
深度学习编译器学习笔记(1)
深度学习编译器综述
深度学习编译器加速的本质:加速矩阵乘法的运算。
编译器前端和高层的IR
本质:从图论、数学的角度,来考虑DL加速的问题。
深度学习模型的表示
深度学习模型的在计算机中是以有向无环图(DAG)来表示的。
在TVM中,同时实现了DAG和let-binding表达方式。(DAG, 龙书 P342)
let-binding:直接指向网络节点的输出。
A "let binding" binds values to names. In other languages they might be called a "variable declaration".
图计算的优化
-
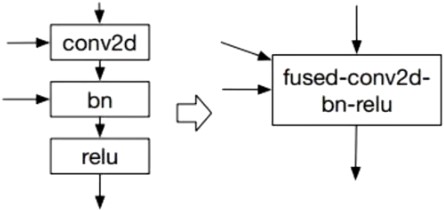
经典优化 Conv + Batch Norm + relu 三个算子融合(TVM代码)
![]()
-
支配树算法(DAG里的一部分)
图节点分类
- injective: 映射函数,比如加法、点乘等。
- reduction:输入到输出具有降维性质的,比如sum。
- complex-out:这是比较复杂的,比如卷子运算。
- opaque: 无法被融合的算符,比如sort。
编译器的后端和低层IR
本质:从计算机底层出发,考虑DL加速的问题。
内核库
代码生成器
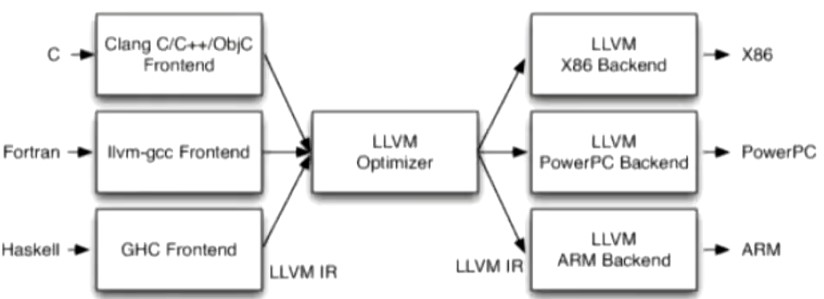
- 代码生成器: LLVM, OpenCL, CUDA, OpenGL
![]()
不同的前端后端使用同意的中间代码LLVM IR。
在CPU上做深度学习加速基本都会用到LLVM
底层运算IR
- Halide
深度学习没起来之前就开始广泛应用了,如OpenCV以及Photoshop的底层。
Halide语言将算法描述与算法中数据存储与计算执行等调度方面的内容解耦合。从而算法的描述和性能的优化可以分开进行,可以在不改动算法的情况下对算法进行调优。
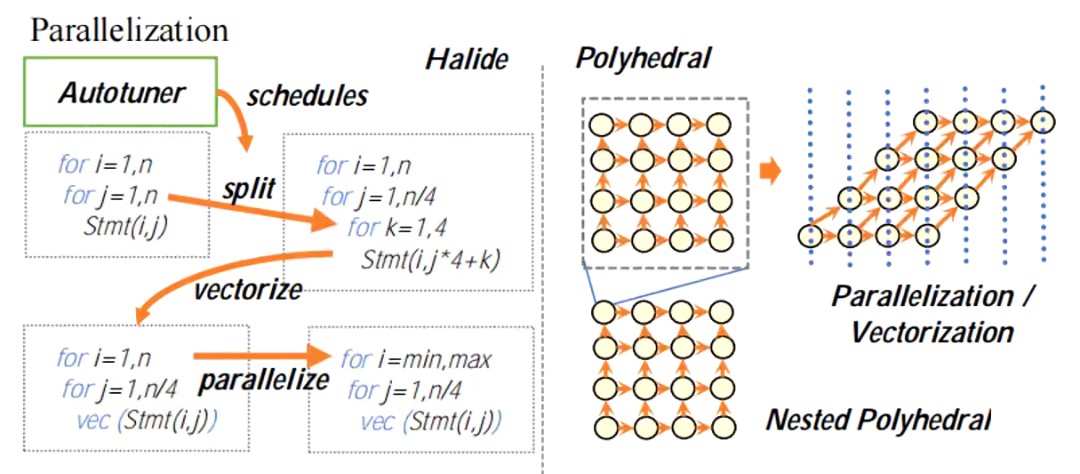
- Polyhedral
多面体模型最关注的就是循环的优化,它只会把一段段程序当成一堆嵌套循环,而不关心循环里面的内容。
多面体编译技术是指在循环边界约束条件下将语句实例表示成空间多面体, 并通过这些多面体上的几何操作来分析和优化程序的编译技术, 这种模型称为多面体模型.多面体模型通常利用迭代空间(domain)、访存映射(write and read)、依赖关系(dependence)和调度(schedule)表示程序及其语义.
- Statement,代表一行代码;
- 循环中的代码每执行一次,就会对应到一个instance;
- 对于一个N重循环,每个instance对应的循环可以被表示成一个长度为N的vector。而所有可能的vector的集合就是Domain。
- dependence指的是程序之间的依赖关系,指的是两个statement之间。
[1] https://www.bilibili.com/video/BV1cK4y1U7Q5 黄雍涛 北京邮电大学 B站。
[2] 赵捷, 李颖颖, 赵荣彩. 基于多面体模型的编译“黑魔法”[J]. 软件学报, 2018, 29(8): 2371-2396.http://www.jos.org.cn/1000-9825/5563.htm
[3] https://zhuanlan.zhihu.com/p/310142893 知乎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号