SQL(细构化查询语言)
命名
- SQL不区分大小写,但关键字不推荐小写;
- 不使用中文命名
- 命名需要简单明了,见名知意
注释
- 每条SQL语句需尽量加上注释
- 注释描述当前语句的作用,并非解释SQL语句本身
数据类型
- 整数
- BIT
- INT (长整型)
- SMALLINT (短整型)
- 浮点型
- FLOAT(n) 浮点型,精度至少为 n 位数字
- NUMERIC (p,d) 定点数,由p位数字组成,小数后面有d位数字
- 字符
- CHAR(n) 长度为n的定长字符串
- VARCHAR 最大长度为n的变长字符串
- 时间/日期
- DATE 日期,格式为 YYYY--MM--DD
- TIME 时间,格式为 HH:MM:SS
表的结构
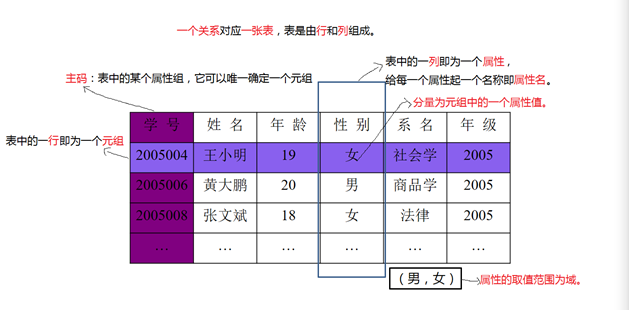
- 关系(Relation) :一张表就是一个关系.表结构被称为 关系模式.
- 元组(Tuple) : 表中的一行即为一个数组.
- 属性(Attribute) : 表中的一列即为一个属性,属性的取值范围则称为该属性的域
- 主码(Key) : 表中的某个属性组,可以用来确定唯一的元组.
- 分量(Component) : 元组中的一个属性值
创建数据库
CREATE DATABASE "e:\tempdb.fdb" ; (数据库的名称)
删除数据库
drop database
创建表
CREATE TABLE "your_table" (表名)
删除表
DROP TABLE "your_table" (表名)
填入数据
INSERT INTO "your_table"(表名) (column_name1,column_name2 [列名],...)
VALUES('value1','value2' [数据],...);
更新数据
UPDATE table_name(需要更新的表的名称)
SET column_name=newvalue(指定要做的改变)
WHERE sno = '20110135'(辅助定位要改变的数据);
删除记录
DELETE FROM your_table()
WHERE column_name = somevalue(指明要删除的记录);
约束
主码约束----数据库中,类似于身份证号码能唯一标识元组的属性,这样的属性称为主码
RPIMARY KEY
外码约束----将一张表的主码值添加另一张表中,创建两张表的联系,这个外来户就是外码
FOREIGN KEY
唯一约束----当前表中已创建主键,又要保证其他属性的域唯一时,可以使用唯一约束.
UNIQUE
非空约束----非空约束是确定列中是否允许空值的关键字,不允许为空.
NOT NULL
默认约束----默认约束可以自定义一个值,当用户没有输入值时,填入自定义的值
DEFAULT
查询
类型
- 投影查询
- 选择查询
- 聚合查询
查询指定表格中所有列的数据
SELECT*FROM 表名;
查询特定几列的数据
SELECT name,age,gender(属性名) FROM employee;
更改属性(列名)
SELECT name(原始属性名) AS EmpName(更改的) FROM employee;
按属性筛选(多个判断条件通过 AND[与] OR[或] 来联合)
SELECT*FROM employee(表名) WHERE gender='女'(条件);
范围型查询
SELECT*FROM employee(表名) WHERE gender='男' AND age>=30 AND AGE<=35(条件)
SELECT*FROM employee WHERE age IN(30,31,32,33,34,35,36)( IN后面跟集合 );
//可以使用NOT IN来反转结果
SELECT*FROM employee WHERE age BETWEEN 30 AND 35;//不同版本边境值是否包含不同,不建议使用
模糊查找(% 百分号是位置数量的未知字符的替身; _ 下划线是一个未知字符的替身)
SELECT*FROM employee WHERE name LIKE '张%'( LIKE关键字搭配通配符使用可模糊查找)
双层查找
SELECT*FROM employee WHERE entry_time IN
(SELECT ertry_time FROM employee WHERE name='张三')
排序
SELECT*FROM employee WHERE dept='人力资源部' ORDER BY name,age(两个属性排序用 " , "分割) ASC;
(ASC----升序; DESC----降序)
聚合查询
计算函数
COUNT( 列名 ) 求取非空值行数
COUNT ( DISTINCT 列名) 求取排除空值和重复行的行数
SUM ( 列名 ) 求取各行的和
AVG ( 列名 ) 求取各行的平均值
MAX ( 列名 ) 求取各行的最大值
MIN (列名) 求取各行的最小值
分组统计

SELECT gender(属性), count(*) as C(聚合属性重命名) employee(表名) GROUP BY gender;
分组后的二次筛选
SELECT gender,count(*) as C(聚合属性重命名) employee
WHERE(分组前筛选) age>=25 and age<=30 GROUP BY dept
HAVING count(*)>0(使用HAVING,可以进行分组后的二次筛选)
ORDER BY count(*) desc
提升查询效率
- 分布式集群(部署大量的数据库,每个数据库只记录当前的实时记录,隔一段时间,数据库的数据同步一次)
- 拆分表 : 数据库里面的数据按照不同年份,月份存储在不同的表中
- 索引 : 对当张表进行一些特殊的优化,提升查询效率
索引 (一张表最多可以建250个索引,一个聚集索引)
- 聚集索引
- 非聚集索引
索引的好处
- 索引可以大大加快数据的检索
索引的坏处
- 索引的创建会占用物理空间,属于典型的"空间换时间";
- 索引的创建和维护会耗费时间,属于典型的双刃剑
- 会拖慢数据的插入,更新和删除
应用场景
- 经常查询的字段可以加上索引
- 存在大量重复值的字段,没必要增加索引
- 字段里面的数据量太大,也不建议加索引
CREATE ASC(升序) index 索引名 on employee(name)[ 在employye表的name属性上创建索引 ];
设计数据库
- 设计数据库的规则称为范式
- 范式的等级越高受到的约束越严格.规范的每一级别都要满足前一级别.
第一范式(1NF)
- 每个属性确保不可再分,且无重复,确保不能出现复杂表头
第二范式(2NF)
- 每一个非主属性不能部分依赖于主码,即必须完全依赖于主码,确保一张表只描述同一件事
第三范式(3NF)
- 属性不能有传递依赖,即属性不能依赖于其他非主属性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号