

GlusterFS分布式文件系统原理
GlusterFS概述
GlusterFS(Gluster File System)是一个开源的分布式文件系统,主要由Z RESEARCH公司负责开发、是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,在存储方面具有强大的横向扩展能力,通过扩展不同的节点可以支持数PB存储容量和处理数干台客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间及无元的设计,可为各种不同的数据负载提供优异的性能。
GlusterFS主要由存储服务器(Block Server)、客户端及NFS/Samba存储网关(可选,根据需要选择使用)组成,GlusteFS架构中最大的设计特点是没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。
GlusterFS主要特征如下:
扩展性和高性能
高可用性
全局统一命名空间
弹性哈希算法
弹性卷算法
基于标准协议
GlusterFS的卷类型:
GlusterFS支持七种卷,分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷和分布式条带复制卷,这七种卷可以满足不同应用对高性能、高可用的需求。
1.分布式卷
分布式卷是GlusterFS的默认卷,在创建卷时,默认选项是创建分布式卷。在该模式下,并没有对文件进行分块处理,文件直接存储在某个Server节点上。直接使用本地文件系统进行文件存储,大部分Linux命令和工具可以继续正常使用。需要通过扩展文件属性保存HASH值,目前支持的底层文件系统有ext3、ext4、ZFS、XFS等。
由于使用本地文件系统,所以存取效率并没有提高,反而会因为网络通信的原因而有所降低;另外支持超大型文件也会有一定的难度,因为分布式卷不会对文件进行分块处理。虽然ext4已经可以支持最大16TB的单个文件,但是本地存储设备的容量实在有限。
分布式卷具有如下特点:
·文件分布在不同的服务器,不具备冗余性。
·更容易且廉价地扩展卷的大小。
·单点故障会造成数据丢失。
·依赖底层的数据保护。
创建分布式卷:
#gluster volume create dis-volume serverl:/dirl server2:/dir2
Creation of dis-volume has been successful
Please start the volume to access data
上述命令创建了一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中。
2.条带卷
Stripe模式相当RAIDO,在该模式下,根据偏移量将文件分成N块(N个条带节点),轮询地存储在每个Brick Server节点。节点把每个数据块都作为普通文件存入本地文件系统中,通过扩展属性记录总块数(Stripe-count)和每块的序号(Stripe-index)。在配置时指定的条带数必须等于卷中Brick所包含的存储服务器数,在存储大文件时,性能尤为突出,但是不具备冗余性。
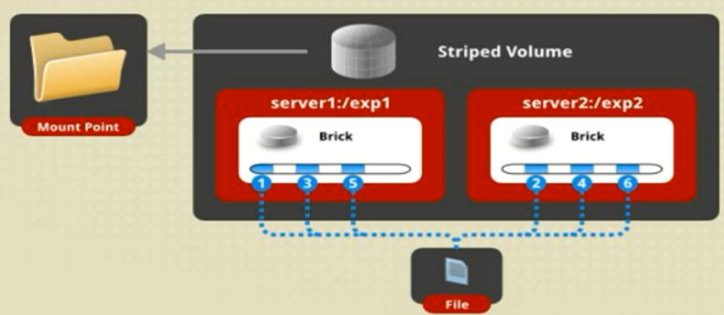
条带卷具有如下特点:
·数据被分割成更小块分布到块服务器群中的不同条带区。
·分布减少了负载且更小的文件加速了存取的速度。
·没有数据冗余。
创建条带卷:
#gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
Creation of stripe-volume has been successful
Please start the volume to access data
上述命令创建了一个名为Stripe-volume的条带卷,文件将被分块轮询地存储在Server1:/dir1和Server2:/dir2两个Brick中。
3.复制卷
复制模式,也称为AFR(AutoFile Replication),相当于RAID1,即同一文件保存一份或多份副本,每个节点上保存相同的内容和目录结构。复制模式因为要保存副本,所以磁盘利用率较低,如果多个节点上的存储空间不一致,那么将按照木桶效应取最低节点的容量作为该卷的总容量。在配置复制卷时,复制数必须等于卷中Brick所包含的存储服务器数,复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。
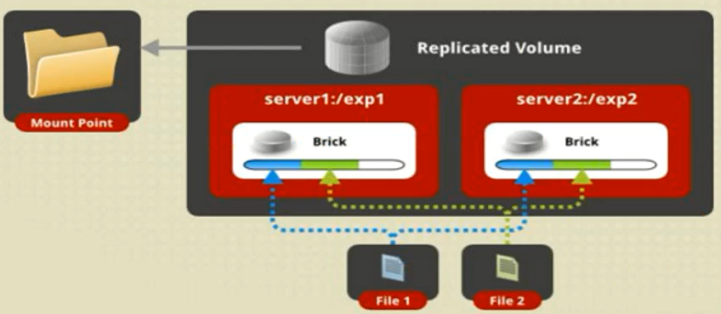
复制卷具有如下特点:
·卷中所有的服务器均保存一个完整的副本。·卷的副本数量可由客户创建的时候决定。
·至少有两个块服务器或更多服务器。
·具备冗余性。
创建复制卷:
#gluster volume create rep-volume replica 2 transport tcp server1:/dirl server2:/dir2
Creation of rep-volume has been successful
Please start the volume to access data
上述命令创建了一个名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中。
4.分布式条带卷
分布式条带卷兼顾分布式卷和条带卷的功能,主要用于大文件访问处理,创建一个分布式条带卷最少需要4台服务器。
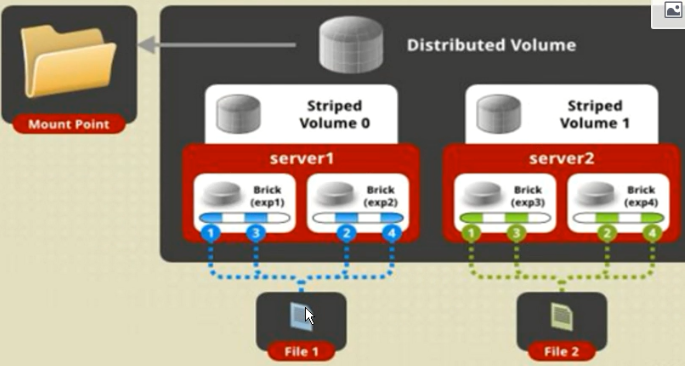
创建分布式条带卷:
#gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3
server4:/dir4
Creation of dis-stripe has been successful
Please start the volume to access data
上述命令创建了一个名为dis-stripe的分布式条带卷,配置分布式条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(≥2倍)。如上述命令中,Brick的数量是4(Server1:/dir1、Server2:/dir2、Server3:/dir3和Server4:/dir4),条带数为2(stripe2)。
5.分布式复制卷
分布式复制卷兼顾分布式卷和复制卷的功能,主要用于需要冗余的情况下。
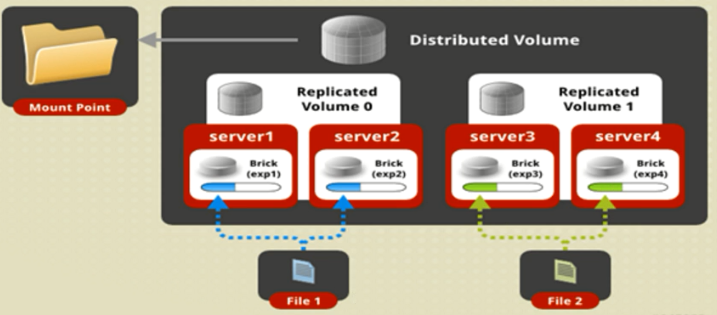
创建分布式复制卷:
#gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3
server4:/dir4
Creation of dis-rep has been successful
Please start the volume to access data
上述命令创建了一个名为dis-rep的分布式复制卷,配置分布式复制卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(≥2倍)。如上述命令中,Brick的数量是4(Server1/dir1、Server2:/dir2、Server3:/dir3和Server4:/dir4),复制数为2(replica2)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号