SciKit-Learn & TensorFlow 学习笔记(三)
2018-07-29 14:37 雄风狂飙 阅读(442) 评论(0) 收藏 举报从头至尾创建一个机器学习项目
1.整体步骤
1). 问题概览,从整体把握需要解决的问题,宏观把控,提出整体解决思路
2).获取数据
3).发现数据,观察数据,进行可视化
4).为机器学习算法准备数据,进行数据预处理、清洗工作
5).选择模型
6).为模型调参
7).呈现结果
8).发布、检测、维护
2.环境准备
前面已经写过python,jupyter 的安装和使用,虚拟环境的创建等主题的文章。
可以参考 https://www.cnblogs.com/XiongWinds/articles/8677419.html 查看
3.下载数据
废话不说,详见代码,这里注释了“fetch_housing_data()”,是因为我已经下载过这个文件了,没有必要再次下载了,首次执行的时候,是需要放开注释的。
import os
import tarfile
from six.moves import urllib
import pandas as pd
import matplotlib.pyplot as plt
DOWNLOAD_ROOT = "http://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL,housing_path=HOUSING_PATH):
print("要获取的路径:"+housing_url)
if not os.path.isdir(housing_path):
print(housing_path)
os.makedirs(housing_path)
else:
print("exists file path")
print(housing_path)
tgz_path = os.path.join(housing_path,"housing.tgz")
urllib.request.urlretrieve(housing_url,tgz_path)
print("数据已经获取")
housing_tgz=tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
print("数据已解压")
housing_tgz.close()
print("done")
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path,"housing.csv")
print("要打开的数据文件为"+housing_path+"housing.csv")
return pd.read_csv(csv_path)
#fetch_housing_data()
housing_data = load_housing_data()
housing_data.head(3)
4.瞄一眼数据
housing_data.info()
housing_data.describe()
再瞄一眼
import matplotlib.pyplot as plt def show_hist(data): housing_data.hist(bins=50,figsize=(20,15)) plt.show() show_hist(data=housing_data)

横轴是数据的具体值,纵轴是同一中数据的个数。
5.创建测试集
方法一:
import numpy as np def split_train_test(data,test_ratio): shuffled_indices = np.random.permutation(len(data)) print(len(shuffled_indices)) print(shuffled_indices) test_set_size = int(len(data)*test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices],data.iloc[test_indices] train_data,test_data = split_train_test(housing_data,0.2) print("train length==",len(train_data),"test_length==",len(test_data)) #show_hist(train_data) #show_hist(test_data) housing_data["income_cat"]=np.ceil(housing_data["median_income"]/1.5) housing_data["income_cat"].where(housing_data["income_cat"] < 5, 5.0 ,inplace = True) income_cat=housing_data["income_cat"] income_cat.value_counts()/len(income_cat)
0.2是指80%作为训练集,20%的测试集
方法二:
from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits = 1,test_size = 0.2 , random_state = 42) for train_index , test_index in split.split(housing_data,housing_data["income_cat"]): strat_train_set = housing_data.loc[train_index] strat_test_set = housing_data.loc[test_index] house_data = strat_train_set.copy() house_data = strat_train_set.drop("median_house_value",axis=1) house_labels = strat_train_set["median_house_value"].copy() house_num = house_data.drop("ocean_proximity",axis=1)
6.数据可视化
因为,数据中有经度和维度,那就绘制出来看看地图吧,第一张是最简单的,第二张中的alpha是透明度,这样就可以显示密集度了,第三张加入了更多的维度,气泡大小表示人口的多少,颜色轻淡表示中位数的房价
housing_data.plot(kind="scatter",x="longitude",y="latitude") housing_data.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1) housing_data.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1, s=housing_data["population"]/100,label="population",c="median_house_value",cmap=plt.get_cmap("jet"),colorbar = True)

下面,我们看一下和房价相关的都有那些因素,这里使用协方差系数来看一下结果。很明显,有那么几个变量可以很好的作为解释变量,淡然就是那些接近1的变量
corr_matrix = housing_data.corr() corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000 median_income 0.688075 income_cat 0.643892 total_rooms 0.134153 housing_median_age 0.105623 households 0.065843 total_bedrooms 0.049686 population -0.024650 longitude -0.045967 latitude -0.144160 Name: median_house_value, dtype: float64
from pandas.plotting import scatter_matrix attributes = ["median_house_value","median_income","total_rooms","housing_median_age"] scatter_matrix(housing_data[attributes])

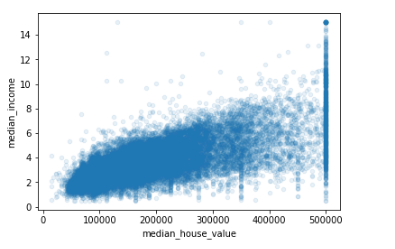
从上面的图更容易看出,第一行第二列,第二行第一列的(上图实际是对称矩阵)图表示有两个维度有较强的线性关系,主对角线上的图是自己和自己的相关性,可以忽略。根据协方差系数,我们再画出这两个数据的散点图如下,看起来关联性还是很强的。
housing_data.plot(kind="scatter",x="median_house_value",y="median_income",alpha=0.1)
7.数据准备,预处理、清洗
from sklearn.base import BaseEstimator,TransformerMixin rooms_ix,bedrooms_ix,population_ix,household_ix=3,4,5,6 class CombinedAttributesAdder(BaseEstimator,TransformerMixin): def __init__(self,add_bedrooms_per_room = True): self.add_bedrooms_per_room = add_bedrooms_per_room def fit(self,X,y = None): return self def transform(self,X,y = None): rooms_per_household = X[:,rooms_ix]/X[:,household_ix] population_per_household = X[:,population_ix]/X[:,household_ix] if self.add_bedrooms_per_room: bedrooms_per_room = X[:,bedrooms_ix]/X[:,rooms_ix] return np.c_[X,rooms_per_household,population_per_household,bedrooms_per_room] else: return np.c_[X,rooms_per_household,population_per_household] attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) housing_extra_attribs = attr_adder.transform(housing_data.values)
from sklearn.base import BaseEstimator,TransformerMixin from sklearn.pipeline import FeatureUnion from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import Imputer from sklearn.preprocessing import LabelBinarizer from sklearn.base import TransformerMixin class MyLableBinarizer(TransformerMixin): def __init__(self,*args,**kwargs): self.encoder = LabelBinarizer(*args,**kwargs) def fit(self,x,y=0): self.encoder.fit(x) return self def transform(self,x,y=0): return self.encoder.transform(x) class DataFrameSelector(BaseEstimator,TransformerMixin): def __init__(self,attribute_names): self.attribute_names = attribute_names def fit(self,X,y=None): return self def transform(self,X): return X[self.attribute_names].values num_attribs = list(house_num) cat_attribs = ["ocean_proximity"] num_pipeline = Pipeline([('selector',DataFrameSelector(num_attribs)), ('imputer',Imputer(strategy="median")), ('attribs_adder',CombinedAttributesAdder()), ('std_scaler',StandardScaler()),]) cat_pipeline = Pipeline([('selector',DataFrameSelector(cat_attribs)), ('lable_binarizer',MyLableBinarizer())]) full_pipline = FeatureUnion(transformer_list=[('num_pipeline',num_pipeline), ('cat_pipeline',cat_pipeline), ]) housing_prepared = full_pipline.fit_transform(house_data) print('next==>') housing_prepared print('next==>') housing_prepared.shape print("done")
8.模型选择和训练
这里使用最简单的线性模型
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(housing_prepared,house_labels)
9.模型预测
some_data = house_data.iloc[:5] some_labels = house_labels.iloc[:5] some_data_prepared = full_pipline.transform(some_data) print("predictions:\t",lin_reg.predict(some_data_prepared)) print("labels:\t\t",list(some_labels))
结果:
predictions: [203682.37379543 326371.39370781 204218.64588245 58685.4770482 194213.06443039] labels: [286600.0, 340600.0, 196900.0, 46300.0, 254500.0]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号