
Locust 的测试报告_性能监控平台
背景
当我们使用Locust做性能压测的时候,压测的过程和展示如下:


其中波动图是非持久化存储的,也就是刷新后,波动图就清空了。尽管Statistics中显示的信息比较完整,但是都是瞬时值,并不能体现出时序上的变化。像Failures、Exceptions、Slaves分在不同的tag查看起来也比较麻烦。Locust的测试报告也只有简单的csv文件,需要下载。
从上面我们可以看到Locust虽然提供了跨平台的web模式的性能监控和展示,但是有以下明显缺陷:
- rps、平均响应时间波动图没有持久化存储,刷新后便丢失
- 整体统计信息只是表格的形式,不能体现波动时序
- 测试报告过于简陋且只有文字版,只能下载存档
方案
方案其实很多,但为了减少投入成本和最大化利用现用的开源工具,选择以下方案:
Locust + Prometheus + Grafana
简单总结起来就是:
实现一个Locust的prometheus的exporter,将数据导入prometheus,然后使用grafana进行数据展示。
不难发现Jmeter在网上有许多类似方案的介绍,但很遗憾的是我没有找到很好实现Locust监控平台的方案。
搜索了一圈后发现boomer项目下有一个年久失修的exporter实现——prometheus_exporter.py, 而且作者并没有提供grafana之类的Dashboard设置,因此决定基于他的基础上,继续完成整个流程,我将在下面讲述。
环境介绍
我是直接在windows上搭建的也可以用Docker环境
下载相关软件:
链接:https://pan.baidu.com/s/1hVvoKOR7uKrULIM6Iqk0tA
提取码:884z
编写exporter
如Locust的官方文档所介绍的 Extending Locust 我们可以扩展web端的接口,比如添加一个 /export/prometheus 接口,这样Prometheus根据配置定时来拉取Metric信息就可以为Grafana所用了。这里需要使用Prometheus官方提供的client库,prometheus_client,来生成符合Prometheus规范的metrics信息。
在boomer原文件的基础上我做了一些修改和优化,在Readme中添加了Exporter的说明,并提交Pull Request。由于篇幅原因这里不展示代码了,完整代码(基于Locust 1.x版本)可以查看这里prometheus_exporter
为了方便演示,下面编写一个基于Python的locustfile作为施压端,命名为demo.py:
#!/usr/bin/env python
# coding: utf-8
import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 2)
host = "https://www.baidu.com/"
@task
def index_page(self):
self.client.get("/hello")
self.client.get("/world")
我们把master跑起来,启动两个worker。
# 启动master
locust --master -f prometheus_exporter.py
# 启动worker
locust --slave -f demo.py(目前是work模式)
在没有启动压测前,我们浏览器访问一下
http://127.0.0.1:8089/export/prometheus
返回结果如下:
这是使用prometheus_client库默认产生的信息,对我们数据采集没有影响,如果想关注master进程可以在grafana上创建相应的监控大盘。
接着我们启动10个并发用户开始压测,继续访问下上面的地址:
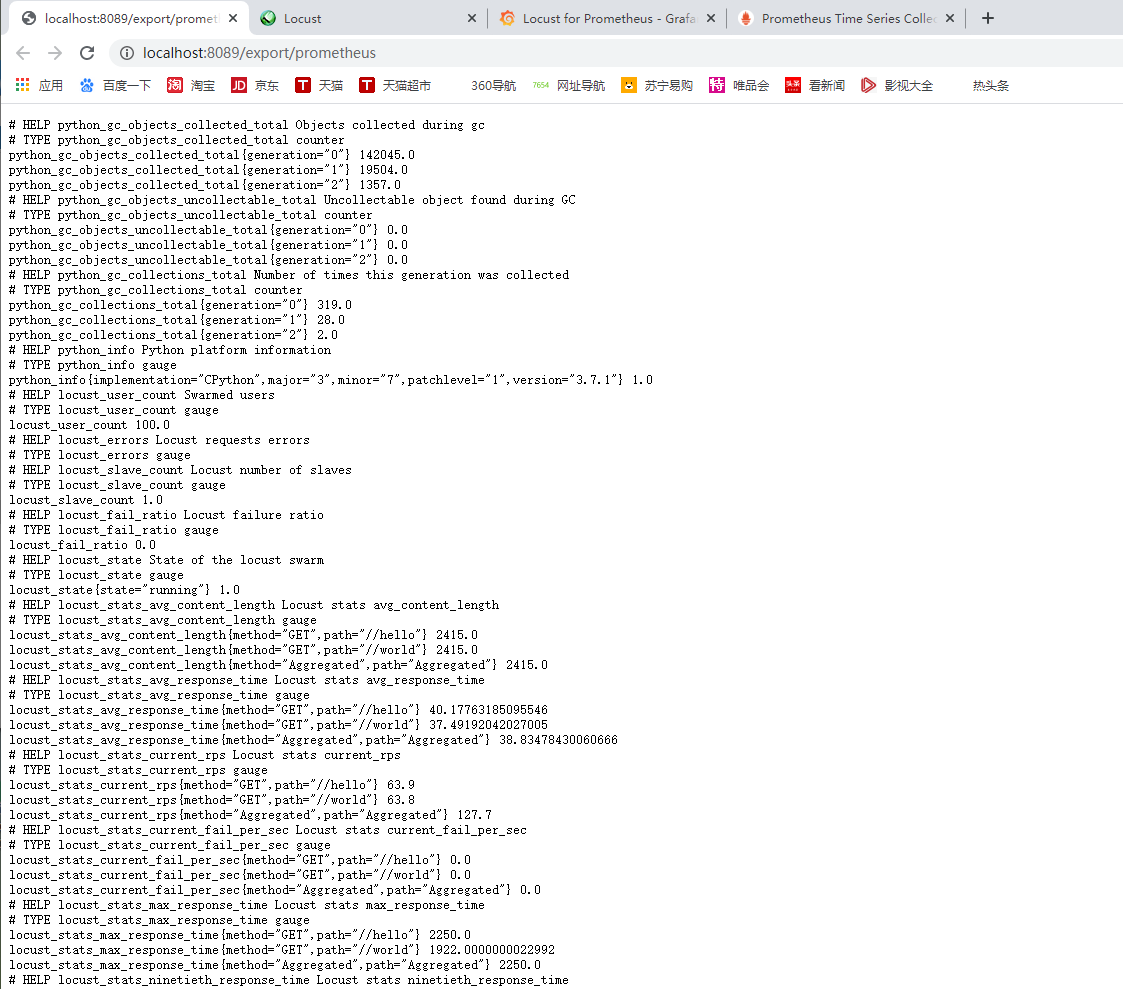
可以看到,locust_stats_avg_content_length、locust_stats_current_rps等信息都采集到了。
Prometheus部署
exporter已经ready了,接下来就是把prometheus部署起来,下载压缩文件
链接:https://pan.baidu.com/s/1hVvoKOR7uKrULIM6Iqk0tA
提取码:884z
1) 打开后进入文件夹
2) 接下来我们创建一个yml配置文件,准备覆盖prometheus.yml
global:
scrape_interval: 10s
evaluation_interval: 10s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: locust
metrics_path: '/export/prometheus'
static_configs:
- targets: ['192.168.1.2:8089'] # 地址修改为实际地址
labels:
instance: locust
3) 启动prometheus
双击prometheus.exe接下来我们访问Prometheus的graph页面,查询下是否有数据了。
http://127.0.0.1:9090/graph
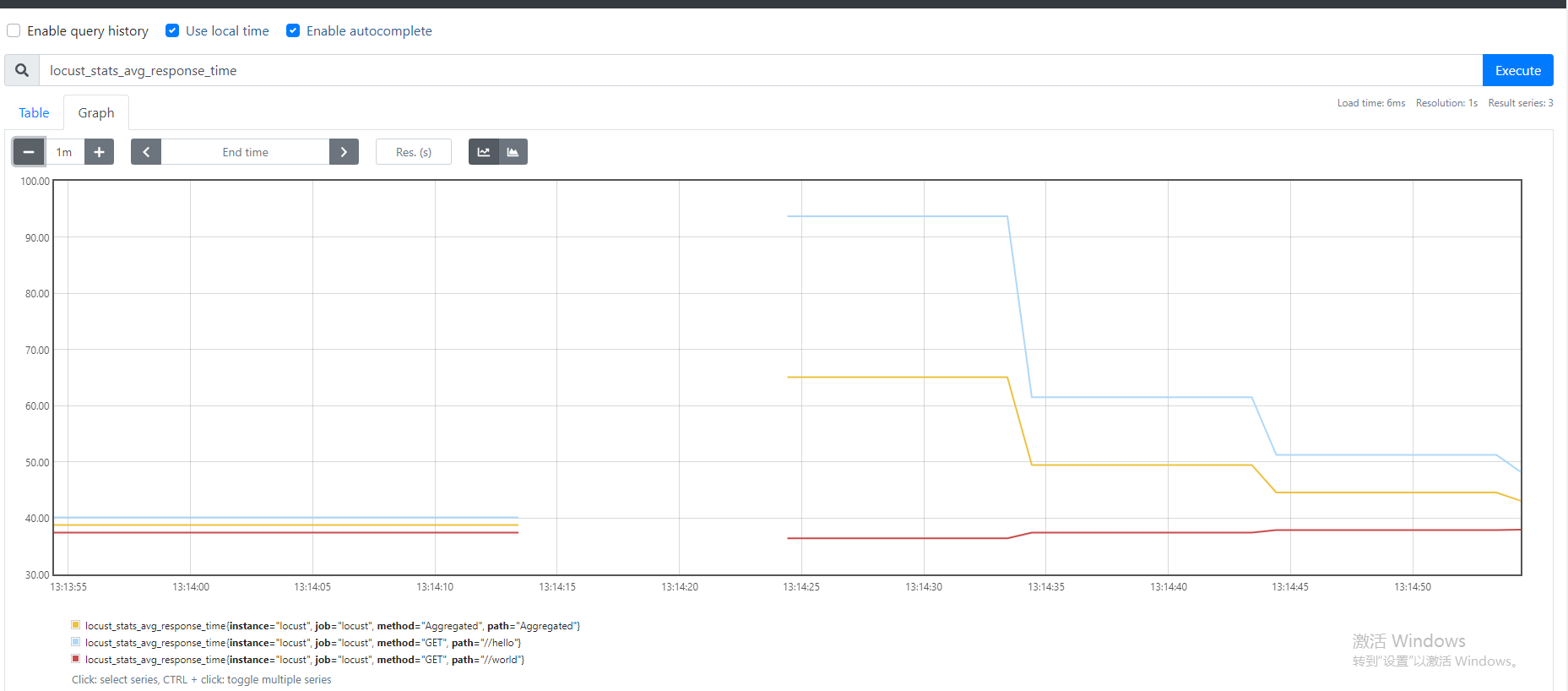
Grafana部署和配置
1)首先下载:
链接:https://pan.baidu.com/s/1hVvoKOR7uKrULIM6Iqk0tA
提取码:884z
复制这段内容后打开百度网盘手机App,操作更方便哦
2) 启动:
双击grafana-server.exe3)网页端访问localhost:3000验证部署成功
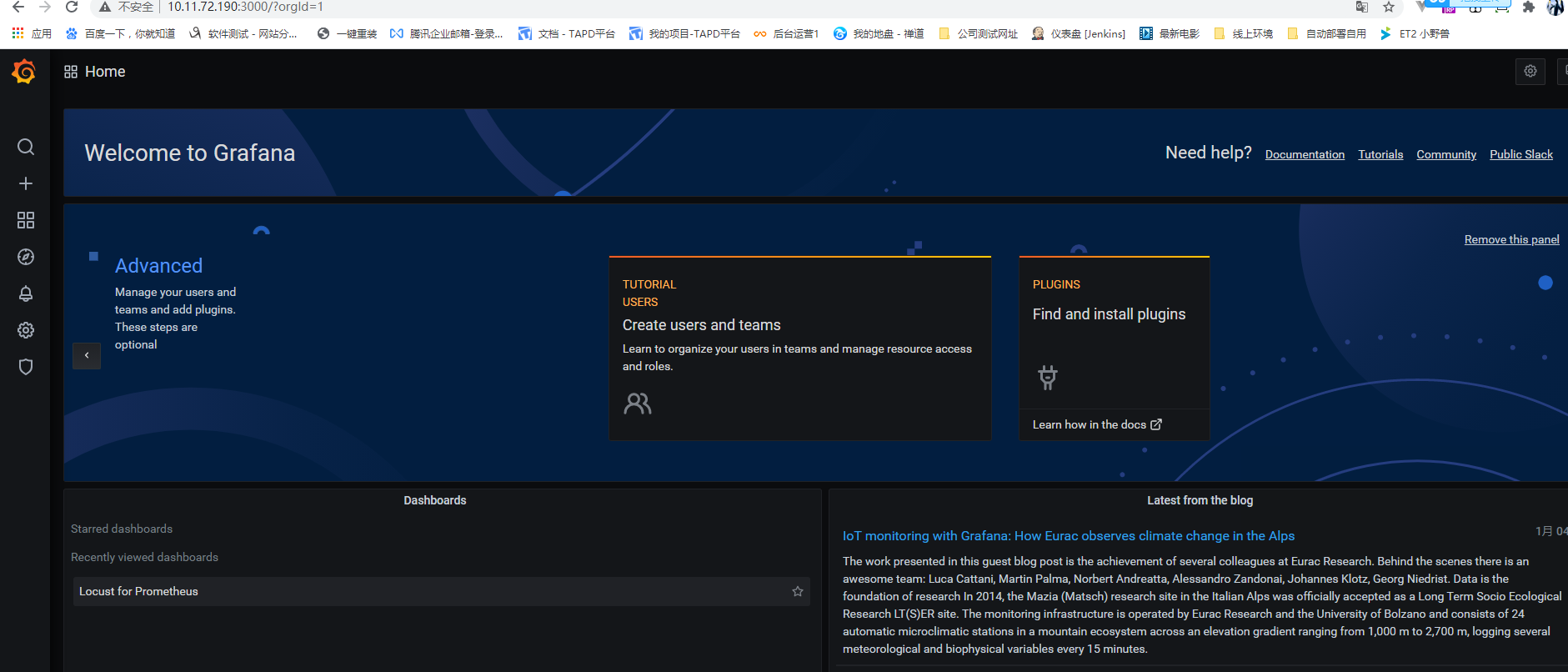
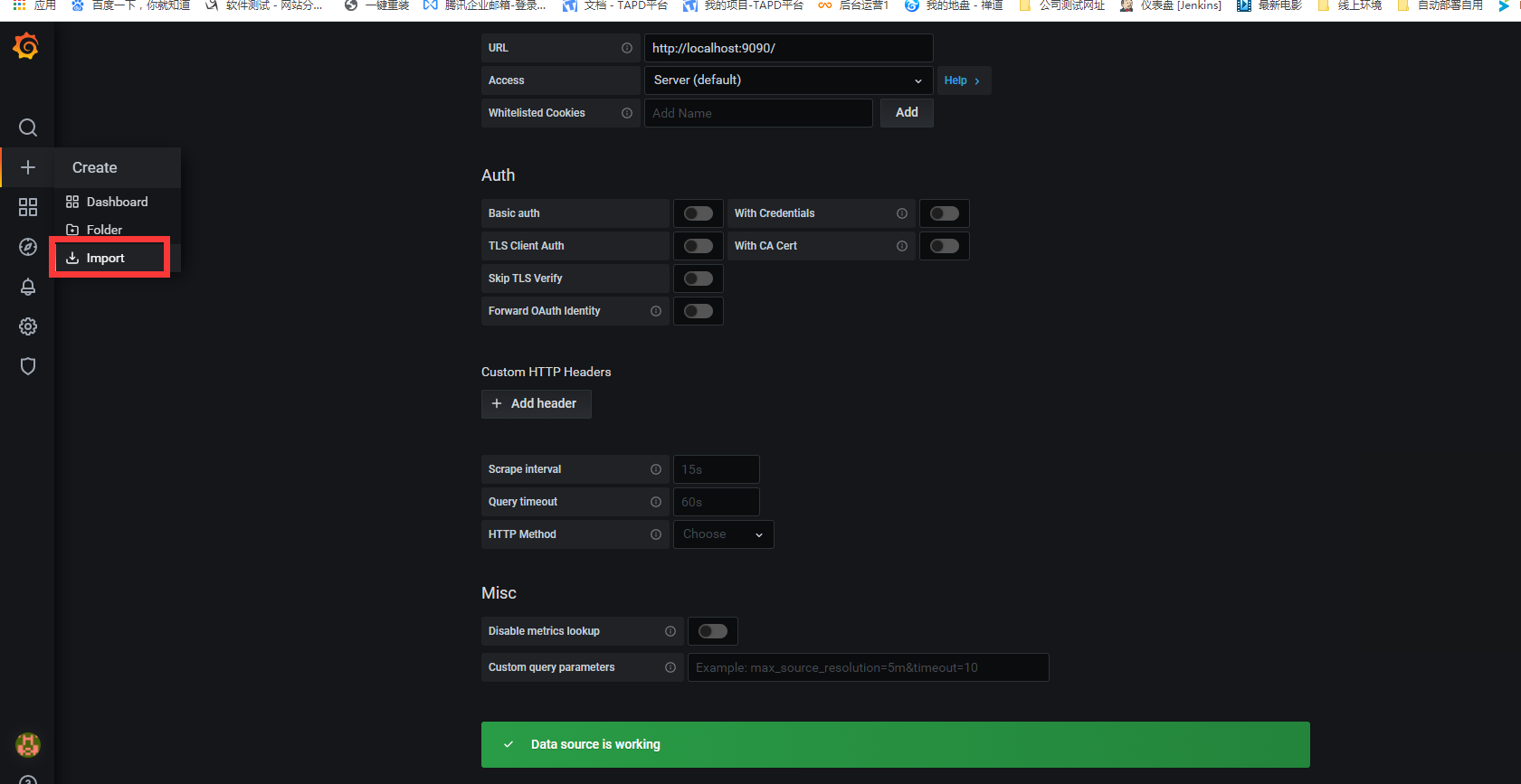
4) 选择添加prometheus数据源
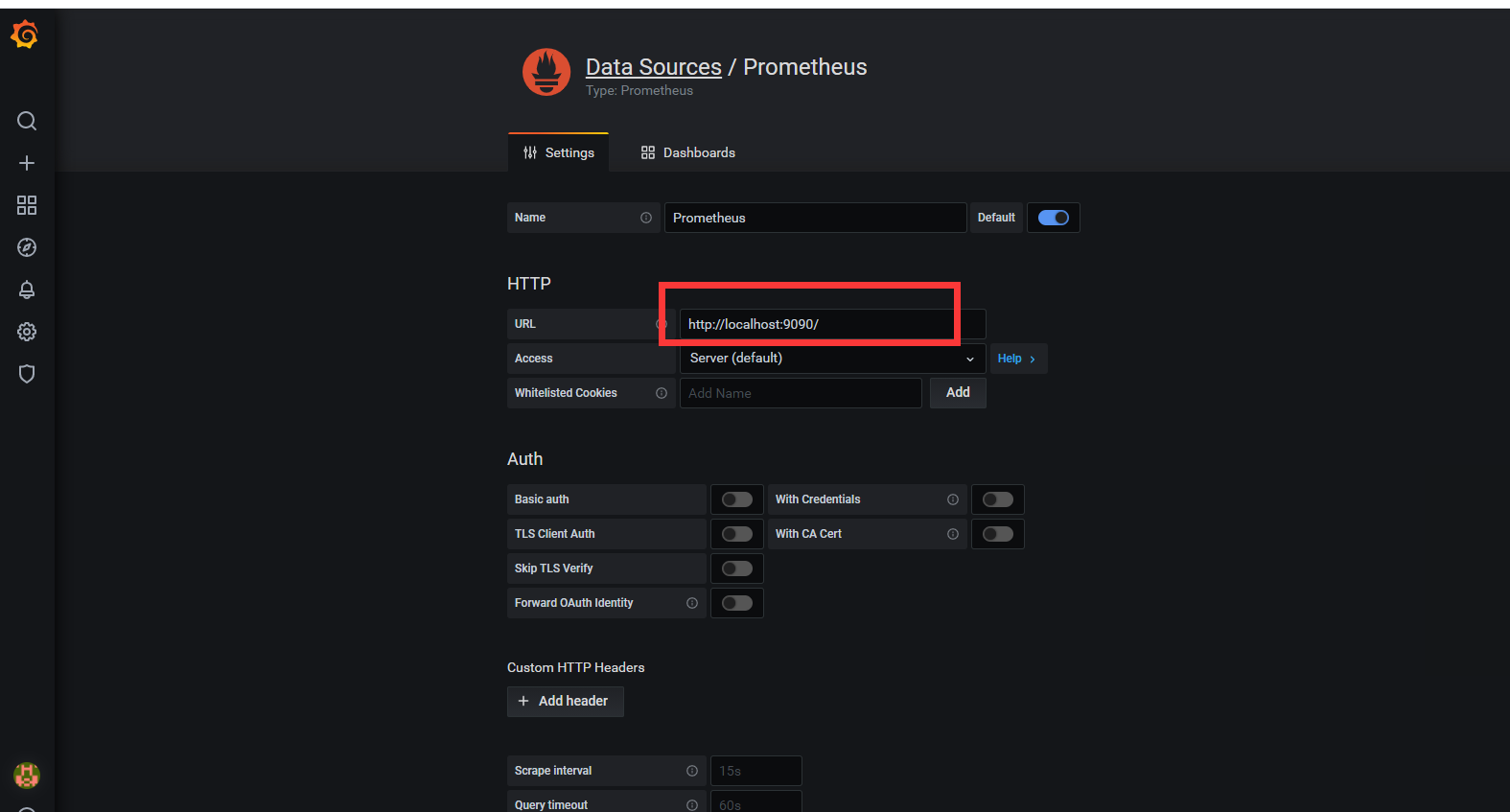
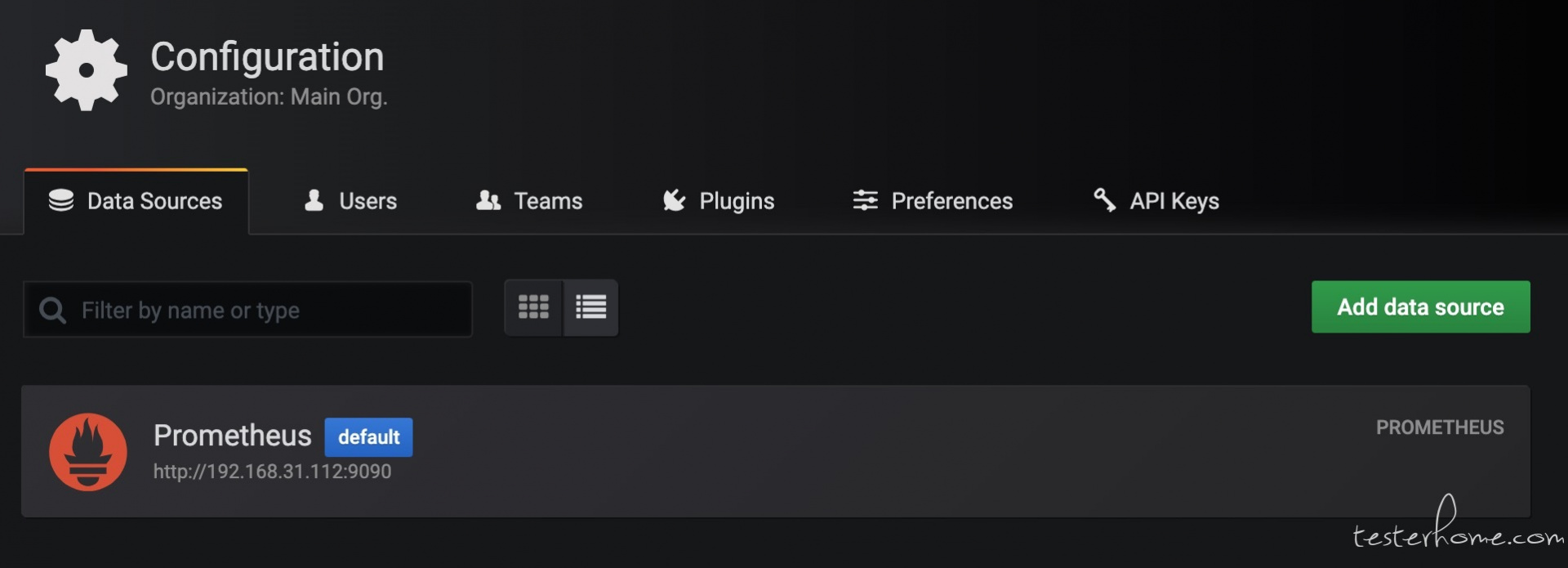

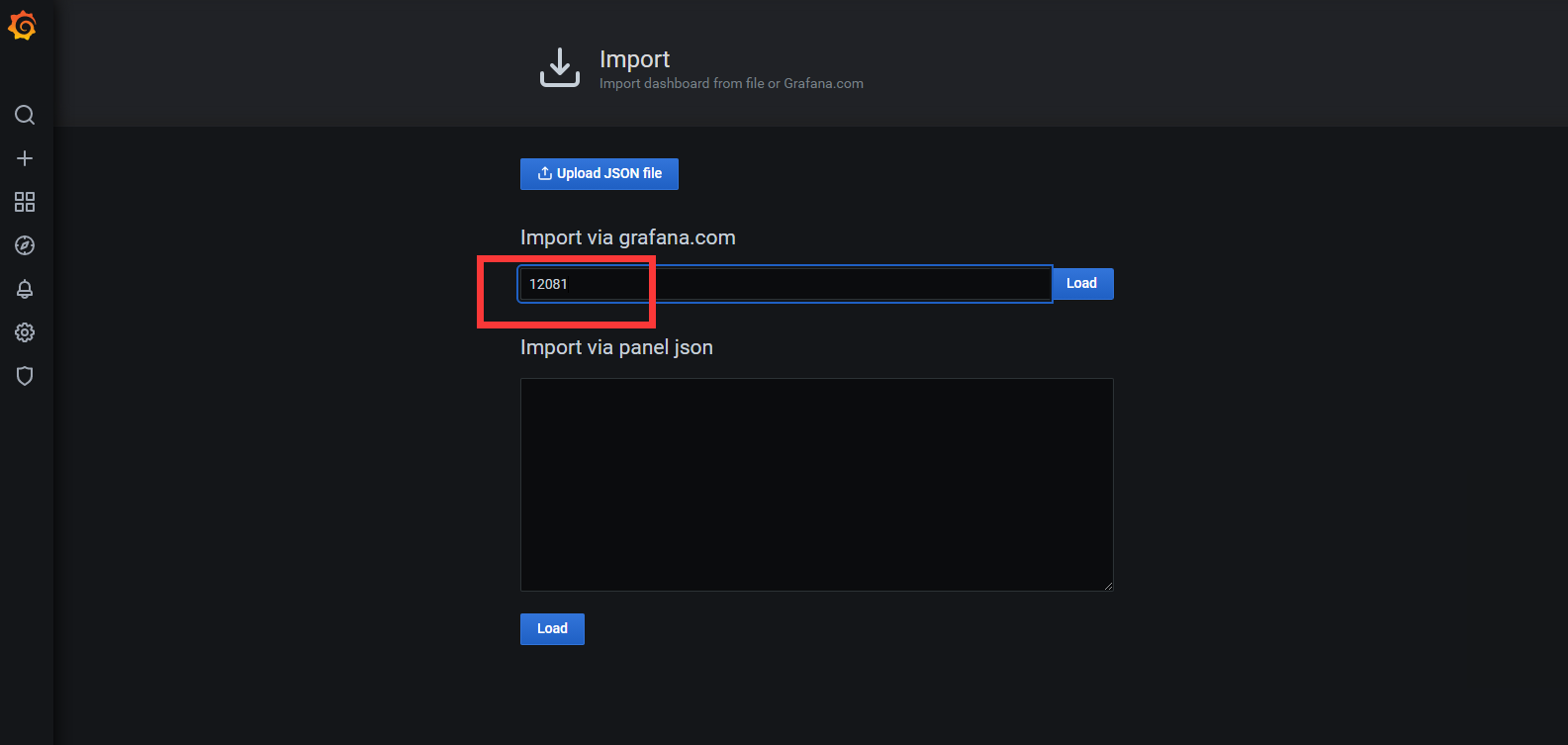
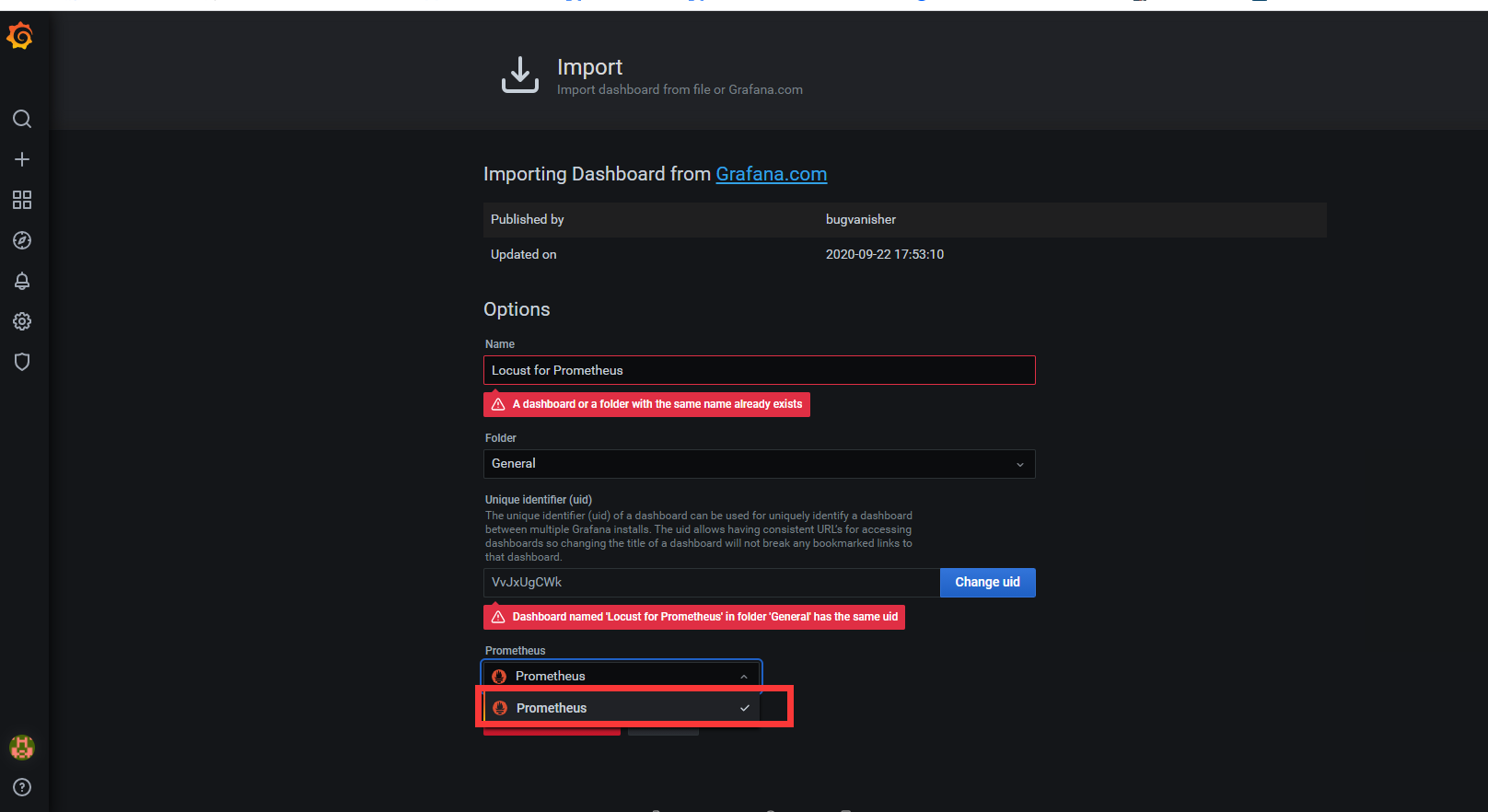
5) 导入模板
导入模板有几种方式,选择一种方式将dashboard模板导入。


效果展示
经过一系列『折腾』之后,是时候看看效果了。使用 Locust + Prometheus + Grafana 到底可以搭建怎样的性能监控平台呢?相比 Locust 自带的Web UI,这样搭建的性能监控平台究竟有什么优势呢?接下来就是展示成果的时候啦!
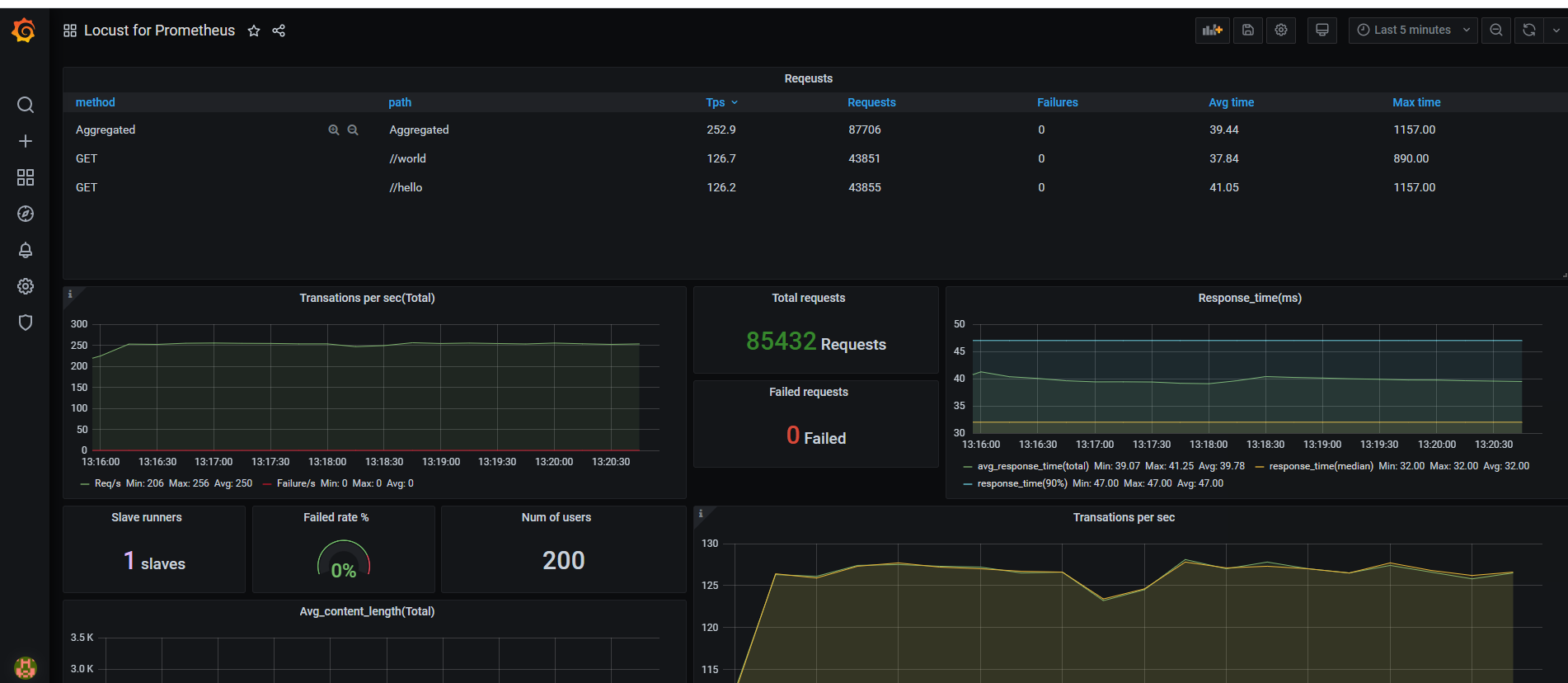
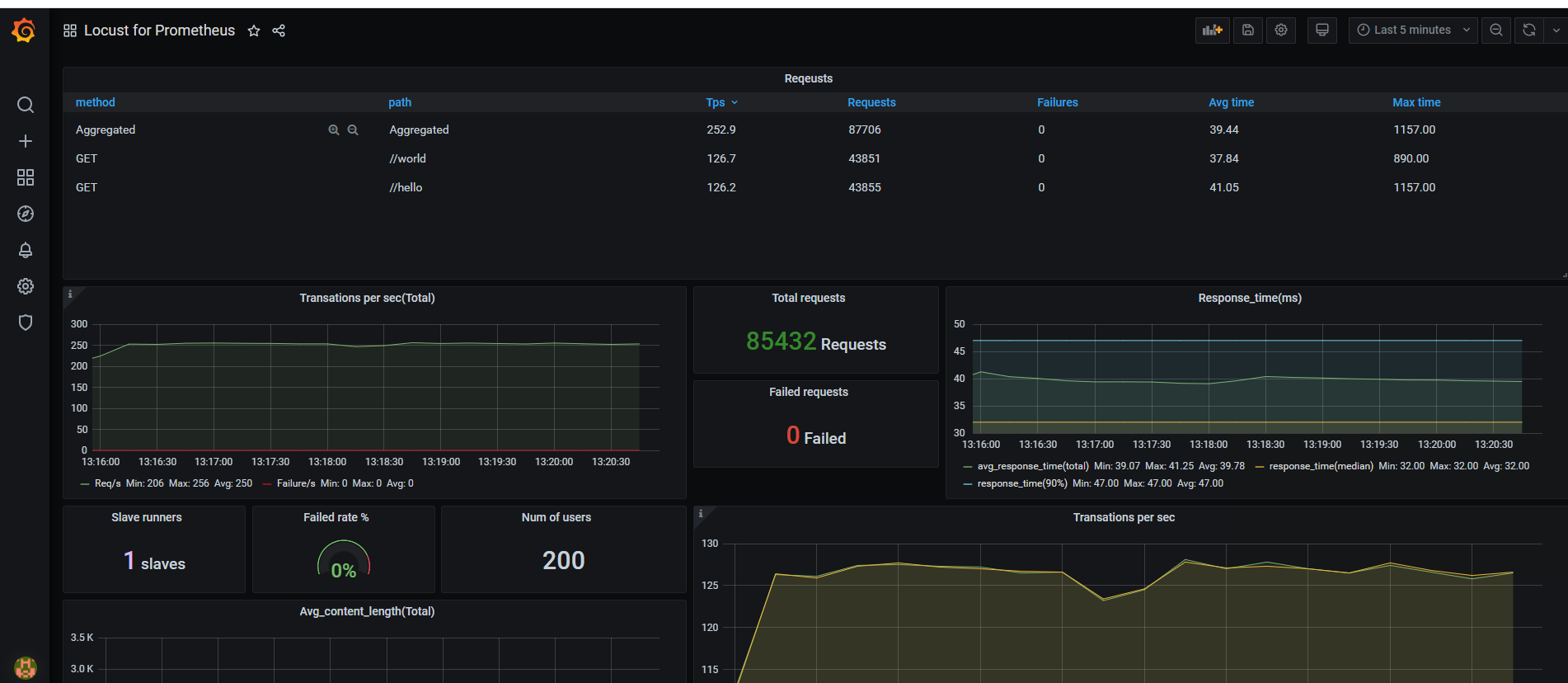

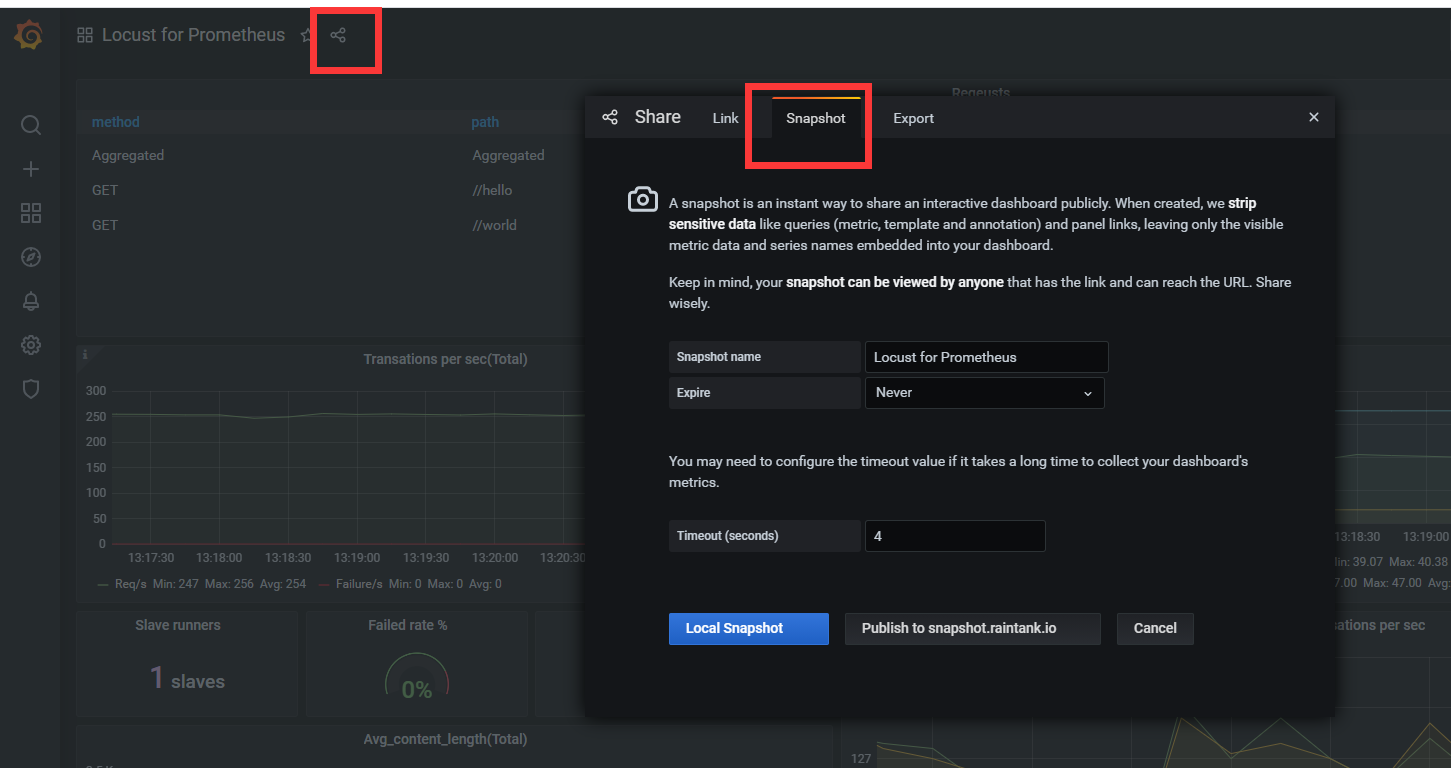
这个监控方案不仅提供了炫酷好看的图表,还能持久化存储所有压测数据,可以使用Share Dashboard功能保存测试结果并分享,相比Locust自带的Web UI,简直太方便!如果结合boomer,压测性能和压测报告应该也能让老板满意了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号