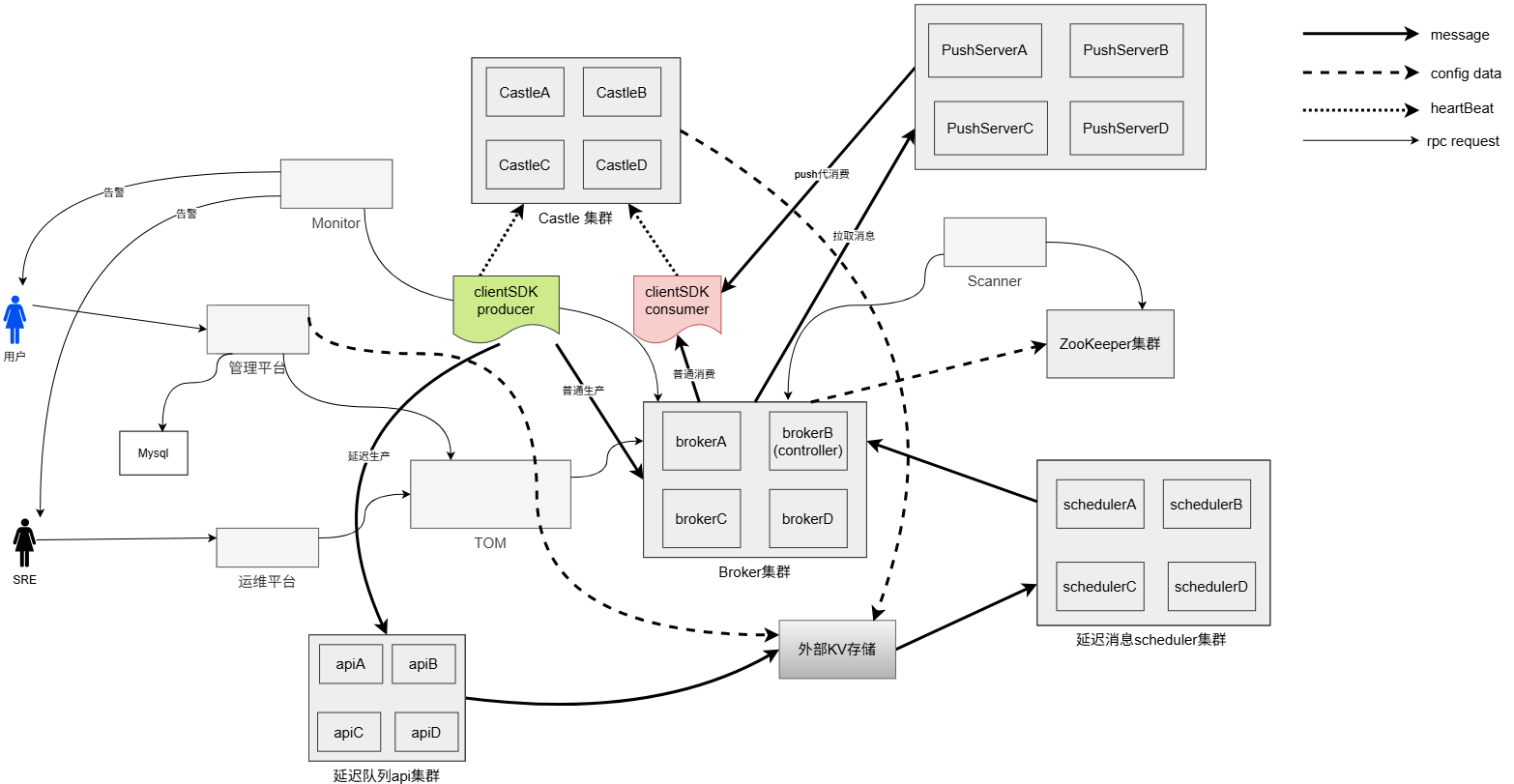
延迟消息
| 延迟消息 |
|---|
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号