Hadoop之Mapreduce
MR执行过程-map阶段
- map任务处理
- 框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个<k1,v1>。默认,框架对每个 InputSplit中的每一行,解析成一个<k1,v1>。
- 框架调用Mapper类中的map(...)函数,map函数的形参是<k1,v1>对,输出是<k2,v2>对。一个InputSplit对应一个map task。程序员可以覆盖map函数,实现自己的逻辑。
- (假设reduce存在)框架对map输出的<k2,v2>进行分区。不同的分区中的<k2,v2>由不同的reduce task处理。默认只有1个分区。 (假设reduce不存在)框架对map结果直接输出到HDFS中。
- (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少<k2,v2>数量。
- (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
- (假设reduce存在)框架会对map task输出的<k2,v2>写入到linux 的磁盘文件中。 至此,整个map阶段结束
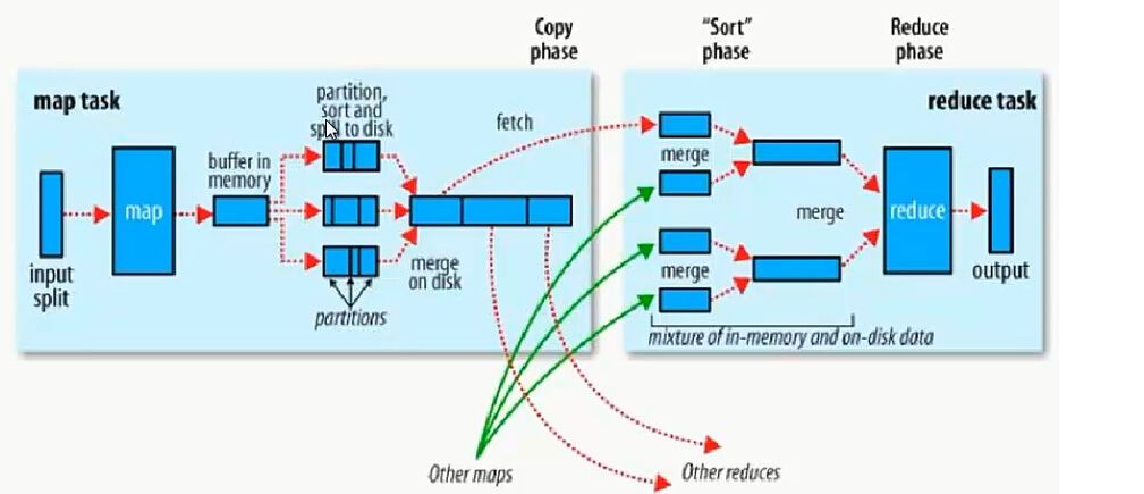
- shuffle过程
- map_shuffle
- 每个map有一个环形内存缓冲区,用于存储map的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容溢写到(spilt)磁盘的指定目录(mapred.local.dir)下的一个新建文件中。
- 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
- 等最后记录写完,合并全部文件为一个分区且排序的文件。
- reduce_shuffle
- Reducer通过Http方式得到输出文件的特定分区的数据。
- 排序阶段合并map输出。然后走Reduce阶段。
- reduce执行完之后,写入到HDFS中。
- map_shuffle
- MapReduce默认数据处理类
-
- InputFormat 抽象类,只是定义了两个方法。
- FileInputFormat
- FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
- TextInputFormat
- 是默认的处理类,处理普通文本文件
- 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value
- 默认以\n或回车键作为一行记录
-
- RecordReader
- 每一个InputSplit都有一个RecordReader,作用是把InputSplit中的数据解析成Record,即<k1,v1>。
- 在TextInputFormat中的RecordReader是LineRecordReader,每一行解析成一个<k1,v1>。其中,k1表示偏移量,v1表示行文本内容
- InputSplit
- 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入。
- 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,会有大量的map task运行,导致效率底下
- 例如:一个1G的文件,会被划分成8个128MB的split,并分配8个map任务处理,而10000个100kb的文件会被10000个map任务处理
- Map任务的数量
- 一个InputSplit对应一个Map task
- InputSplit的大小是由Math.max(minSize, Math.min(maxSize,blockSize))决定
- 单节点建议运行10—100个map task
- map task执行时长不建议低于1分钟,否则效率低
- 特殊:一个输入文件大小为140M,会有几个map task?1个
- FileInputFormat类中的getSplits
- 输入类-FileInputFormat-切片解析
if (isSplitable(job, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(blockSize, minSize, maxSize); long bytesRemaining = length; while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; }
- 什么是序列化,为什么要序列化
- 序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
- 当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象。
- 把对象转换为字节序列的过程称为对象的序列化。
- 把字节序列恢复为对象的过程称为对象的反序列化。
- 说的再直接点,序列化的目的就是为了跨进程传递格式化数据
- 编写MapReduce代码
- map 继承mapper,重写map方法
- 分区继承partitioner,重写getPartitioner方法
- 排序实现WritableComparable接口,写word,num属性,实现write(),readFile()(这俩个就是序列化和反序列化),comparato
- 方法
- 规约Combiner实现reducer,重写reduce方法(实际就是做了reduce的工作)
- reduce基础reducer,重写reduce方法
- 主类:
-
//hadoop配置文件 Configuration configuration = new Configuration(); //创建job任务 Job job = Job.getInstance(configuration); //获取job任务名称 job.setJobName("MRPratition"); //mian函数所在类 job.setJarByClass(Mymapred.class); //获取map端 job.setMapperClass(Mymap.class); //mapkey job.setMapOutputKeyClass(Text.class); //mapvalue job.setMapOutputValueClass(NullWritable.class); //分区 job.setPartitionerClass(Mypartition.class); //规约 job.setCombinerClass(Combiner.class); //获取reduce端 job.setReducerClass(Myreduce.class); //k3 job.setOutputKeyClass(Text.class); //v3 job.setOutputValueClass(NullWritable.class); //reduce数目 job.setNumReduceTasks(2); //指定读取路径 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("/MRpartition/partition.txt")); TextOutputFormat.setOutputPath(job,new Path("/MRpartition/part")); //开启任务 job.waitForCompletion(true);
-
-
整个mapreduce过程
-
Fileinputstream读取源文件,把输入文件(夹)划分为很多InputSplit(默认,每个HDFS的block对应一个InputSplit),每一个InputSplit都有一个RecordReader,作用是把InputSplit中的数据解析成Record,即<k1,v1>。
-
每个InputSplit都有一个map task,程序员可以覆盖map函数,实现自己的逻辑。
-
进入 map_shuffle阶段,map输入的数据会进入一个环形缓冲区,当达到一定条件(见2),会进行溢写操作(写入磁盘),在写入磁盘前,进行分区,排序(快排),规约->小文件->合并小文件->排序(归并)->临时文件,之后写入磁盘
-
通过网络传输,进入reduce缓冲区(磁盘和内存中文件会混合)->溢写->小文件->合并->排序(归并),分组->中间文件->reducetask->输出
-
-
IDEA中显示mapredu程序过程配置文件 在resources文件夹中创建log4j.properties文件
-
# log4j.rootLogger日志输出类别和级别:只输出不低于该级别的日志信息DEBUG < INFO < WARN < ERROR < FATAL # A1是一个“形参”代表输出位置,具体的值在下面 log4j.rootLogger=DEBUG, A1 # 配置A1输出到控制台 log4j.appender.A1=org.apache.log4j.ConsoleAppender # 配置A1设置为自定义布局模式 log4j.appender.A1.layout=org.apache.log4j.PatternLayout # 配置日志的输出格式 %r耗费毫秒数 %p日志的优先级 %t线程名 %C所属类名通常为全类名 %x线程相关联的NDC %m日志 %n换行 log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
- marpreduce中实现join
例:
package hadoop; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.ArrayList; public class Demo06Join { public static class JoinMapper extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1 获取数据的路径 InputSplit inputSplit = context.getInputSplit(); FileSplit fs = (FileSplit) inputSplit; String url = fs.getPath().toString(); if (url.contains("students")) { String id = value.toString().split(",")[0]; String line = "*" + value.toString(); context.write(new Text(id), new Text(line)); } else { if (url.contains("score")) { String id = value.toString().split(",")[0]; String line = "#" + value.toString(); context.write(new Text(id), new Text(line)); } } } } public static class JoinReducer extends Reducer<Text,Text,Text,NullWritable>{ @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //数据在循环外保存 String stuInfo=""; ArrayList<String> scores = new ArrayList<String>(); for (Text value : values) { String line = value.toString(); if (line.startsWith("*")){ stuInfo = line.substring(1); }else { scores.add(line.substring(1)); } } // 数据拼接(成绩总分) long sum=0l; for (String score : scores) { String sc = score.split(",")[2]; Integer scc = Integer.valueOf(sc); sum+=scc; } String end = stuInfo+","+sum; context.write(new Text(end),NullWritable.get()); //数据拼接 (各科成绩) // for (String score : scores) { // String subject = score.split(",")[1]; // String s = score.split(",")[2]; // String end = stuInfo+","+subject+","+s; // context.write(new Text(end),NullWritable.get()); // } } } public static void main(String[] args) throws Exception{ Job job = Job.getInstance(); job.setJobName("Joinmapreduce"); job.setJarByClass(Demo06Join.class); job.setMapperClass(JoinMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(JoinReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.addInputPath(job,new Path("/data")); FileOutputFormat.setOutputPath(job,new Path("/join")); job.waitForCompletion(true); System.out.println("join正在执行"); } }
- map_join
- 之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。
- Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
- 为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
- 用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
- 用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件
例:
package BigData; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import sun.nio.cs.ext.SimpleEUCEncoder; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.HashMap; import java.util.logging.SimpleFormatter; public class Demo1 { public static class CallMapper extends Mapper<LongWritable,Text,Text,NullWritable>{ String name=""; String name2=""; String start=""; String end=""; String Time=""; String locat1=""; String locat2=""; HashMap<String,String> people = new HashMap<String, String>(); HashMap<String,String> locat = new HashMap<String, String>(); public void bfUserPhone(){ try { BufferedReader bf = new BufferedReader(new FileReader("E:\\IDEJAVA\\hadoop\\data\\userPhone.txt")); String line; while ((line=bf.readLine())!=null){ String[] split = line.split(","); people.put(split[1],split[2]); } } catch (Exception e) { e.printStackTrace(); } } public void bfLocation(){ try { BufferedReader bf = new BufferedReader(new FileReader("E:\\IDEJAVA\\hadoop\\data\\location.txt")); String line; while ((line=bf.readLine())!=null){ String[] split = line.split(","); locat.put(split[1],split[2]); } } catch (Exception e) { e.printStackTrace(); } } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { bfUserPhone(); bfLocation(); SimpleDateFormat sdf = new SimpleDateFormat("YY-MM-DD HH-mm-ss"); String[] split = value.toString().split(","); name = people.get(split[0]); name2 = people.get(split[1]); start = sdf.format(Long.parseLong(split[2])); end = sdf.format(Long.parseLong(split[3])); Time = Long.parseLong(split[3])-Long.parseLong(split[2])+"秒"; locat1 = locat.get(split[4]); locat2 = locat.get(split[5]); String s = name+","+name2+","+start+","+end+","+Time+","+locat1+","+locat2+","; context.write(new Text(s),NullWritable.get()); } } public static void main(String[] args) throws Exception{ Job job = Job.getInstance(); job.setJobName("MapJoin"); job.setNumReduceTasks(0); job.setMapperClass(CallMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); FileInputFormat.addInputPath(job,new Path("E:\\IDEJAVA\\hadoop\\data\\calls.txt")); FileOutputFormat.setOutputPath(job,new Path("E:\\IDEJAVA\\hadoop\\data\\output")); job.waitForCompletion(true); System.out.println("任务执行"); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号