机器学习实验5——肿瘤预测(AdaBoost)
实验5 AdaBoost 实操项目:肿瘤预测(AdaBoost)
【实验内容】
基于威斯康星乳腺癌数据集,使用AdaBoost算法实现肿瘤预测。【实验要求】
1.加载sklearn自带的数据集,使用DataFrame形式探索数据。
2.划分训练集和测试集,检查训练集和测试集的平均癌症发生率。
3.配置模型,训练模型,模型预测,模型评估。
(1)构建一棵最大深度为2的决策树弱学习器,训练、预测、评估。
(2)再构建一个包含50棵树的AdaBoost集成分类器(步长为3),训练、预测、评估。
参考:将决策树的数量从1增加到50,步长为3。输出集成后的准确度。
(3)将(2)的性能与弱学习者进行比较。
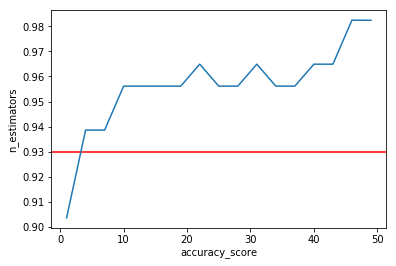
4.绘制准确度的折线图,x轴为决策树的数量,y轴为准确度。AdaBoostClassifier参数解释:
-
base_estimator:弱分类器,默认是CART分类树:DecisionTressClassifier
-
algorithm:在scikit-learn实现了两种AdaBoost分类算法,即SAMME和SAMME.R, SAMME就是AdaBoost算法,指Discrete。AdaBoost.SAMME.R指Real AdaBoost,返回值不再是离散的类型,而是一个表示概率的实数值。SAMME.R的迭代一般比SAMME快,默认算法是SAMME.R。因此,base_estimator必须使用支持概率预测的分类器。
-
n_estimator:最大迭代次数,默认50。在实际调参过程中,常常将n_estimator和学习率learning_rate一起考虑。
-
learning_rate:每个弱分类器的权重缩减系数v。fk(x)=fk−1∗ak∗Gk(x)f_k(x)=f_{k-1}a_kG_k(x)f k(x)=f k−1∗a k∗G k(x)。较小的v意味着更多的迭代次数,默认是1,也就是v不发挥作用。
In [1]
#1.加载sklearn自带的数据集,使用DataFrame形式探索数据。
from sklearn.datasets import load_breast_cancer
import pandas as pd
load_cancer=load_breast_cancer()
cancer_data=pd.DataFrame(load_cancer.data)
cancer_target=pd.DataFrame(load_cancer.target)
print(cancer_data[:3],'\n',cancer_target[:3])
#2.划分训练集和测试集,检查训练集和测试集的平均癌症发生率。
from sklearn.model_selection import train_test_split
data_train,data_test,target_train,target_test=train_test_split(cancer_data,cancer_target,test_size=0.2)
#检查癌症发生率,即求平均值
test_mean=target_test[0].mean()
train_mean=target_train[0].mean()
print('训练集癌症发生率为:',train_mean)
print('测试集癌症发生率为:',test_mean) 0 1 2 3 4 5 6 7 8 \
0 17.99 10.38 122.8 1001.0 0.11840 0.27760 0.3001 0.14710 0.2419
1 20.57 17.77 132.9 1326.0 0.08474 0.07864 0.0869 0.07017 0.1812
2 19.69 21.25 130.0 1203.0 0.10960 0.15990 0.1974 0.12790 0.2069
9 ... 20 21 22 23 24 25 26 27 \
0 0.07871 ... 25.38 17.33 184.6 2019.0 0.1622 0.6656 0.7119 0.2654
1 0.05667 ... 24.99 23.41 158.8 1956.0 0.1238 0.1866 0.2416 0.1860
2 0.05999 ... 23.57 25.53 152.5 1709.0 0.1444 0.4245 0.4504 0.2430
28 29
0 0.4601 0.11890
1 0.2750 0.08902
2 0.3613 0.08758
[3 rows x 30 columns]
0
0 0
1 0
2 0
训练集癌症发生率为: 0.6307692307692307
测试集癌症发生率为: 0.6140350877192983
In [2]
#3.配置模型,训练模型,模型预测,模型评估。
#(1)构建一棵最大深度为2的决策树弱学习器,训练、预测、评估。
from sklearn import tree # 导入决策树包
clf_low = tree.DecisionTreeClassifier(max_depth=2) #加载决策树模型
clf_low.fit(data_train,target_train)#训练
pred_low=clf_low.predict(data_test)#预测
from sklearn.metrics import accuracy_score
print('tree_Accuracy:%s'%accuracy_score(target_test,pred_low))#评估
print('*********************')
#(2)再构建一个包含50棵树的AdaBoost集成分类器(步长为3),训练、预测、评估。
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
scores=[]
for i in range(1,51,3):
clf=AdaBoostClassifier(n_estimators=i)
clf.fit(data_train,target_train)
pred=clf.predict(data_test)
scores.append(accuracy_score(target_test,pred))
print('n_estimators=',i,'\nAccuracy=',accuracy_score(target_test,pred))
# 参考:将决策树的数量从1增加到50,步长为3。输出集成后的准确度。
#(3)将(2)的性能与弱学习者进行比较。
import matplotlib.pyplot as plt
import numpy as np
plt.figure()
plt.xlabel('accuracy_score')
plt.ylabel('n_estimators')
plt.axhline(y=accuracy_score(target_test,pred_low),c='red')
plt.plot(range(1,51,3),scores)
plt.show()tree_Accuracy:0.9298245614035088
*********************
n_estimators= 1
Accuracy= 0.9035087719298246
n_estimators= 4
Accuracy= 0.9385964912280702
n_estimators= 7
Accuracy= 0.9385964912280702
n_estimators= 10
Accuracy= 0.956140350877193
n_estimators= 13
Accuracy= 0.956140350877193
n_estimators= 16
Accuracy= 0.956140350877193
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
n_estimators= 19
Accuracy= 0.956140350877193
n_estimators= 22
Accuracy= 0.9649122807017544
n_estimators= 25
Accuracy= 0.956140350877193
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
n_estimators= 28
Accuracy= 0.956140350877193
n_estimators= 31
Accuracy= 0.9649122807017544
n_estimators= 34
Accuracy= 0.956140350877193
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
n_estimators= 37
Accuracy= 0.956140350877193
n_estimators= 40
Accuracy= 0.9649122807017544
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
n_estimators= 43
Accuracy= 0.9649122807017544
n_estimators= 46
Accuracy= 0.9824561403508771
n_estimators= 49
Accuracy= 0.9824561403508771
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:760: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
<Figure size 432x288 with 1 Axes>
 浙公网安备 33010602011771号
浙公网安备 33010602011771号