HTTP缓存
本文是《HTTP权威指南》读书笔记
Web缓存是可以自动保存常见文档副本的设备。当Web请求抵达缓存时,如果本地在“已缓存”的的副本,就可以从本地存储设备而不是原始服务器中提取这个文档。使用缓存可以有以下优点:
- 缓存节省了冗余的数据的传输,节省了网络费用;
- 缓解了网络瓶颈问题,不需要更多的带宽就可以更快地加载页面;
- 缓存降低了对原始服务器的要求, 让服务器可以快速的响应,避免过载出现;
- 缓存降低了距离时延;
但缓存不能保存世界上每一份文档的副本,因此会出现两种情况:可以用已有副本为某些到达缓存的请求提供服务,这叫缓存命中,其他一些到达缓存的请求可能会由于没有副本可用,而被转发给原始的服务器,这叫缓存未命中。并且缓存可以在任意时刻经任意的频率对副本进行再验证(看看副本有没有变化):
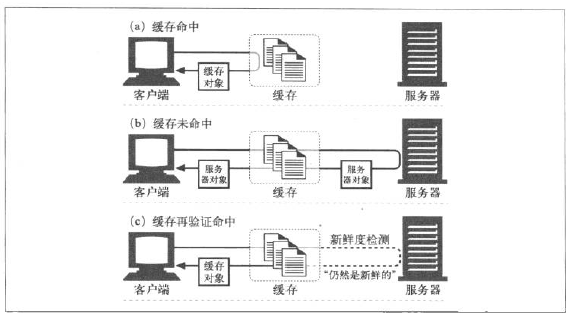
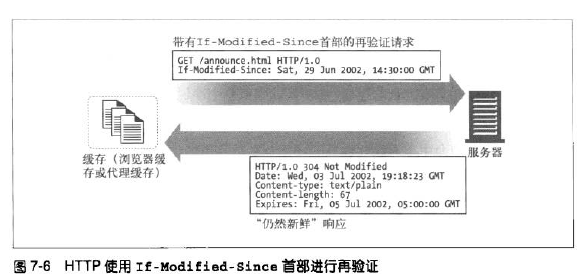
HTTP为我们提供了几个用来对已缓存对象进行再验证的工具,但最常用的为If-Modified-Since首部。将这个首部添加到GET请求中去,告诉服务器只有在缓存了对象之后,更改了这个对象的内容时,才发送对象。服务器在收到这个GET If-Modified-Since后,会发生以下三种情况的一种:
- 服务器上的对象内容没有更改;
- 服务器上的对象内容更改了;
- 服务器上的对象删除了;
服务器会针对具体的情况作出响应:
- 再验证命中,服务器对象内容未更改,服务器会向客户端发送一个小的HTTP 304 NOt MOdified响应;
- 再验证未命中,如果服务器对象内容更改了,服务器会向客户端发送一条普通的、带有完整内容的HTTP 200 OK响应;
- 对象被删除了,如果对象被删除了,则服务器会返回一个404 Not Found响应,缓存也会将副本删除;
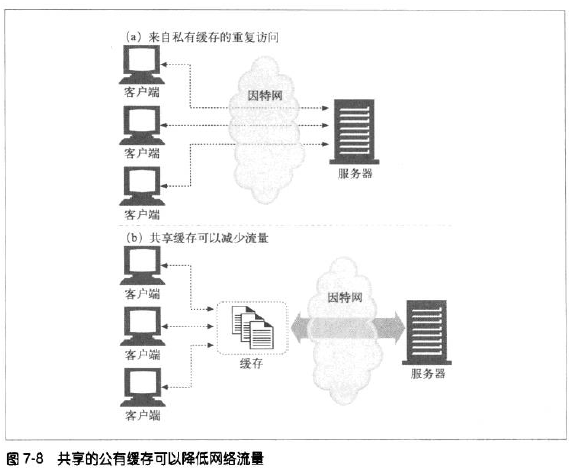
缓存又可分为私有缓存和公有缓存,比如浏览器一般会将常用文档缓存在我们的电脑中,这是私有缓存;而公有缓存接受多个用户的访问,所以一般是一个共享代理服务器或叫代理缓存,如:
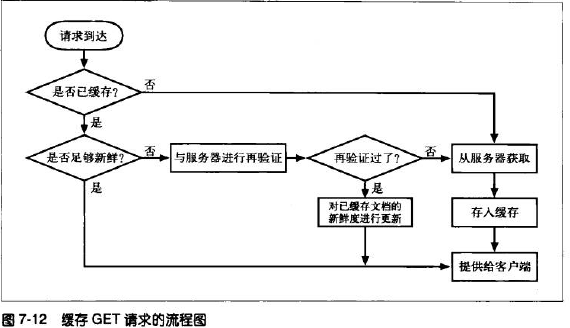
一般来说对一条HTTP GET报文的基本缓存处理的过程如下:
- 接收,缓存从网络中读取抵达的请求报文;
- 解析,缓存对报文进行解析,提取出URL和各种首部;
- 查询,缓存查看是否有本地副本可用,如果没有,就从服务器里获取一个副本,并保存在本地;
- 新鲜度检测,缓存查看已缓存的副本是否足够新鲜,若不是,则向服务器询问是否有任何的更新;
- 创建响应,缓存会用新的首部和已缓存的主体来构建一条响应;
- 发送,缓存通过网络将响应发送给客户端;
- 日志,缓存可选地创建一条日志来描述这个事务;
那我们怎样知道缓存的副本是否过期了呢?HTTP让原始服务器给每个文档附加了一个过期日期,HTTP/1.0+ 的Expires首部描述是绝对过期日期(就是具体的日期,如2015.09.22),HTTP/1.1的 Cache-Control首部描述是相对过期日期(如5000秒
。在缓存的副本过期之前,可以任意频率使用这些文档,而不用向服务器验证

当缓存的副本过期后,就需要向服务器验证这些缓存的副本的正确性,一般是使用HTTP的条件请求,常用的条件请求的首部有:

控制缓存的能力
服务器可以在响应中添加缓存控制首部来控制缓存存活的时间,按优先级的顺序依次为:
- 附加一个Cache-Control:no-store 首部;可以缓存文档,但每次使用前需要向服务器验证新鲜度
- 附加一个Cache-Control:no-cache首部;
- 附加一个Cache-Control:must-revalidate;
- 附加一个Cache-Control:max-age;
- 附加一个Expires首部;
- 不附加过期信息,让缓存自己决定文档的过期时间;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号