
数据采集第四次作业
第四次作业


作业1
代码
爬虫代码
url='https://quote.eastmoney.com/center/gridlist.html#hs_a_board'
driver.get(url)
driver.implicitly_wait(5)
try:
#关闭广告
close_ad=driver.find_element(By.XPATH,'//img[@onclick="tk_tg_zoomin()"]')
close_ad.click()
driver.implicitly_wait(5)
except:
pass
# print(driver.page_source)
pages=5
result={}
names=['hs_a_board','sh_a_board','sz_a_board']
for i in range(3):
tables=[]
for _ in range(pages):
#定位表格
t=driver.find_element(By.XPATH,'//div[@class="quotetable"]/table/tbody')
for row in t.find_elements(By.TAG_NAME,'tr'):
rows = {}
cells=row.find_elements(By.TAG_NAME,'td')
rows['id']=cells[0].text
rows['code']=cells[1].text
rows['stock_name']=cells[2].text
rows['last_price']=cells[4].text
rows['change_percent']=cells[5].text
rows['change']=cells[6].text
rows['turnover']=cells[7].text
rows['volume']=cells[8].text
rows['amplitude']=cells[9].text
rows['high']=cells[10].text
rows['low']=cells[11].text
rows['open']=cells[12].text
rows['close']=cells[13].text
tables.append(rows)
#翻页
next_page=driver.find_element(By.XPATH,'//a[@class="acitve"]/following-sibling::*[1]')
next_page.click()
driver.implicitly_wait(5)
result[names[i]]=tables
#切换表格
next_board=driver.find_element(By.XPATH,'//ul[@class="scf"]/li[@class="active"]/following-sibling::li[1]/a')
next_board.click()
driver.implicitly_wait(5)
with open('result.json','w',encoding='utf-8') as f:
json.dump(result,f,ensure_ascii=False)
driver.quit()
关闭广告后先定位到目标表格,通过浏览器快速定位,再进行后续操作,提取信息的过程不过多赘述了
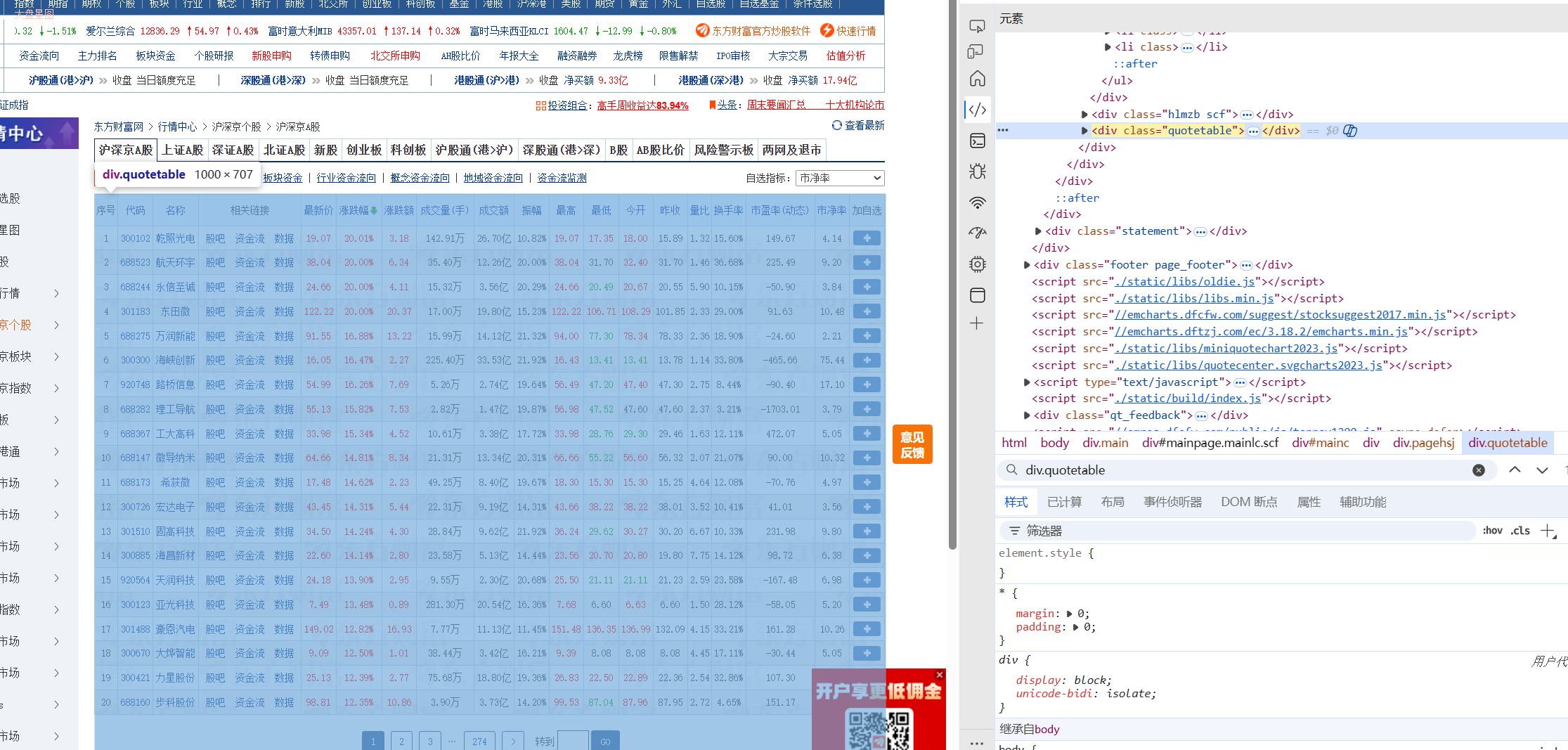
针对翻页操作可以通过修改url或者通过selenium模拟点击进行,这里展示后者。先观察翻页键特征,发现活动页有一个class值为active,可以以此来定位到下一页,即active的a标签的下一个a标签。通过模拟点击即可实现翻页。切换表格步骤类似。

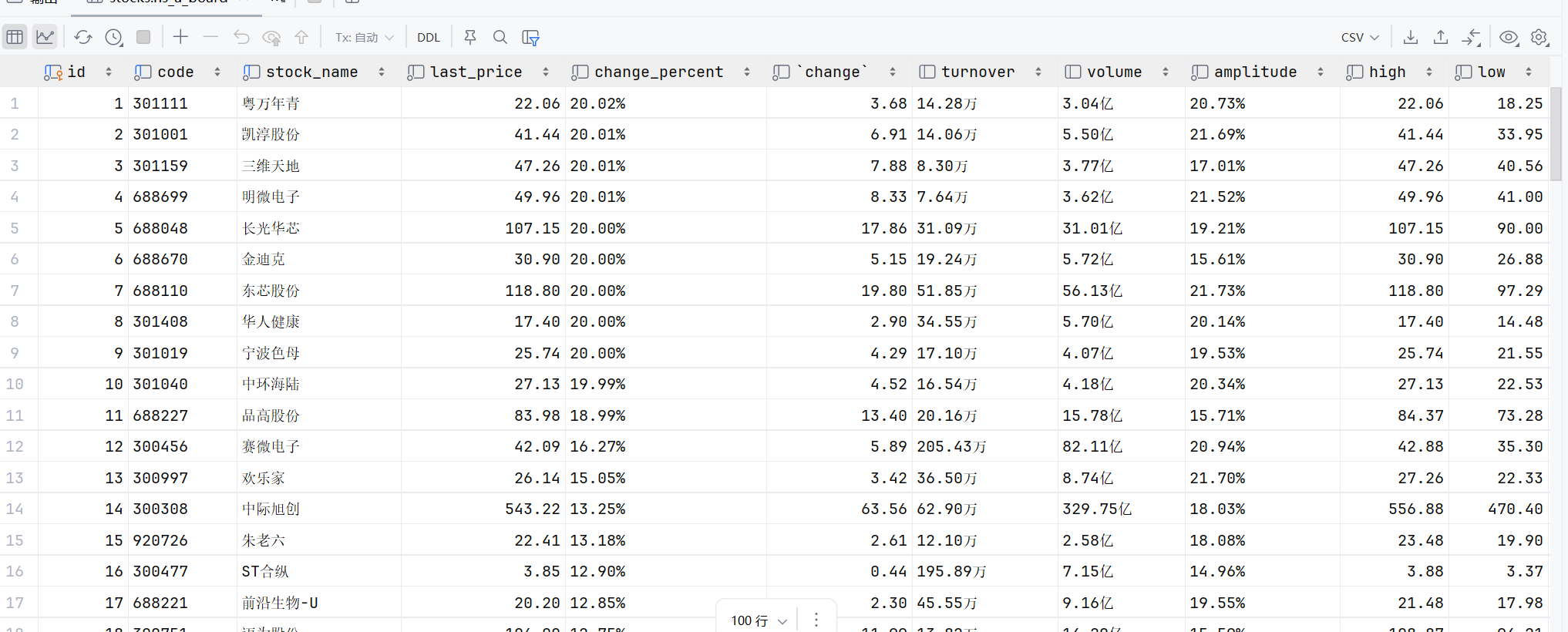
结果展示:
心得
通过这次股票数据爬取实践,我掌握了处理广告弹窗、定位页面元素和实现翻页机制等爬虫关键技术,学会了用稳健的代码应对网页动态变化。这次经历让我深刻体会到,解决实际问题不仅需要技术实现,更需要耐心调试和全面考虑边界情况,为后续数据分析工作奠定了重要基础。
链接:https://gitee.com/wsxxs233/data-collection/tree/master/task4/blog/q1
作业2
代码
登录信息配置
#替换自己的账号密码
Myaccount=config.account
Mypasswd=config.passwd
driver.get('https://www.icourse163.org')
driver.implicitly_wait(5)
#cookie添加,避免重复登录
# with open("cookies.json", "r") as f:
# cookies = json.load(f)
# for cookie in cookies:
# cookie['secure']=True
# driver.add_cookie(cookie) # 将每个Cookie添加到驱动
driver.refresh()
这部分可选导入登录信息(需要登录过并保存cookie)给selenium来避免调试时重复登录
模拟登录
#登录按钮
login = driver.find_element(By.XPATH, '//div[@role="button" and contains(text(), "登录/注册")]')
login.click()
wait = WebDriverWait(driver, 10)
# 等待登录弹窗容器
login_modal = wait.until(
EC.presence_of_element_located((By.XPATH, '//div[contains(@id, "loginModal")]'))
)
#真实的登录表单在<iframe>里
frame=login_modal.find_element(By.XPATH, '//iframe[contains(@src, "reg.icourse163.org")]')
driver.switch_to.frame(frame)
username_input = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//input[@type='tel']")) # 请根据实际页面检查输入框的name或id
)
passwd=driver.find_element(By.XPATH, "//input[@type='password' and contains(@placeholder, '请输入密码')]")
submit=driver.find_element(By.XPATH, "//a[@id='submitBtn' and contains(text(), '登 录')]")
username_input.send_keys(Myaccount)
passwd.send_keys(Mypasswd)
submit.click()
driver.implicitly_wait(5)
time.sleep(3)
#保存cookie到文件
# cookies = driver.get_cookies()
# with open('cookies.json', 'w') as f:
# json.dump(cookies, f)
这部分用来找到登录按钮并模拟点击,同时从生成的登录模态框中找出真实表单。直接查找input会返回一个无效的输入框。
真实的输入框是通过iframe加载的,需要找到链接并生成。
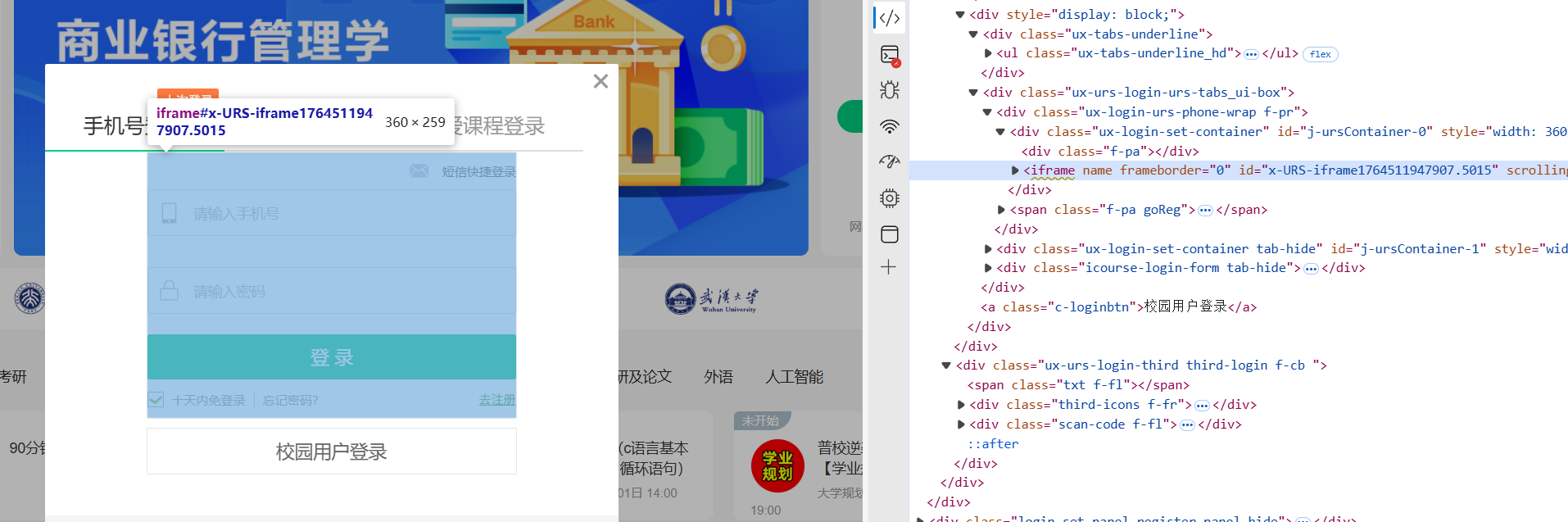
后续步骤就是从这个表单中找出输入输出框的位置,并用send_key设置值并登录。同时可以将登录后的cookie保存下来,避免重复登录。
进入主页
try:
access=WebDriverWait(driver, 5).until(
EC.element_to_be_clickable(
(By.XPATH, '//button[contains(text(), "同意")]'))
)
access.click()
driver.implicitly_wait(5)
print('同意协议')
except :
pass
# print(search.get_attribute('outerHTML'))
MyCourse = driver.find_element(By.XPATH, '//div[@role="button" and contains(text(), "我的课程")]')
MyCourse.click()
EC.visibility_of_element_located((By.XPATH, "//div[@class='m-mcdoc']"))
#可能有加载遮盖层
try:
WebDriverWait(driver, 10).until(
EC.invisibility_of_element_located((By.ID, "loadingMask"))
)
# print("加载遮罩层已消失")
except TimeoutException:
print("遮盖层超时")
origin_window = driver.current_window_handle
course_divs = driver.find_elements(By.XPATH, '//div[@class="course-card-wrapper"]')
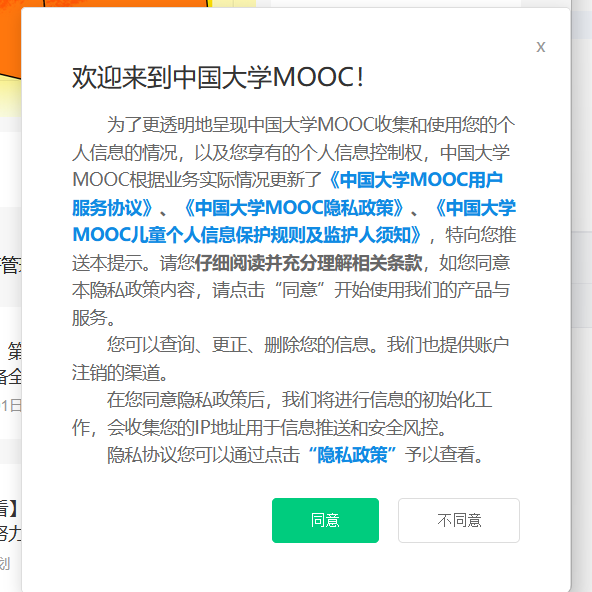
同时这个网站在页面加载完成前都会设一个模态框在前台,所以需要等那些模态框消失再进行操作,否则会提示有模态框存在导致错误。


#等待loadingMask消失
try:
WebDriverWait(driver, 10).until(
EC.invisibility_of_element_located((By.ID, "loadingMask"))
)
# print("加载遮罩层已消失")
except TimeoutException:
print("遮盖层超时")
#等待component-eva-modal消失
try:
# 等待常见遮挡元素消失
WebDriverWait(driver, 30).until(
EC.invisibility_of_element_located((By.CLASS_NAME, "component-eva-modal"))
)
except:
pass # 如果没有遮挡元素,继续执行
后续操作就是从course_divs把各门课的信息读出来。
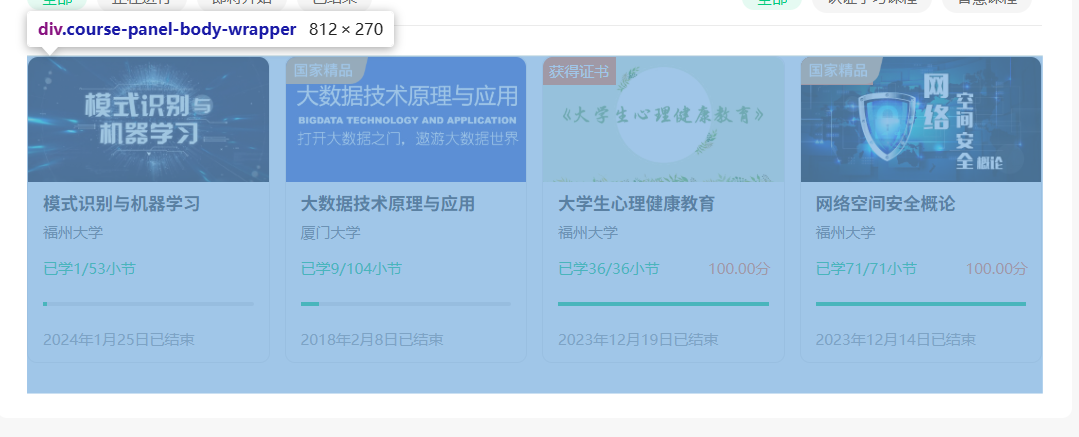
for course_div in course_divs:
course_div.click()
wait = WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2))
driver.switch_to.window(driver.window_handles[1])
#...处理操作
driver.close()
driver.switch_to.window(origin_window)
同时需要selenium管理一下页面,mooc把每门课的详情信息放在单独的标签页里,所以需要管理窗口,在每页任务完成后及时返回。
学习页示例
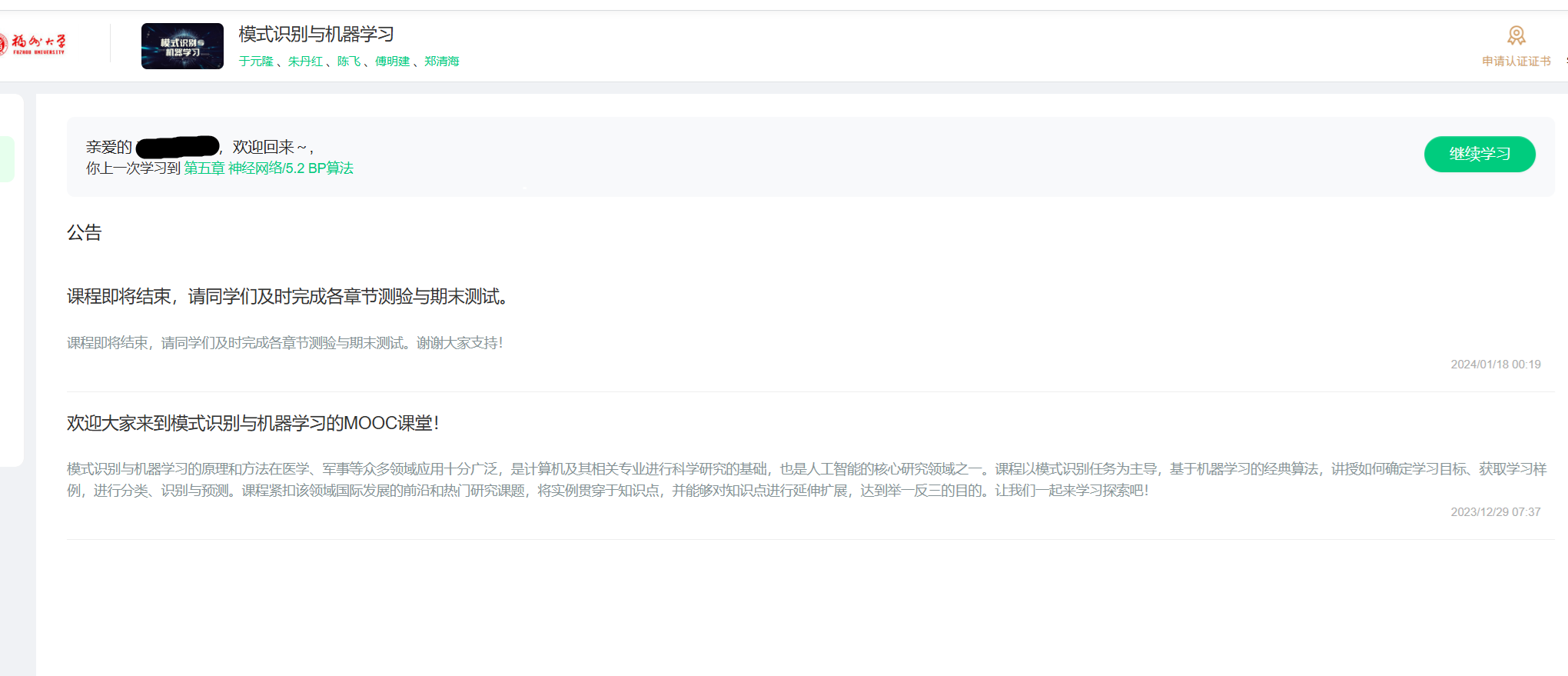
通过个人课程内跳转的课程信息会先跳到学习页面而不是课程详情页,所以需要跳转过去,这部分不多概述。在进入学习页时可能会出现评价栏,会影响后续操作,所以需要先关闭这个框。
结果:

心得:
通过本次中国大学MOOC的模拟登录和课程信息爬取实践,我深入掌握了Selenium的页面元素定位、多窗口管理和等待机制,学会了处理iframe嵌套表单、模态框干扰等复杂场景,培养了分析DOM结构、调试自动化脚本的能力,这些实战经验让我对Web自动化测试有了系统性的认识,也为后续的数据采集工作奠定了坚实基础。
为了保护个人信息,代码中的账号密码是通过config形式导入,请自行替换。
链接:https://gitee.com/wsxxs233/data-collection/tree/master/task4/blog/q2
作业3
操作及截图
买公网

买集群

数据库

资源池

测试
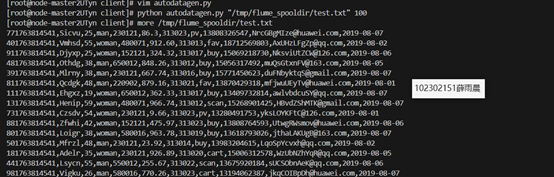
Kafka 创建topic


安装flume
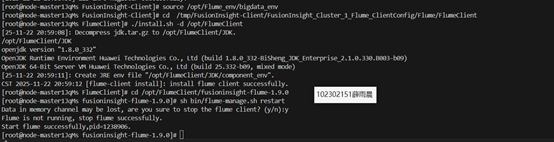
测试kafka与flume连通
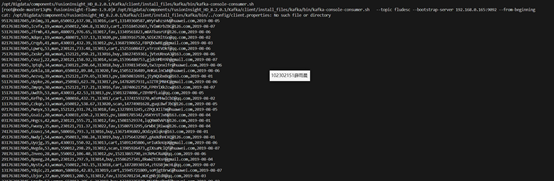
创建数据库
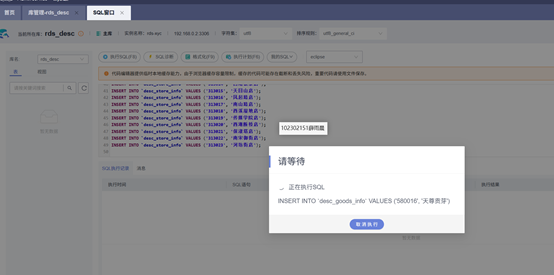
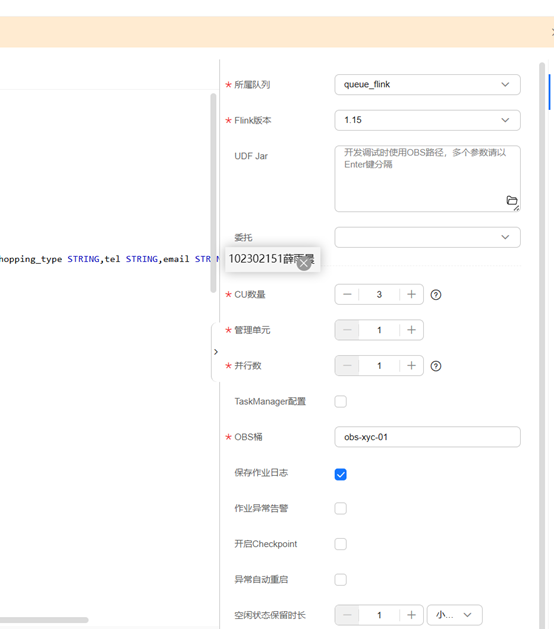
Flink作业
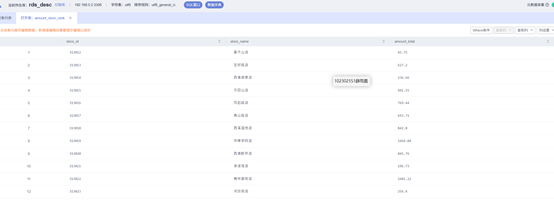
验证
心得
通过本次《大数据实时分析处理实验》,我对实时数据流的处理流程有了系统性的实践与理解,具体收获如下:从数据模拟生成、Flume采集、Kafka缓存、Flink实时计算到MySQL存储和DLV可视化,完整走通了实时数据流水线,理解了各组件在流水线中的作用与配置要点。实践了MRS、DLI、RDS、DLV等服务的开通、配置与联动,增强了对云原生大数据平台的整体认知和操作能力。在配置跨源连接、安全组、网络互通等环节中遇到多个实际问题,通过日志分析、连通性测试、参数校验等方法逐步定位并解决,提升了系统调试能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号