Writing - Framework
-
End to end learning and optimization on graphs
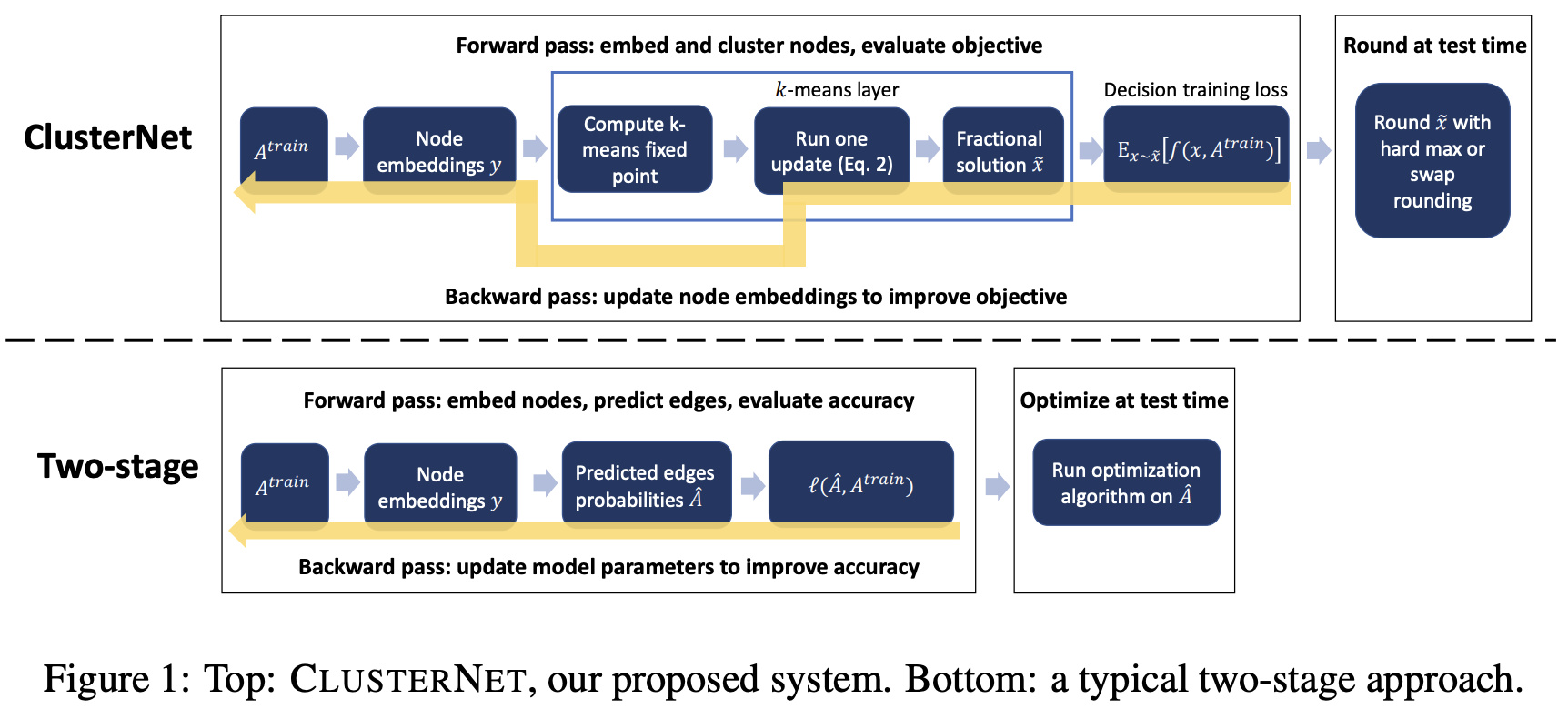
Our proposed CLUSTERNET system (Figure 1) merges two differentiable components into a system that is trained end-to-end. First, a graph embedding layer which uses Atrain and any node features to embed the nodes of the graph into \(\mathbb{R}^p\) . In our experiments, we use GCNs [29]. Second, a layer that performs differentiable optimization. This layer takes the continuous-space embeddings as input and uses them to produce a solution \(x\) to the graph optimization problem. Specifically, we propose to use a layer that implements a differentiable version of \(K\)-means clustering. This layer produces a soft assignment of the nodes to clusters, along with the cluster centers in embedding space.
![image]()
-
Efficiently Solving the Practical Vehicle Routing Problem: A Novel Joint Learning Approach, KDD 2020
The GCN-NPEC model follows the general encoder-decoder perspective. Figure 3 depicts the overall architecture of it. The encoder produces representations of the nodes and edges in graph \(G\). Different from most of the existing models, we have two decoders in the model, and we call them sequential prediction decoder and edge classification decoder. The sequential prediction decoder takes the node representations as input and produces a sequence \(\pi\) as the solution for a VRP instance. While the classification decoder is used to output a probability matrix that denotes the probabilities of the edges being present for vehicle routes, which can also be converted to the solution for a VRP instance. In this way, we use \(\pi\) as the ground-truth (label) of the output of the classification decoder. While training the model, we use a joint strategy, which combines reinforcement and supervised learning manners.
这篇论文的结构是encoder-decoder,结构清楚,值得借鉴。
![image]()
-
Grain: Improving Data Efficiency of Graph Neural Networks via Diversified Influence Maximization, VLDB 2021
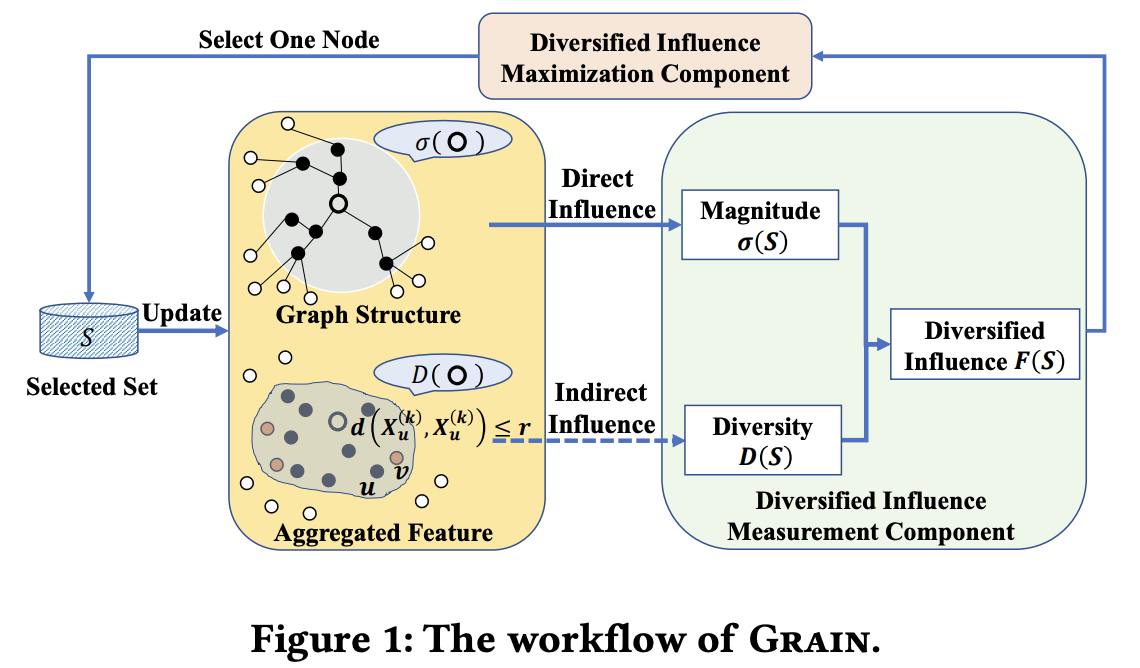
In this section, we present Grain, a new data selection framework for GNNs. As illustrated in Figure 1, at each round of data selection, Grain takes as input a graph \(G = (V, E)\), feature matrix \(X\), and computes the proposed influence and diversity measurements based on the direct and indirect influence over graph structure and 𝑘-steps aggregated embedding \(X^{(𝑘)}\), respectively. Next, Grain combines the influence and diversity into a unified criterion — maximizing the diversified influence and selects a node based on this new criterion. The procedure is repeated until the labeling budget B exhausts. Below, we introduce each component of Grain in detail.
![image]()
-
PARETO SET LEARNING FOR NEURAL MULTI-OBJECTIVE COMBINATORIAL OPTIMIZATION, ICLR 2022
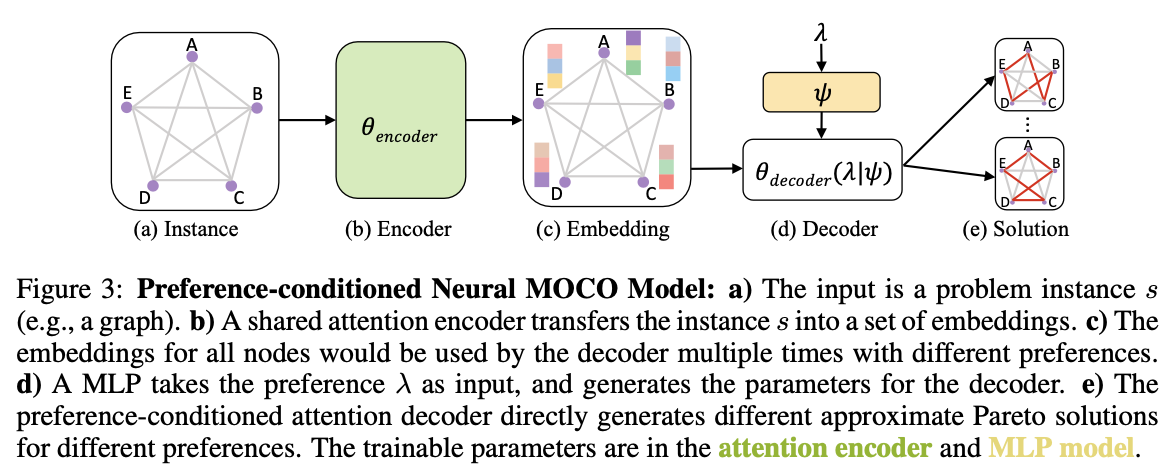
We propose to use an Attention Model (AM) (Kool et al., 2019) as our basic encoder-decoder model as shown in Figure 3. For the MOCO problems considered in this work, a preference-agnostic encoder is capable to transfer problem instances into embeddings (e.g., embedding for all cities) used in the preference-conditioned decoder. In our model, only the decoder’s parameters θdecoder(\(\lambda\)) are conditioned on the preference \(\lambda\):
![image]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号