第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 练习独立完成一个项目 |
Github仓库链接:https://github.com/X1erxes/3123004200
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析(包括学习新技术) | 10 | 8 |
| · Design Spec | · 生成设计文档 | 20 | 23 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 5 | 9 |
| · Design | · 具体设计 | 35 | 42 |
| · Coding | · 具体编码 | 240 | 290 |
| · Code Review | · 代码复审 | 10 | 6 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 25 | 26 |
| · Size Measurement | · 计算工作量 | 5 | 4 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 15 | 10 |
| · 合计 | 450 | 523 |

计算模块接口的设计与实现过程
1. 接口设计
1.1 核心接口定义
1.1.1 文本读取接口
def read_file(filename):
"""
读取指定文件的内容
参数:
filename (str): 文件路径
返回:
str: 文件内容字符串,失败时返回None
"""
1.1.2 文本预处理接口
def preprocess_text(text):
"""
对文本进行预处理,包括分词和去噪
参数:
text (str): 原始文本
返回:
list: 处理后的词汇列表
"""
1.1.3 相似度计算接口
def calculate_similarity(original_words, plagiarized_words):
"""
计算两个文本的相似度
参数:
original_words (list): 原文词汇列表
plagiarized_words (list): 抄袭版词汇列表
返回:
float: 相似度值(0-1)
"""
1.1.4 结果输出接口
def write_result(filename, similarity):
"""
将相似度结果写入文件
参数:
filename (str): 输出文件路径
similarity (float): 相似度值
"""
1.2 接口调用关系
graph TD
A[主程序] --> B[read_file]
A --> C[preprocess_text]
A --> D[calculate_similarity]
A --> E[write_result]
C --> F[jieba.lcut]
D --> G[collections.Counter]
2. 实现过程
2.1 文本读取模块实现
2.1.1 需求分析
- 支持UTF-8编码文件读取
- 具备文件不存在异常处理
- 返回去除空白的文件内容
2.1.2 实现步骤
- 使用
open()函数以UTF-8编码打开文件 - 读取文件全部内容并去除首尾空白字符
- 使用try-except处理文件不存在异常
- 返回处理后的文本内容
def read_file(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
content = f.read().strip()
return content
except FileNotFoundError:
print(f"错误:找不到文件 {filename}")
return None
2.2 文本预处理模块实现
2.2.1 需求分析
- 对中文文本进行准确分词
- 过滤标点符号和停用词
- 返回有意义的词汇列表
2.2.2 实现步骤
- 使用jieba进行中文分词
- 定义标点符号和停用词列表
- 遍历分词结果,过滤无效词汇
- 返回处理后的词汇列表
def preprocess_text(text):
words = jieba.lcut(text)
# 定义要过滤的标点符号和停用词
punctuation = ',。!?;:""''()【】《》、'
stop_words = ['的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很',
'到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这']
# 过滤标点符号和停用词
filtered_words = []
for word in words:
if word not in punctuation and word not in stop_words and len(word) > 0:
filtered_words.append(word)
return filtered_words
2.3 相似度计算模块实现
2.3.1 算法选择
采用Jaccard相似度算法:
- 交集:两个集合共同元素的数量
- 并集:两个集合所有元素的数量
- 相似度:交集/并集
2.3.2 实现步骤
- 使用Counter统计词汇频率
- 计算交集和并集
- 应用Jaccard公式计算相似度
- 处理边界情况(除零错误)
def calculate_similarity(original_words, plagiarized_words):
original_counter = Counter(original_words)
plagiarized_counter = Counter(plagiarized_words)
# 计算交集和并集
intersection = sum((original_counter & plagiarized_counter).values())
union = sum((original_counter | plagiarized_counter).values())
# 计算相似度
if union == 0:
similarity = 0
else:
similarity = intersection / union
return similarity
2.4 结果输出模块实现
2.4.1 需求分析
- 将相似度结果保存到指定文件
- 保留两位小数精度
- 支持UTF-8编码
2.4.2 实现步骤
- 以写入模式打开输出文件
- 格式化相似度值(保留两位小数)
- 写入文件并关闭
def write_result(filename, similarity):
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"{similarity:.2f}\n")
计算模块接口部分的性能改进
1. 性能分析结果
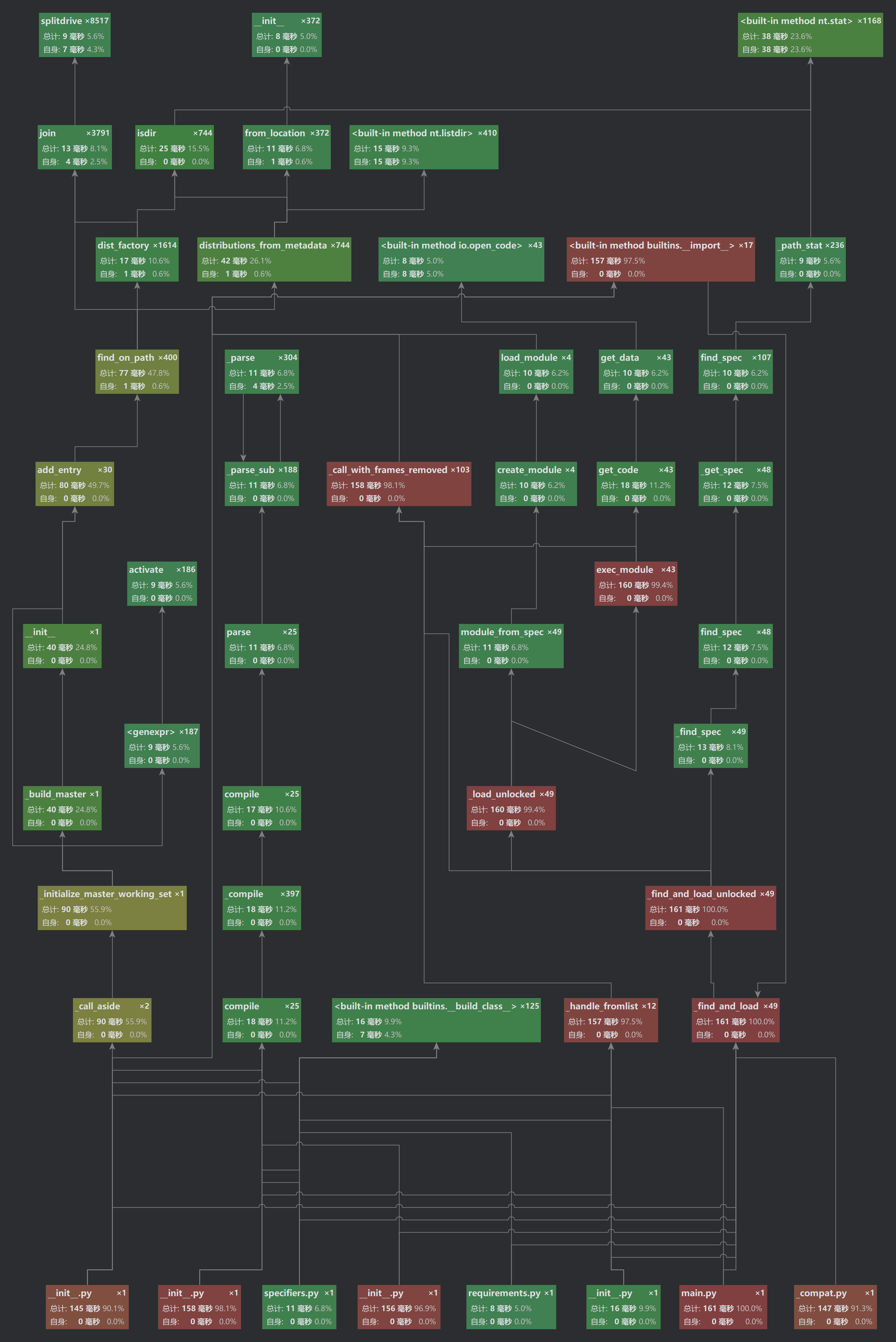
消耗最大的函数:calculate_similarity
2. 性能优化考虑
2.1 算法优化
- 使用Counter提高词频统计效率
- 避免重复计算和内存浪费
2.2 内存管理
- 及时释放不需要的对象
- 合理使用生成器和迭代器
2.3 扩展性设计
- 模块化结构便于更换相似度算法
- 接口设计支持多语言扩展
计算模块部分单元测试展示
1. 完全相同的文本
def test_identical():
"""
测试完全相同的文本
预期相似度:1.0
"""
ori_text = read_file("./test_/identical_orig.txt")
plag_text = read_file("./test_/identical_test.txt")
ori_words = preprocess_text(ori_text)
plag_words = preprocess_text(plag_text)
similarity = calculate_similarity(ori_words, plag_words)
similarity = round(similarity, 2)
assert similarity == 1.0
2. 完全不同的文本
def test_completely_different():
"""
测试完全不同的文本
预期相似度:0.0
"""
ori_text = read_file("./test_/completely_orig.txt")
plag_text = read_file("./test_/completely_test.txt")
ori_words = preprocess_text(ori_text)
plag_words = preprocess_text(plag_text)
similarity = calculate_similarity(ori_words, plag_words)
similarity = round(similarity, 2)
assert similarity == 0
3. 部分重叠的文本
def test_partial_overlap():
"""
测试部分重叠的文本
预期相似度:>= 0.5
"""
ori_text = read_file("./test_/partial_orig.txt")
plag_text = read_file("./test_/partial_test.txt")
ori_words = preprocess_text(ori_text)
plag_words = preprocess_text(plag_text)
similarity = calculate_similarity(ori_words, plag_words)
similarity = round(similarity, 2)
assert similarity >= 0.5
4. 测试结果
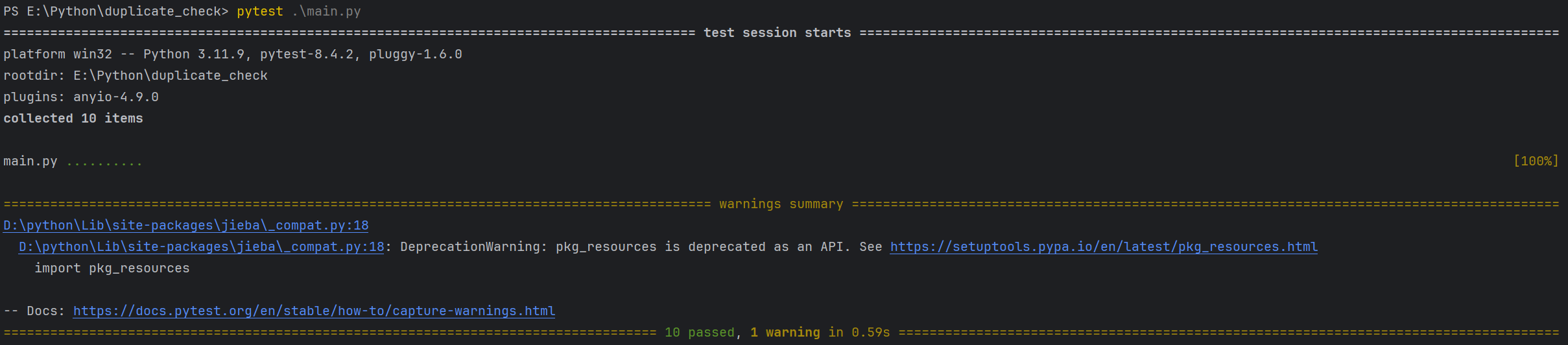
5. 覆盖率报告

计算模块部分异常处理说明
1. 文件操作异常处理
1.1 FileNotFoundError异常处理
1.1.1 异常场景
def read_file(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
content = f.read().strip()
return content
except FileNotFoundError:
print(f"错误:找不到文件 {filename}")
return None
1.1.2 处理机制说明
- 捕获时机:在文件打开操作时捕获
FileNotFoundError - 处理方式:
- 打印详细的错误信息,包含具体文件名
- 返回
None表示读取失败 - 不中断程序执行,允许调用者处理
1.1.3 调用链处理
original_text = read_file(original_file)
if original_text is None:
return # 如果读取失败,主程序直接返回,避免后续处理
1.2 其他文件异常处理
虽然当前代码主要处理FileNotFoundError,但实际应用中可能还需要考虑:
PermissionError:文件权限不足UnicodeDecodeError:文件编码问题IOError:其他I/O相关错误
2. 计算逻辑异常处理
2.1 除零异常处理
2.1.1 异常场景
在Jaccard相似度计算中,当两个文本经过预处理后都为空时,会出现并集为0的情况:
def calculate_similarity(original_words, plagiarized_words):
original_counter = Counter(original_words)
plagiarized_counter = Counter(plagiarized_words)
intersection = sum((original_counter & plagiarized_counter).values())
union = sum((original_counter | plagiarized_counter).values())
if union == 0:
similarity = 0 # 避免除零错误
else:
similarity = intersection / union
return similarity
2.1.2 处理机制说明
- 预防性检查:在除法运算前检查分母是否为0
- 合理默认值:当并集为0时,返回相似度0(表示无相似性)
- 避免异常抛出:通过条件判断避免
ZeroDivisionError
2.2 空数据处理
2.2.1 空文本处理
def preprocess_text(text):
words = jieba.lcut(text)
# ... 过滤逻辑 ...
filtered_words = []
for word in words:
if word not in punctuation and word not in stop_words and len(word) > 0:
filtered_words.append(word)
return filtered_words
2.2.2 处理机制说明
- 空字符串处理:
jieba.lcut("")返回[''],后续通过len(word) > 0过滤 - 空列表处理:返回空列表,交由相似度计算模块处理
3. 参数验证异常处理
3.1 命令行参数验证
def main():
if len(sys.argv) != 4:
print("输入错误")
return
3.2 处理机制说明
- 参数数量检查:确保有正确的参数数量(程序名 + 3个参数)
- 友好提示:提供清晰的错误信息
- 优雅退出:不抛出异常,直接返回
4. 异常传播与处理链
4.1 异常处理链路
main()
├── read_file()
│ └── FileNotFoundError → 打印错误信息 → 返回None
├── preprocess_text()
│ └── 无显式异常处理(依赖jieba库)
├── calculate_similarity()
│ └── 除零预防 → 返回0
└── write_result()
└── 无显式异常处理(文件写入异常)
4.2 异常传播控制
# 在main函数中控制异常传播
def main():
try:
# 主要逻辑
original_text = read_file(original_file)
if original_text is None:
return # 异常情况下提前返回
# 继续处理...
except Exception as e:
print(f"程序执行出错: {e}")
return
使用说明
1. 安装依赖:
pip install -r requirements.txt
2. 运行程序:
python .\main.py .\测试文本\orig.txt .\测试文本\orig_0.8_dis_1.txt .\ans.txt
3. 测试程序:
pytest .\main.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号