【Python基础】Python模块和包
模块(modue)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较,
很多编程语言都采用这种组织代码的方式。在Python中一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
1、最大的好处是大大提高了代码的可维护性。
2、其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。
我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
-
python标准库
-
第三方模块
-
自定义模块
另外,使用模块还可以避免函数名和变量名冲突。
相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。
但是也要注意,尽量不要与内置函数名字冲突。
模块导入方法
import 语句
import module1[, module2[,... moduleN] import time,random,numpy,sys
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?答案就是解释器有自己的搜索路径,存在sys.path 里。
['D:\\360Downloads\\Python编程\\老男孩python全栈\\Python基础到进阶\\Python模块',
'D:\\360Downloads\\Python编程\\老男孩python全栈',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\python36.zip',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\DLLs',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\lib',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36',
'C:\\Users\\Administrator\\AppData\\Roaming\\Python\\Python36\\site-packages',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages\\baidu_aip-2.2.4.0-py3.6.egg',
'C:\\Program Files\\JetBrains\\PyCharm 2018.1.1\\helpers\\pycharm_matplotlib_backend']
第一条路径就是当前执行文件的文件夹绝对路径
from…import ... 语句
同级目录下: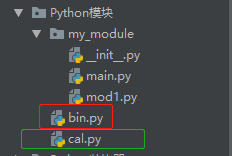


----------------------------------------bin.py from cal import multi print(multi(2,3,4,5,6)) ----------------------------------------cal.py def multi(*args): ss=1 for i in args: ss = ss*i return ss #############bin.py 和 cal.py 在同一级目录下
不同级目录: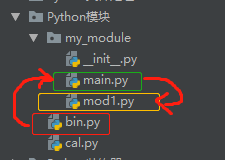
----------------------------------bin.py from my_module import main main.run() ----------------------------------my_module/main.py from my_module import mod1 def run(): print(mod1.upper_str("xiong")) -----------------------------------my_module/mod1.py def upper_str(s): return s.upper()
注意:不能直接在 main.py 中 import mod1。因为sys.path ---> 列表路径中没有main.py 的路径,
解决办法是向 sys.path 路径中添加想要导入模块的路径即可
向系统路径列表中sys.path append()
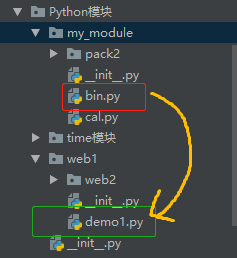
my_module 文件夹 和 web1 文件夹 同级别,都在Python模块文件夹下。bin.py 需要import demo1
import sys ,os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) print(BASE_DIR) #D:\360Downloads\Python编程\老男孩python全栈\Python基础到进阶\Python模块 # print(sys.path) sys.path.append(BASE_DIR) # print(sys.path) from web1 import demo1 print(demo1.add(2,3)) # print(__file__) # #D:/360Downloads/Python编程/老男孩python全栈/Python基础到进阶/Python模块/my_module/bin.py # #其实 __file__ 得到的是 bin.py,前面的路径都是pycharm自动加上去的--->os.path.abspath(__file__) # print(os.path.abspath(__file__))

包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。
方法是选择一个顶层包名:
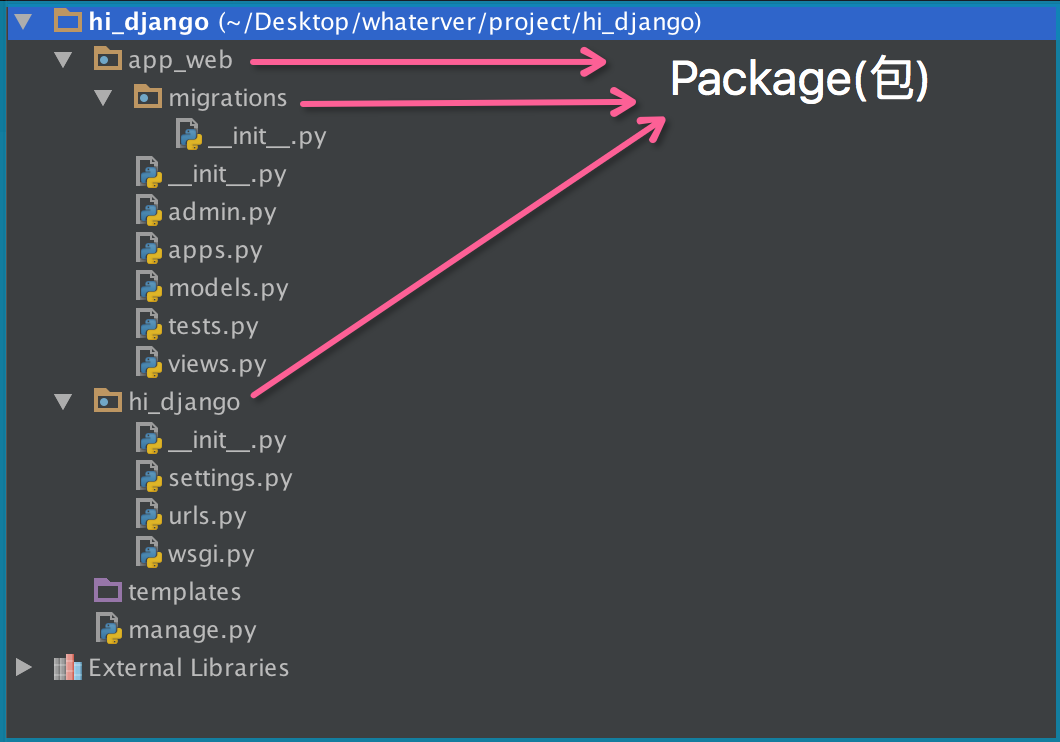
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
2种方法导入包里面的文件:
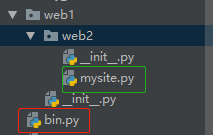
from web1.web2 import mysite #from web1.web2.mysite import add print(mysite.add(2,3)) #print(add(2,3))
from web1 import web2 #其实就是执行web2 中 __init__ 文件,唯一不支持web2.mysite.add() 的调用(不推荐用)
print(web2.mysite.add(2,3)) #报错
补充:
from web1 import web2 #其实就是执行web2 中 __init__ 文件,唯一不支持web2.mysite.add() 的调用(不推荐用) print(web2.mysite.add(2,3)) #报错 -------------------------在web2 的__init__.py 中加入下面代码可解决上述问题 from . import mysite
注意点(important)
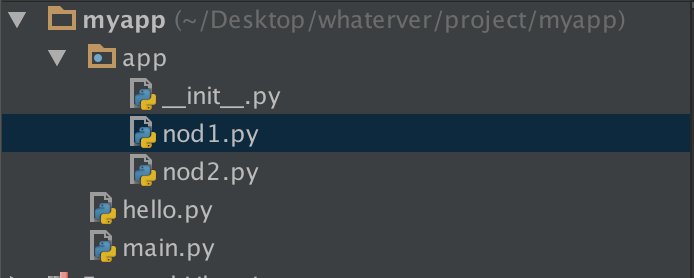
1--------------
在nod1里import hello是找不到的,有同学说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) import hello hello.hello1()
2 --------------
if __name__=='__main__': main.run() print('ok')
--->如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的路径+ 名字而不是__main__。
这个功能用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该py文件,调试代码能够正常运行!
3----------------------

##-------------cal.py def add(x,y): return x+y ##-------------main.py import cal #from module import cal def run(): cal.add(1,2) ##--------------bin.py from module import main main.run()
# from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本, # sys.path里有bin.py的当前环境。即/Users/yuanhao/Desktop/whaterver/project/web这层路径, # 无论import what , 解释器都会按这个路径找。所以当执行到main.py时,import cal会找不到,因为 # sys.path里没有/Users/yuanhao/Desktop/whaterver/project/web/module这个路径,而 # from module/. import cal 时,解释器就可以找到了。
Python中常用的内建模块
time模块(* * * *)
在Python中,通常有3种方式来表示时间:
- 时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串
- 元组(struct_time) : struct_time结构化时间元组共有九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time # 1 time() :返回当前时间的时间戳 time.time() #1473525444.037215 #---------------------------------------------------------- # 2 localtime([secs]) # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
>>> time.localtime()
time.struct_time(tm_year=2020, tm_mon=3, tm_mday=12, tm_hour=11, tm_min=46, tm_sec=52,
tm_wday=3, tm_yday=72, tm_isdst=0)
>>> time.localtime(1583984802.0806165)
time.struct_time(tm_year=2020, tm_mon=3, tm_mday=12, tm_hour=11, tm_min=46, tm_sec=42,
tm_wday=3, tm_yday=72, tm_isdst=0)
#---------------------------------------------------------- # 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 #---------------------------------------------------------- # 4 mktime(t) : 将一个struct_time转化为时间戳。 print(time.mktime(time.localtime()))#1473525749.0 #---------------------------------------------------------- # 5 asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。 # 如果没有参数,将会将time.localtime()作为参数传入。 print(time.asctime())#Sun Sep 11 00:43:43 2016 #---------------------------------------------------------- # 6 ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为 # None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。 print(time.ctime()) # Sun Sep 11 00:46:38 2016 print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016 # 7 strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个 # 元素越界,ValueError的错误将会被抛出。 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56 # 8 time.strptime(string[, format]) # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, # tm_wday=3, tm_yday=125, tm_isdst=-1) #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。 # 9 sleep(secs) # 线程推迟指定的时间运行,单位为秒。 # 10 clock() # 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。 # 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行 # 时间,即两次时间差。

import datetime t = datetime.datetime.now() print(t) #datetime.datetime(2020, 3, 12, 11, 52, 28, 987030)
random模块(* * * *)
import random print(random.random()) #(0,1)----float print(random.randint(1,3)) #1 2 3 print(random.randrange(1,3)) #1 2 print(random.choice([1,'23',[4,5]])) #任意一项
#多用于截取列表的指定长度的随机数,但是不会改变列表本身的排序 print(random.sample([1,'23',[4,5]],2))#[[4, 5], '23'] # print(random.uniform(1,3)) #返回一个浮点数N,取值范围为如果 x<y 则 x <= N <= y,如果 y<x 则y <= N <= x item=[1,3,5,7,9] random.shuffle(item) print(item)
def v_code(): ret="" for i in range(4): num=random.randint(0,9) numTostr = random.randint(65, 122) while numTostr in [91,92,93,94,95,96]: numTostr = random.randint(65,122) alf=chr(numTostr) s=str(random.choice([num,alf])) ret+=s return ret print(v_code())
os模块(* * * *)
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 current work direction os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息(获取文件大小,创建时间,最近访问访问,最近修改时间) os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
a = "D:/360Downloads/Python编程/老男孩python全栈/Python基础到进阶" b = "Python模块/os模块/demo1.py" print(os.path.join(a,b))
sys模块(* * *)
sys.argv 命令行参数List,第一个元素是程序本身路径(用途:使input()不必在程序运行过程中输入)
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息(程序兼容性)
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
进度条:
import sys,time for i in range(10): sys.stdout.write('#') #向屏幕中显示#,不是每一次都显示一个#而是放在一个缓存中 全部加载完成后一次打印到屏幕 time.sleep(1) sys.stdout.flush() #刷新
json和pickle(* * * * *)
之前我们学习过用eval()内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,
json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了。
所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json x="[null,true,false,1]" print(eval(x)) print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON。
因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。
JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:

#----------------------------序列化 import json dic={'name':'alvin','age':23,'sex':'male'} print(type(dic)) #<class 'dict'> j=json.dumps(dic) print(type(j)) #<class 'str'> f=open('序列化对象','w') f.write(j) #-----------等价于json.dump(dic,f) f.close() #-----------------------------反序列化 import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f) ####推荐使用 json.loads() 和 json.dumps()
pickle
##----------------------------序列化 import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic) print(type(j)) #<class 'bytes'> pickle.dumps() 序列化为字节,人为不可读但计算机认识 f=open('序列化对象_pickle','wb') #注意是w是写入str,wb是写入bytes,j是'bytes' f.write(j) #-------------------等价于pickle.dump(dic,f) f.close() #-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,
并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
pickle能序列化很多类型(除了一般的数据类型外还可以序列化函数、类等)
shelve模块(* * *)--->类似于json(推荐使用json)
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;
key必须为字符串,而值可以是python所支持的数据类型。
import shelve f = shelve.open(r'shelve.txt') # f['stu1_info']={'name':'alex','age':'18'} # f['stu2_info']={'name':'alvin','age':'20'} # f['school_info']={'website':'oldboyedu.com','city':'beijing'} # # # f.close() print(f.get('stu_info')['age'])
xml模块(* * *)
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单。
不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,
至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml: import xml.etree.ElementTree as ET
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text) #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
自己创建xml文档:
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式 创建xml文档
configparser模块(* *)---操作配置文件
(配置文件)来看一个好多软件的常见文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
用python生成一个这样的配置文件:
"""用Python生成配置文件""" # import configparser # # config = configparser.ConfigParser() # config["DEFAULT"] = {'ServerAliveInterval': '45', # 'Compression': 'yes', # 'CompressionLevel': '9'} # # config['bitbucket.org'] = {} # config['bitbucket.org']['User'] = 'hg' # # # config['topsecret.server.com'] = {} # topsecret = config['topsecret.server.com'] # topsecret['Host Port'] = '50022' # mutates the parser # topsecret['ForwardX11'] = 'no' # same here # # # config['DEFAULT']['ForwardX11'] = 'yes' # #注意写入文件方式 # with open('configFile', 'w') as cf: # config.write(cf)
"""Python对已有配置文件进行增删改查""" import configparser config = configparser.ConfigParser() #---------------------------------------------# 查 # print(config.sections()) #[] config.read('configFile') # print(config.sections()) #['bitbucket.org', 'topsecret.server.com'] 默认的[DEFAULT]不会显示,而[DEFAULT]内容已经加入到其他键内 # print('bytebong.com' in config)# False # # # print(config['bitbucket.org']['User']) # hg # print(config['bitbucket.org']['serveraliveinterval']) # 45 # # print(config['DEFAULT']['Compression']) #yes # # print(config['topsecret.server.com']['ForwardX11']) #no # # # for key in config['bitbucket.org']: # print(key) # # # user # # serveraliveinterval # # compression # # compressionlevel # # forwardx11 # # # print(config.options('bitbucket.org')) #['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11'] # print(config.items('bitbucket.org')) #[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')] # # print(config.get('bitbucket.org','compression')) #yes # # # #---------------------------------------------删,改,增(config.write(open('i.cfg', "w"))) # # # config.add_section('xiong') #增加键 # # config.remove_section('topsecret.server.com') #移除键[topsecret.server.com]及下面内容 # config.remove_option('bitbucket.org','user') #移除键下面user # # config.set('bitbucket.org','k1','11111') #向[bitbucket.org]键内添加内容 # ##这种方法打开的open() 文件没有赋值给句柄f 不用关闭 # config.write(open('i.cfg', "w"))
hashlib模块(* *)
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串
(通常用16进制的字符串表示)。
举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要
是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了你的文章,并发表为'how to use python hashlib - by Bob',
你可以一下子指出Bob篡改了你的文章,因为根据'how to use python hashlib - by Bob'计算出的摘要不同于原始文章的摘
要。
可见,摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人
篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,
但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?'.encode('utf-8')) print(md5.hexdigest()) #d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in '.encode('utf-8')) md5.update('python hashlib?'.encode('utf-8')) print(md5.hexdigest()) #d26a53750bc40b38b65a520292f69306
试试改动一个字母,看看计算的结果是否完全不同。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in '.encode('utf-8')) sha1.update('python hashlib?'.encode('utf-8')) print(sha1.hexdigest())
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。
有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映
射到一个有限的集合中。这种情况称为碰撞,比如Bob试图根据你的摘要反推出一篇文章'how to learn hashlib in python -
by Bob',并且这篇文章的摘要恰好和你的文章完全一致,这种情况也并非不可能出现,但是非常非常困难。
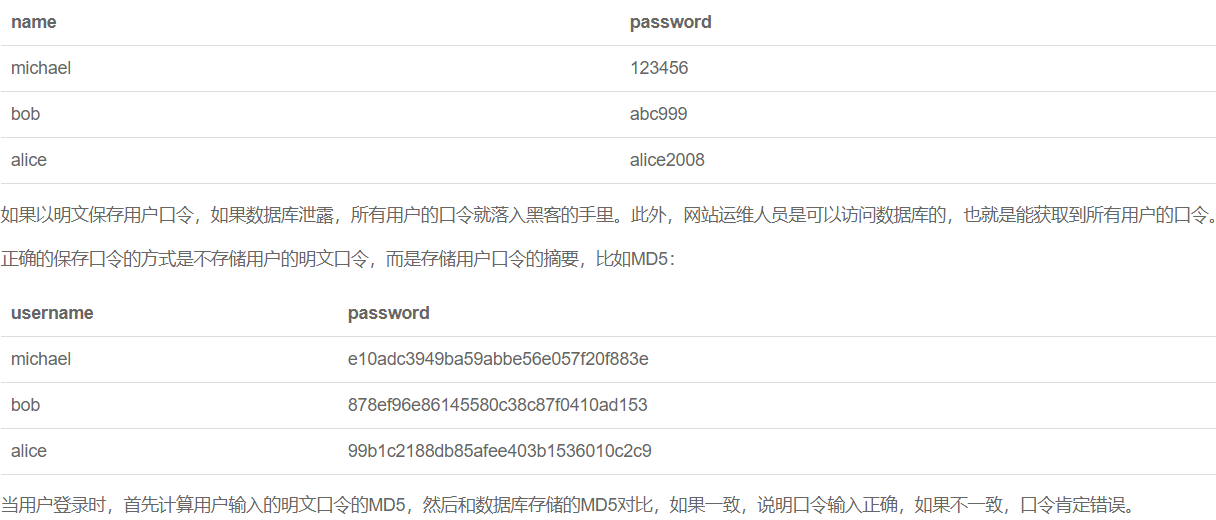
摘要算法应用
摘要算法能应用到什么地方?举个常用例子:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
import hashlib m=hashlib.md5()# m=hashlib.sha256() m.update('hello'.encode('utf8')) print(m.hexdigest()) #5d41402abc4b2a76b9719d911017c592 m.update('alvin'.encode('utf8')) print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af m2=hashlib.md5() m2.update('helloalvin'.encode('utf8')) print(m2.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。
所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib # ######## 256 ######## hash = hashlib.sha256('898oaFs09f'.encode('utf8')) hash.update('alvin'.encode('utf8')) #添加自定义key print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
import hmac h = hmac.new('alvin'.encode('utf8')) h.update('hello'.encode('utf8')) print (h.hexdigest()) #320df9832eab4c038b6c1d7ed73a5940
采用MD5存储口令是否就一定安全呢?也不一定。假设你是一个黑客,已经拿到了存储MD5口令的数据库,如何通过MD5反推
用户的明文口令呢?暴力破解费事费力,真正的黑客不会这么干。
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的
MD5值,得到一个反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456' '21218cca77804d2ba1922c33e0151105': '888888' '5f4dcc3b5aa765d61d8327deb882cf99': 'password'
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方
法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
def calc_md5(password): return get_md5(password + 'the-Salt')
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令
是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的
MD5。
MD5口令加盐
import hashlib, random SALT = "1314" def get_md5(s): return hashlib.md5(s.encode('utf-8')).hexdigest() class User(object): def __init__(self, username, password): self.username = username # self.salt = ''.join([chr(random.randint(48, 122)) for i in range(20)]) self.salt = "1314" self.password = get_md5(password + self.salt) db = { 'michale': User('michale', '123456'), 'bob': User('bob', 'abc999'), 'alice': User('alice', 'alice2008') } def login(username, password): user = db[username] return user.password == get_md5(password+SALT) print(get_md5("123456")) #e10adc3949ba59abbe56e057f20f883e print(login('michale',"123456"))
subprocess模块(* * * *)
当我们需要调用系统的命令的时候,最先考虑的os模块。用os.system()和os.popen()来进行操作。但是这两个命令过于简单,
不能完成一些复杂的操作,如给运行的命令提供输入或者读取命令的输出,判断该命令的运行状态,管理多个命令的并行等
等。这时subprocess中的Popen命令就能有效的完成我们需要的操作。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes.
This module intends to replace several other, older modules and functions, such as: os.system、os.spawn*、os.popen*、popen2.*、commands.*
这个模块一个类:Popen。
#Popen它的构造函数如下: subprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None,stderr=None,
preexec_fn=None, close_fds=False, shell=False,cwd=None, env=None, universal_newlines=False,
startupinfo=None, creationflags=0)
# 参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。 # 如果是序列类型,第一个元素通常是可执行文件的路径。我们也可以显式的使用executeable参 # 数来指定可执行文件的路径。在windows操作系统上,Popen通过调用CreateProcess()来创 # 建子进程,CreateProcess接收一个字符串参数,如果args是序列类型,系统将会通过 # list2cmdline()函数将序列类型转换为字符串。 # # # 参数bufsize:指定缓冲。我到现在还不清楚这个参数的具体含义,望各个大牛指点。 # # 参数executable用于指定可执行程序。一般情况下我们通过args参数来设置所要运行的程序。如 # 果将参数shell设为True,executable将指定程序使用的shell。在windows平台下,默认的 # shell由COMSPEC环境变量来指定。 # # 参数stdin, stdout, stderr分别表示程序的标准输入、输出、错误句柄。他们可以是PIPE, # 文件描述符或文件对象,也可以设置为None,表示从父进程继承。 # # 参数preexec_fn只在Unix平台下有效,用于指定一个可执行对象(callable object),它将 # 在子进程运行之前被调用。 # # 参数Close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会 # 继承父进程的输入、输出、错误管道。我们不能将close_fds设置为True同时重定向子进程的标准 # 输入、输出与错误(stdin, stdout, stderr)。 # # 如果参数shell设为true,程序将通过shell来执行。 # # 参数cwd用于设置子进程的当前目录。 # # 参数env是字典类型,用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父 # 进程中继承。 # # 参数Universal_newlines:不同操作系统下,文本的换行符是不一样的。如:windows下 # 用’/r/n’表示换,而Linux下用’/n’。如果将此参数设置为True,Python统一把这些换行符当 # 作’/n’来处理。 # # 参数startupinfo与createionflags只在windows下用效,它们将被传递给底层的 # CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等。 parameter
logging模块(* * * * *)
https://cuiqingcai.com/6080.html
日志记录的重要性
在开发过程中,如果程序运行出现了问题,我们是可以使用我们自己的 Debug 工具来检测到到底是哪一步出现了问题,如果出现了问题的话,是很容易排查的。但程序开发完成之后,我们会将它部署到生产环境中去,这时候代码相当于是在一个黑盒环境下运行的,我们只能看到其运行的效果,是不能直接看到代码运行过程中每一步的状态的。在这个环境下,运行过程中难免会在某个地方出现问题,甚至这个问题可能是我们开发过程中未曾遇到的问题,碰到这种情况应该怎么办?
如果我们现在只能得知当前问题的现象,而没有其他任何信息的话,如果我们想要解决掉这个问题的话,那么只能根据问题的现象来试图复现一下,然后再一步步去调试,这恐怕是很难的,很大的概率上我们是无法精准地复现这个问题的,而且 Debug 的过程也会耗费巨多的时间,这样一旦生产环境上出现了问题,修复就会变得非常棘手。但这如果我们当时有做日志记录的话,不论是正常运行还是出现报错,都有相关的时间记录,状态记录,错误记录等,那么这样我们就可以方便地追踪到在当时的运行过程中出现了怎样的状况,从而可以快速排查问题。
因此,日志记录是非常有必要的,任何一款软件如果没有标准的日志记录,都不能算作一个合格的软件。作为开发者,我们需要重视并做好日志记录过程。
日志记录的流行框架
那么在 Python 中,怎样才能算作一个比较标准的日志记录过程呢?或许很多人会使用 print 语句输出一些运行信息,然后再在控制台观察,运行的时候再将输出重定向到文件输出流保存到文件中,这样其实是非常不规范的,在 Python 中有一个标准的 logging 模块,我们可以使用它来进行标注的日志记录,利用它我们可以更方便地进行日志记录,同时还可以做更方便的级别区分以及一些额外日志信息的记录,如时间、运行模块信息等。
接下来我们先了解一下日志记录流程的整体框架。
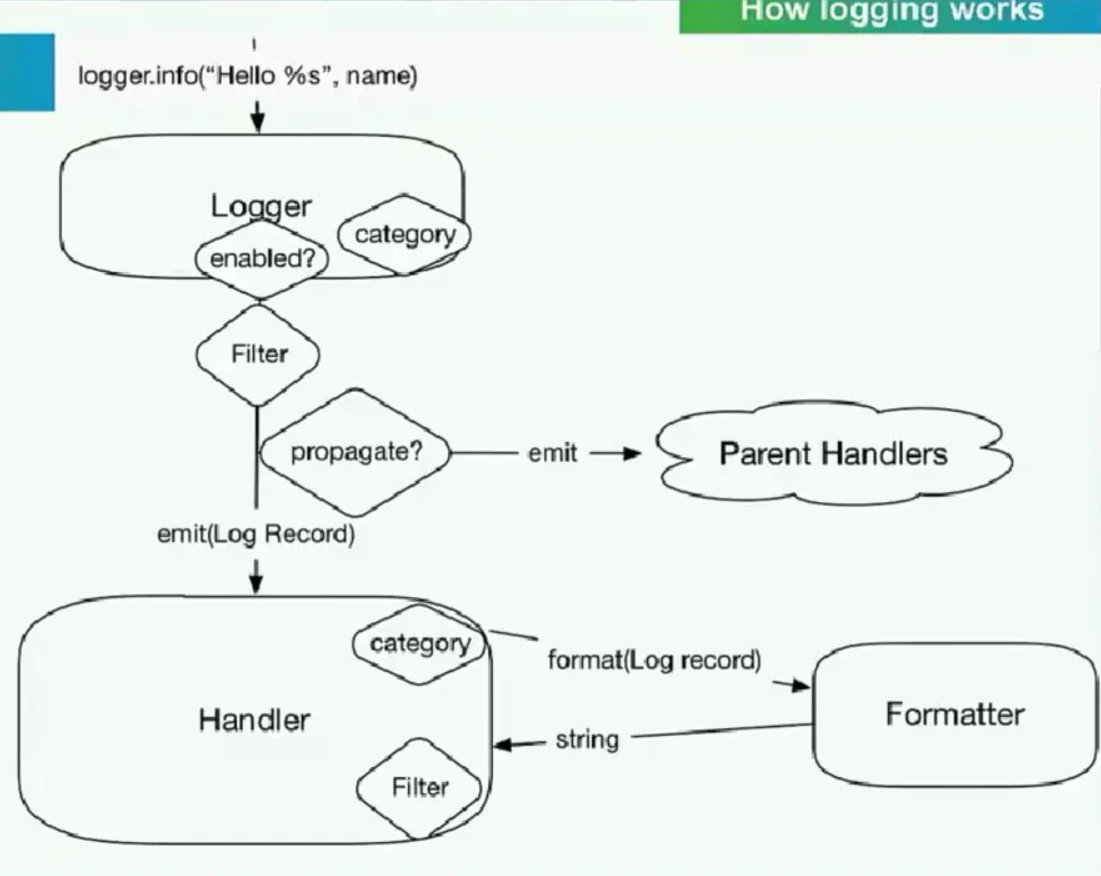
如图所示,整个日志记录的框架可以分为这么几个部分:
- Logger:即 Logger Main Class,是我们进行日志记录时创建的对象,我们可以调用它的方法传入日志模板和信息,来生成一条条日志记录,称作 Log Record。
- Log Record:就代指生成的一条条日志记录。
- Handler:即用来处理日志记录的类,它可以将 Log Record 输出到我们指定的日志位置和存储形式等,如我们可以指定将日志通过 FTP 协议记录到远程的服务器上,Handler 就会帮我们完成这些事情。
- Formatter:实际上生成的 Log Record 也是一个个对象,那么我们想要把它们保存成一条条我们想要的日志文本的话,就需要有一个格式化的过程,那么这个过程就由 Formatter 来完成,返回的就是日志字符串,然后传回给 Handler 来处理。
- Filter:另外保存日志的时候我们可能不需要全部保存,我们可能只需要保存我们想要的部分就可以了,所以保存前还需要进行一下过滤,留下我们想要的日志,如只保存某个级别的日志,或只保存包含某个关键字的日志等,那么这个过滤过程就交给 Filter 来完成。
- Parent Handler:Handler 之间可以存在分层关系,以使得不同 Handler 之间共享相同功能的代码。
以上就是整个 logging 模块的基本架构和对象功能,了解了之后我们详细来了解一下 logging 模块的用法。
日志记录的相关用法
总的来说 logging 模块相比 print 有这么几个优点:
- 可以在 logging 模块中设置日志等级,在不同的版本(如开发环境、生产环境)上通过设置不同的输出等级来记录对应的日志,非常灵活。
- print 的输出信息都会输出到标准输出流中,而 logging 模块就更加灵活,可以设置输出到任意位置,如写入文件、写入远程服务器等。
- logging 模块具有灵活的配置和格式化功能,如配置输出当前模块信息、运行时间等,相比 print 的字符串格式化更加方便易用。
下面我们初步来了解下 logging 模块的基本用法,先用一个实例来感受一下:
import logging logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
输出:
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
可见,默认情况下python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认
的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),
默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置
import logging,os
LOG_FORMAT = "%(asctime)s %(name)s %(levelname)s %(pathname)s %(message)s "#配置输出日志格式
DATE_FORMAT = '%Y-%m-%d %H:%M:%S %a ' #配置输出时间的格式,注意月份和天数不要搞乱了
logging.basicConfig(level=logging.DEBUG,
format=LOG_FORMAT,
datefmt = DATE_FORMAT ,
filename=r"testLog.log", #有了filename参数就不会直接输出显示到控制台,而是直接写入文件
filemode="w")
logging.debug("msg1")
logging.info("msg2")
logging.warning("msg3")
logging.error("msg4")
logging.critical("msg5")
./cat /tmp/testLog.log 查看输出:
2020-03-12 14:22:53 Thu root DEBUG C:/Users/xiong/Desktop/Python编程/老男孩Python全栈/Python基础到进阶/Py06 模块和包/logging模块/test1.py msg1 2020-03-12 14:22:53 Thu root INFO C:/Users/xiong/Desktop/Python编程/老男孩Python全栈/Python基础到进阶/Py06 模块和包/logging模块/test1.py msg2 2020-03-12 14:22:53 Thu root WARNING C:/Users/xiong/Desktop/Python编程/老男孩Python全栈/Python基础到进阶/Py06 模块和包/logging模块/test1.py msg3 2020-03-12 14:22:53 Thu root ERROR C:/Users/xiong/Desktop/Python编程/老男孩Python全栈/Python基础到进阶/Py06 模块和包/logging模块/test1.py msg4 2020-03-12 14:22:53 Thu root CRITICAL C:/Users/xiong/Desktop/Python编程/老男孩Python全栈/Python基础到进阶/Py06 模块和包/logging模块/test1.py msg5
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:即日志输出的文件名,如果指定了这个信息之后,实际上会启用 FileHandler,而不再是 StreamHandler,这样日志信息便会输出到文件中了。
filemode:这个是指定日志文件的写入方式,有两种形式,一种是 w,一种是 a,分别代表清除后写入和追加写入。
format:指定日志信息的输出格式。
style:如果 format 参数指定了,这个参数就可以指定格式化时的占位符风格,如 %、{、$ 等。
datefmt:指定日期时间格式。
level:设置的日志级别
stream:在没有指定 filename 的时候会默认使用 StreamHandler,这时 stream 可以指定初始化的文件流。
sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
handlers:可以指定日志处理时所使用的 Handlers,必须是可迭代的。
format参数中可能用到的格式化串:
- %(levelno)s:打印日志级别的数值。
- %(levelname)s:打印日志级别的名称。
- %(pathname)s:打印当前执行程序的路径,其实就是sys.argv[0]。
- %(filename)s:打印当前执行程序名。
- %(funcName)s:打印日志的当前函数。
- %(lineno)d:打印日志的当前行号。
- %(asctime)s:打印日志的时间。
- %(thread)d:打印线程ID。
- %(threadName)s:打印线程名称。
- %(process)d:打印进程ID。
- %(processName)s:打印线程名称。
- %(module)s:打印模块名称。
- %(message)s:打印日志信息。
logger对象
在这里我们首先引入了 logging 模块,然后进行了一下基本的配置,这里通过 basicConfig 配置了 level 信息和 format 信息,这里 level 配置为 INFO 信息,即只输出 INFO 级别的信息。另外这里指定了 format 格式的字符串,包括 asctime、name、levelname、message 四个内容,分别代表运行时间、模块名称、日志级别、日志内容,这样输出内容便是这四者组合而成的内容了,这就是 logging 的全局配置。
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
(1)Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)。
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
re模块(* * * * *)
https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re.match()函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.match(pattern, string, flags=0) pattern 匹配的正则表达式 string 要匹配的字符串。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符如下 re.I 使匹配对大小写不敏感 re.L 做本地化识别(locale-aware)匹配 re.M 多行匹配,影响 ^ 和 $ re.S 使 . 匹配包括换行在内的所有字符 re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
re.search()方法
re.search 扫描整个字符串并返回第一个成功的匹配。
re.search(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
re.findall() (* * * * *)
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
re.findall(re_regular,string[, pos[, endpos]])
re_regular: 正则表达式
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
元字符之 . ^ $ * + ? { }
import re
ret=re.findall('a..in','helloalvin')
print(ret) #['alvin']
ret=re.findall('^a...n','alvinhelloawwwn')
print(ret) #['alvin']
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret) #['awwwn']
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret) #['awwwn']
ret=re.findall('abc*','abcccc') # *贪婪匹配[0,+oo]
print(ret) #['abcccc']
ret=re.findall('abc+','abccc') # +[1,+oo]
print(ret) #['abccc']
ret=re.findall('abc?','abccc') # ?[0,1]
print(ret)#['abc']
ret=re.findall('abc{1,4}','abccc')
print(ret) #['abccc'] 贪婪匹配
注意:前面的 *,+,? 等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
ret=re.findall('abc*?','abcccccc')
print(ret) #['ab']
元字符之字符集[]:
ret=re.findall('a[bc]d','acd')
print(ret) #['acd']
ret=re.findall('[a-z]','acd')
print(ret) #['a', 'c', 'd']
ret=re.findall('[.*+]','a.cd+')
print(ret) #['.', '+']
#在字符集里有功能的符号: - ^ \
ret=re.findall('[1-9]','45dha3')
print(ret) #['4', '5', '3']
ret=re.findall('[^ab]','45bdha3')
print(ret) #['4', '5', 'd', 'h', '3']
ret=re.findall('[\d]','45bdha3')
print(ret) #['4', '5', '3']
元字符之转义符 \
反斜杠后边跟元字符去除特殊功能,比如 \. 表示匹配 .
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数;它相当于类 [0-9]。 \D 匹配任何非数字字符;它相当于类 [^0-9]。 \s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。 \S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。 \w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 \W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_] \b 匹配一个特殊字符边界,比如空格 ,&,#等
ret=re.findall('I\b','I am LIST')
print(ret)#[]
ret=re.findall(r'I\b','I am LIST')
print(ret)#['I']
现在我们聊一聊 \ ,先看下面两个匹配:
import re
# ret = re.findall("c\l", 'abc\le') #报错
# print(ret)
# ret = re.findall('c\\l', 'abc\le') #报错
# print(ret)
# ret = re.findall('c\\\\l', 'abc\le')
# print(ret) # ['c\\l']
ret = re.findall(r'c\\l', 'abc\le') #推荐r'c\\l'
print(ret) # ['c\\l']
# -----------------------------eg2:
# 之所以选择\b是因为\b在ASCII表中是有意义的
# m = re.findall('\bblow', 'blow')
# print(m)
m = re.findall(r'\bblow', 'blow')
print(m)
元字符之分组()
#无名分组
m = re.findall(r'(ad)+', 'add')
print(m)
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。提取子串非常有用。
来看一个更凶残的例子(匹配 19:05:30 时分秒):
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('19', '05', '30')
#具名分组
#(?P<name>正则表达式) #name是一个合法的标识符
ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')
print(ret.group()) #23/com
print(ret.group('id')) #23
元字符之|
ret=re.search('(ab)|\d','rabhdg8sd')
print(ret.group()) #ab
re.split(re正则,字符串)
以正则匹配项为分隔
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
re正则表达式匹配练习
1.匹配html的标签
import re
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")
#还可以在分组中利用?<name>的形式给分组起名字
#获取的匹配结果可以直接用group('名字')拿到对应的值
print(ret.group('tag_name')) #结果 :h1
print(ret.group()) #结果 :<h1>hello</h1>
ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
#如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
#获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group(1))
print(ret.group()) #结果 :<h1>hello</h1>
2.整数匹配
collections模块(* * * * *)
参考:https://www.liaoxuefeng.com/wiki/897692888725344/973805065315456
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple ---命名的元组
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
>>> isinstance(p, Point) True >>> isinstance(p, tuple) True
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque ---高效的列表插入删除
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的 append()和 pop()外,还支持 appendleft()和 popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict ---改进的字典
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,返回默认值 'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict ---有序的字典
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的顺序返回 ['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value)
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出,字符'g'、'm'、'r'各出现了两次,其他字符各出现了一次。
Counter的所有方法总结:
>>> from collections import Counter
>>> list = ['a','b','a','c','d','a','a','b']
>>> c = Counter(list)
>>> c
Counter({'a': 4, 'b': 2, 'c': 1, 'd': 1})
>>> c.values()
dict_values([4, 2, 1, 1])
## most_common([n])方法:
#从最常见到最不常见的列表中,列出n个最常见的元素及其数量。 如果省略n或None,most_common() 返回计数器中的所有元素。 具有相同计数的元素可以任意排序:
>>> c.most_common(2)
[('a', 4), ('b', 2)]
>>> c.most_common()
[('a', 4), ('b', 2), ('c', 1), ('d', 1)]
## elements()方法:
#将元素返回一个迭代器,每次重复的次数与它的次数相同。 元素以任意顺序返回。 如果一个元素的数量少于一#个,elements()会忽略它。
>>> l = Counter(hello=4,happy=3,world=2)
>>> l
Counter({'hello': 4, 'happy': 3, 'world': 2})
>>> list(l)
['hello', 'happy', 'world']
>>> list(l.elements())
['hello', 'hello', 'hello', 'hello', 'happy', 'happy', 'happy', 'world', 'world']
## subtract([iterable-or-mapping])方法:
#元素从一个迭代器或另一个映射(或计数器)中减去。 像dict.update()一样,但减去计数而不是替换它#们。 输入和输出都可以是零或负数。
>>> c = Counter(a=4, b=2, c=0, d=-2)
>>> d = Counter(a=1, b=2, c=3, d=4)
>>> c.subtract(d)
>>> c
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号