Raft协议
总体思想
Raft协议是CAP理论中的CP协议,也就是分布式系统下的一个强一致性协议。Raft协议的基本思想是一个分布式系统存在Leader节点和Follower节点,客户端的所有请求全部由Leader处理,以此来保证一致性,Follower只负责同步Leader的数据,并在Leader故障时进行选主。通过中心化的领导节点来简化一致性保证
Raft算法的详细介绍参考Raft协议,这里做简单介绍。
算法思想
一个Raft协议集群包含三种角色:
- Leader:负责处理客户端请求,并定期向其他节点发送心跳消息
- Candidate:Leader选举过程产生的临时角色,由 Follower 转化而来,能够参与竞选Leader
- Follower:除Leader外的其他节点,接收Leader心跳,可以对Candidate投票
Leader节点负责处理客户端的所有请求,那如果Leader宕机怎么办呢?那自然是重新选取Leader,自然延申出来两个问题:如何发现Leader宕机以及发现Leader宕机后,怎么重新选取Leader呢?
如何发现Leader宕机
Leader定期向所有Follower发送心跳消息,若Follower在超时时间(超时时间由Follower自己控制,完全随机)内未收到Leader心跳消息,则认为Leader宕机。Leader在这个过程中只负责定期发起心跳
为什么超时时间由Follower自己控制且完全随机呢?
- Follower的超时时间在一次选举结束后重新生成,不能是固定的超时时间,否则Leader宕机后,每次新选举出的Leader都是超时时间最短的Follower,会造成其中两个Follower循环成为Leader,负载不均衡(A和B的超时时间最短,A宕机,B成为Leader,在B宕机之前,A恢复,B宕机后,A又成为Leader,循环往复)
- 极端情况下,如果所有Follower的超时时间相同,那么他们会同时发现Leader宕机,全部都给自己投票成为新的Leader,导致没有任何一个节点获得超过半数选票
- 另一种极端场景,生成的随机超时时间也相同,也会出现无法获得半数选票,选举失败的情况。每次Follower角色转换时,重新生成超时时间,这样即使第一轮选举失败,第二轮失败的可能性非常小。
如何选取新的Leader
- Follower在超时时间内未收到Leader的心跳消息,认定Leader宕机,自身转化为Candidate
- Candidate首先向自己投票,然后向其他Follower发起投票,一个Follower一个任期内只能投出一票
- 优先获得超过半数选票的Candidate成为新的Leader
注意,成为Candidate是有条件的,只有包含所有已提交日志的节点才能成为Candidate
任期号机制
任期号机制是避免集群脑裂以及保证选举唯一性和安全性的最关键保障,下面展开介绍
脑裂问题: 假设一种情况,Leader发送心跳消息,由于网络阻塞导致超过了Follower的超时时间,触发了选举新的Leader的过程,出现了脑裂。但是这个脑裂是可以被解决的,原Leader发送的心跳消息被Follower接收到后,Follower会回复告知其新的任期号,原Leader收到回复后,会主动降级成为Follower,所以不存在脑裂问题。
投票唯一性: 任期号机制保证了Follower投票的唯一性,即一个任期内只能投递一张选票
选举安全性: 新的Leader需要拥有完整的日志段,当一个Follower收到Candidate要求投票的消息后,首先检查任期号是否比自己大,任期号高于自己的话,再看日志的索引偏移量,偏移量越大,说明数据越完整。只有任期号和日志偏移量均高于自己,才会给出自己的选票
读写一致性保证
读请求很简单,通过Leader读取最新的数据。主要是写请求如何做到一致。
| 客户端请求处理 |
|---|
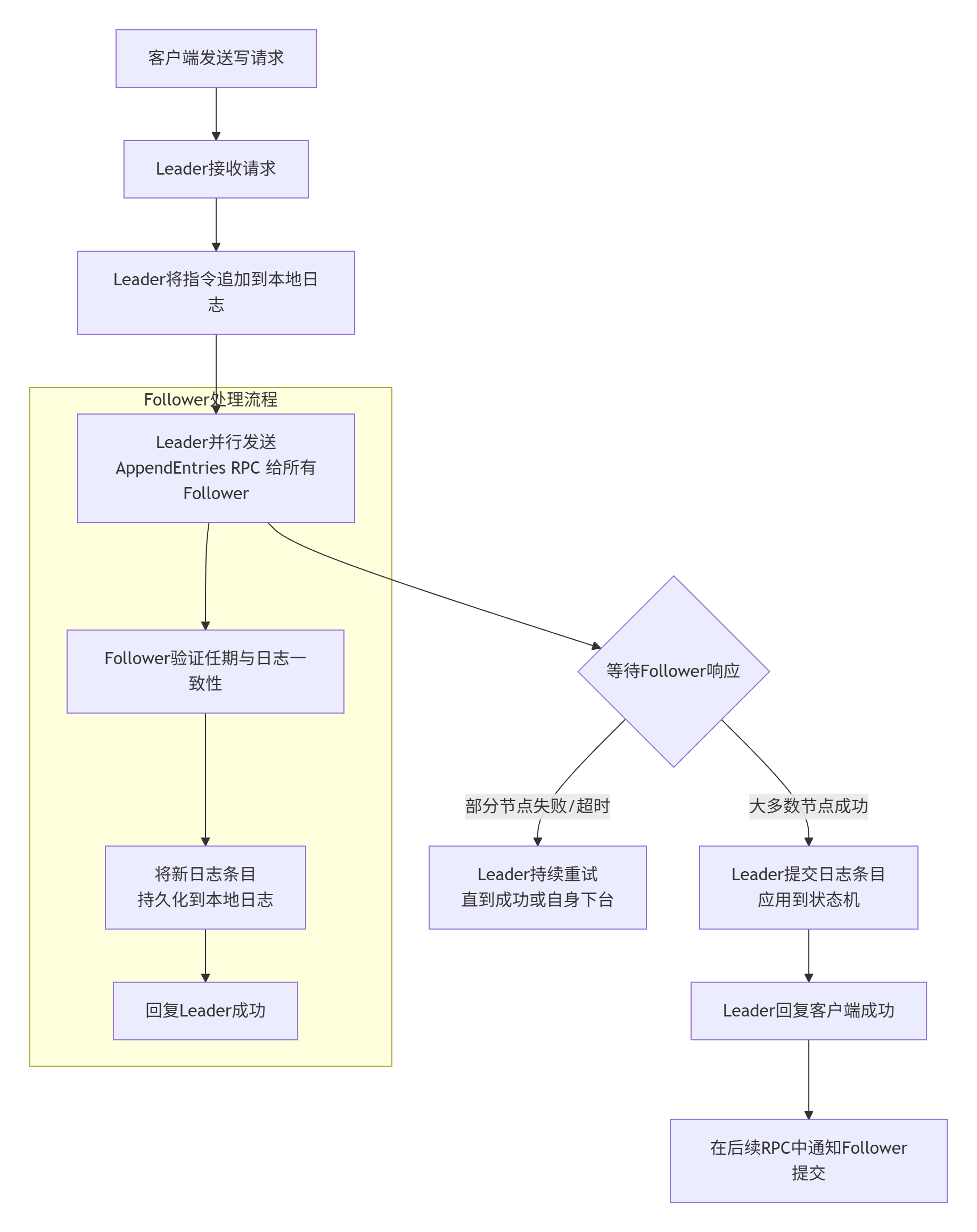 |
- Leader收到请求后,不会立即修改本地数据。而是先将这个命令作为一个新的日志条目追加到自己的本地日志中,该日志是未提交的,对客户端不可见
- Leader并行地向所有Follower节点发送这条新的日志
- Follower将新的日志条目追加到自己的本地日志中,回复Leader一个成功的响应
- Leader会持续等待,直到它收到超过半数节点(包括它自己)的成功响应,标记日志为提交状态,执行该命令,响应客户端
- Leader会异步通知Follower执行该命令
这种先写日志再执行命令的机制叫做WAL(Write-Ahead-Logging)机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号