信息抽取工具的学习和使用
参考官方文档:http://ltp.readthedocs.io/zh_CN/latest/index.html
参考博客:https://www.cnblogs.com/Denise-hzf/p/6612886.html
简介:哈工大语言技术平台Language Technology Platform(LTP)是哈工大社会计算与信息检索研究中心历时十年开发的一整套中文语言处理系统。LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块(包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library, DLL)的应用程序接口,可视化工具,并且能够以网络服务(Web Service)的形式进行使用。
使用Docker中的LTP
因为我使用的是Win10 家庭版,因此不能直接安装Docker,只能通过docker toolbox进行安装
可以参考博客:https://www.cnblogs.com/linjj/p/5606687.html和后续系列博客
费尽周折,找博客,实践做到这步,给女朋友看,兴奋到不行
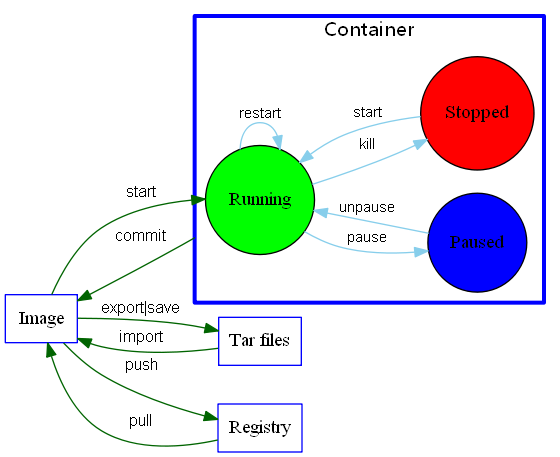
一张图说明一下docker所有的命令:
LTP4J
想尽办法编译ltp4j
首先使用Ant方法:
1.ltp4j的源码使用Ant进行编译,首先需要下载Ant。
2.下载完毕后,配置环境变量。参考见:https://jingyan.baidu.com/article/e2284b2b45d193e2e6118dc6.html
3.编译LTP4j:
首先需要下载LTP4j源码,解压
4.生成build.xml,Eclipse 自动生成 Ant的Build.xml 配置文件,生成的方法很隐蔽.选择你要生成Build.xml文件的项目,右键. Export-> General -> Ant Buildfiles .点Next,选择项目,再点Finish.
生成完毕.
5.cmd程序,cd源码解压位置,输入下列指令:
D:\BeTheBest\LTP\ltp4j-master>ant
使用Eclipse
参考文档,目前因为lib文件夹缺失,未能编译成功。
最后使用git文件直接编译的方法:
在确保安装maven的前提下(即 mvn -h 具有输出结果),您可以按照如下方式构建ltp4j。
- 在命令行下进入ltp4j所在文件夹
- git submodule init
- git submodule update
- mvn -Dmaven.test.skip=true
如果您编译提示成功同时项目根目录下包含 target/ltp4j-{version}.jar,证明已经编译成功。
nar-maven-plugin的编译结果随操作系统的不同而存在差异。其生成的ltp4j.jar以及代理文件可以从如下路径找到
- jar:./target/ltp4j-{version}.jar
- 代理程序:./target/ltp4j-{version}-{AOL}-jni/
其中,vesion 代表ltp4j的版本。AOL 代表 体系结构-系统-链接器 。 举例来讲,
- Windows 64位系统使用MSVC编译对应的AOL为:amd64-Windows-msvc
- Ubuntu 64位系统使用gnuc++编译对应的AOL为:amd64-Linux-gpp
运行 使用Eclipse
创建类,
使用代码:
package ltp4jtest; import java.util.Scanner; import java.util.ArrayList; import java.util.List; import edu.hit.ir.ltp4j.SplitSentence; import edu.hit.ir.ltp4j.Segmentor; import edu.hit.ir.ltp4j.Postagger; import edu.hit.ir.ltp4j.NER; import edu.hit.ir.ltp4j.Parser; import edu.hit.ir.ltp4j.SRL; import edu.hit.ir.ltp4j.Pair; public class Test { private String segmentModel; private String postagModel; private String NERModel; private String parserModel; private String SRLModel; private SplitSentence sentenceSplitApp; private Segmentor segmentorApp; private Postagger postaggerApp; private NER nerApp; private Parser parserApp; private SRL srlApp; private boolean ParseArguments(String[] args) { if (args.length == 1 && (args[0].equals("--help") || args[0].equals("-h"))) { Usage(); return false; } for (int i = 0; i < args.length; ++ i) { if (args[i].startsWith("--segment-model=")) { segmentModel = args[i].split("=")[1]; } else if (args[i].startsWith("--postag-model=")) { postagModel = args[i].split("=")[1]; } else if (args[i].startsWith("--ner-model=")) { NERModel = args[i].split("=")[1]; } else if (args[i].startsWith("--parser-model=")) { parserModel = args[i].split("=")[1]; } else if (args[i].startsWith("--srl-model=")) { SRLModel = args[i].split("=")[1]; } else { throw new IllegalArgumentException("Unknown options " + args[i]); } } if (segmentModel == null || postagModel == null || NERModel == null || parserModel == null || SRLModel == null) { Usage(); throw new IllegalArgumentException(""); } sentenceSplitApp = new SplitSentence(); segmentorApp = new Segmentor(); segmentorApp.create(segmentModel); postaggerApp = new Postagger(); postaggerApp.create(postagModel); nerApp = new NER(); nerApp.create(NERModel); parserApp = new Parser(); parserApp.create(parserModel); srlApp = new SRL(); srlApp.create(SRLModel); return true; } public void Usage() { System.err.println("An command line example for ltp4j - The Java embedding of LTP"); System.err.println("Sentences are inputted from stdin."); System.err.println(""); System.err.println("Usage:"); System.err.println(""); System.err.println(" java -cp <jar-path> --segment-model=<path> \\"); System.err.println(" --postag-model=<path> \\"); System.err.println(" --ner-model=<path> \\"); System.err.println(" --parser-model=<path> \\"); System.err.println(" --srl-model=<path>"); } private String join(ArrayList<String> payload, String conjunction) { StringBuilder sb = new StringBuilder(); if (payload == null || payload.size() == 0) { return ""; } sb.append(payload.get(0)); for (int i = 1; i < payload.size(); ++ i) { sb.append(conjunction).append(payload.get(i)); } return sb.toString(); } public void Analyse(String sent) { ArrayList<String> sents = new ArrayList<String>(); sentenceSplitApp.splitSentence(sent, sents); for(int m = 0; m < sents.size(); m++) { ArrayList<String> words = new ArrayList<String>(); ArrayList<String> postags = new ArrayList<String>(); ArrayList<String> ners = new ArrayList<String>(); ArrayList<Integer> heads = new ArrayList<Integer>(); ArrayList<String> deprels = new ArrayList<String>(); List<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>> srls = new ArrayList<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>>(); System.out.println("#" + (m + 1)); System.out.println("Sentence : " + sents.get(m)); segmentorApp.segment(sents.get(m), words); System.out.println("Segment Result : " + join(words, "\t")); postaggerApp.postag(words, postags); System.out.print("Postag Result : "); System.out.println(join(postags, "\t")); nerApp.recognize(words, postags, ners); System.out.print("NER Result : "); System.out.println(join(ners, "\t")); parserApp.parse(words, postags, heads, deprels); int size = heads.size(); StringBuilder sb = new StringBuilder(); sb.append(heads.get(0)).append(":").append(deprels.get(0)); for(int i = 1; i < heads.size(); i++) { sb.append("\t").append(heads.get(i)).append(":").append(deprels.get(i)); } System.out.print("Parse Result : "); System.out.println(sb.toString()); for (int i = 0; i < heads.size(); i++) { heads.set(i, heads.get(i) - 1); } srlApp.srl(words,postags,heads,deprels,srls); size = srls.size(); System.out.print("SRL Result : "); if (size == 0) { System.out.println(); } for (int i = 0; i < srls.size(); i++) { System.out.print(srls.get(i).first + " ->"); for (int j = 0; j < srls.get(i).second.size(); j++) { System.out.print(srls.get(i).second.get(j).first + ": beg = " + srls.get(i).second.get(j).second.first + " end = " + srls.get(i).second.get(j).second.second + ";"); } System.out.println(); } } } public void release(){ segmentorApp.release(); postaggerApp.release(); nerApp.release(); parserApp.release(); srlApp.release(); } public static void main(String[] args) { Test console = new Test(); try { if (!console.ParseArguments(args)) { return; } Scanner input = new Scanner(System.in); String sent; try { System.out.print(">>> "); while((sent = input.nextLine()) != null) { if (sent.length() > 0) { console.Analyse(sent); } System.out.print(">>> "); } } catch(Exception e) { console.release(); } } catch (IllegalArgumentException e) { } } }
使用上面生成的jar文件
进行运行
LTP 的源码编译安装
依赖:CMake
CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。他能够输出各种各样的makefile或者project文件,能测试编译器所支持的C++特性,类似UNIX下的automake。只是 CMake 的组态档取名为 CMakeLists.txt。Cmake 并不直接建构出最终的软件,而是产生标准的建构档(如 Unix 的 Makefile 或 Windows Visual C++ 的 projects/workspaces),然后再依一般的建构方式使用。这使得熟悉某个集成开发环境(IDE)的开发者可以用标准的方式建构他的软件,这种可以使用各平台的原生建构系统的能力是 CMake 和 SCons 等其他类似系统的区别之处。
因为LTP已经构建好了项目文件、镜像文件,跟着官网说的来做就行,不用乱下文件,我的一天就是这么过去的···
在 Windows (MSVC) 下编译
结合博客:https://blog.csdn.net/qinhan728/article/details/49690627
1.配置LTP的安装路径
因为jni依赖于ltp编译产生的动态库,所以在编译过程中需要给出ltp的路径。 请修改/path/to/your/ltp4j-project/CMakeLists.txt中的LTP_HOME的值为您的LTP项目的路径(/path/to/your/ltp-project), 对应修改的代码为:
set (LTP_HOME "/path/to/your/ltp-project/")
2.构建VC Project
在项目文件夹下新建一个名为 build 的目录,打开CMake Gui,在source code中填入项目目录,在binaries中填入 build 目录。然后Configure -> Generate。
|
影响CMake行为的变量 |
|
|
BUILD_SHARED_LIBS |
如果为ON,则add_library默认创建共享库 |
|
CMAKE_ABSOLUTE_DESTINATION_FILES |
安装文件列表时使用ABSOLUTE DESTINATION 路径 |
|
CMAKE_AUTOMOC_RELAXED_MODE |
在严格和宽松的automoc模式间切换 |
|
CMAKE_BACKWARDS_COMPATIBILITY |
构建工程所需要的CMake版本 |
|
CMAKE_BUILD_TYPE |
指定基于make的产生器的构建类型 |
|
CMAKE_COLOR_MAKEFILE |
开启时,使用Makefile产生器会产生彩色输出 |
|
CMAKE_CONFIGURATION_TYPES |
指定有哪些构建类型 |
|
CMAKE_DISABLE_FIND_PACKAGE_<PackageName> |
禁用对应的find_package调用 |
|
要求cmake_install.cmake脚本在遇到一个文件指定的INSTALL DESTINATION 是绝对路径时,报告错误并退出。 |
|
|
CMAKE_FIND_LIBRARY_PREFIXES |
当查找库时,自动添加到库名称的前缀,UNIX系统,该值通常指定为lib |
|
CMAKE_FIND_PACKAGE_WARN_NO_MODULE |
让find_package命令在被调用但没有指定一个显式模式(MODULE, CONFIG or NO_MODULE)时,给出警告信息。 |
|
CMAKE_IGNORE_PATH |
那些被FIND_XXX()命令忽略的路径 |
|
CMAKE_INCLUDE_PATH |
被FIND_FILE()和FIND_PATH()用于搜索的路径 |
|
CMAKE_INSTALL_DEFAULT_COMPONENT_NAME |
用于install()命令中的默认组件 |
|
CMAKE_INSTALL_PREFIX |
安装路径的前缀 |
|
CMAKE_LIBRARY_PATH |
FIND_LIBRARY()命令搜索时使用的路径 |
|
CMAKE_MFC_FLAG |
告诉CMake使用MFC链接库或可执行文件 |
|
CMAKE_MODULE_PATH |
搜索CMake模块的路径列表 |
|
CMAKE_NOT_USING_CONFIG_FLAGS |
如果为true,将跳过_BUILD_TYPE标记 |
|
CMAKE_POLICY_DEFAULT_CMP<NNNN> |
Default for CMake Policy CMP<NNNN> when it is otherwise left unset. |
|
CMAKE_PREFIX_PATH |
FIND_XXX()命令搜索时使用的基路径,会添加相应的子目录。 |
|
CMAKE_PROGRAM_PATH |
FIND_PROGRAM()搜索时使用的路径。 |
|
CMAKE_SKIP_INSTALL_ALL_DEPENDENCY |
不要让install目标依赖all目标 |
|
CMAKE_SYSTEM_IGNORE_PATH |
那些被FIND_XXX()命令忽略的路径 |
|
CMAKE_SYSTEM_INCLUDE_PATH |
FIND_FILE()和FIND_PATH()命令搜索时使用的路径 |
|
CMAKE_SYSTEM_LIBRARY_PATH |
FIND_LIBRARY()命令搜索时使用的路径 |
|
CMAKE_SYSTEM_PREFIX_PATH |
FIND_XXX()命令搜索时使用的基路径,会添加相应的子目录。 |
|
CMAKE_SYSTEM_PROGRAM_PATH |
FIND_PROGRAM()搜索时使用的路径。 |
|
CMAKE_USER_MAKE_RULES_OVERRIDE |
指定一个CMake文件来覆盖平台信息 |
|
CMAKE_WARN_ON_ABSOLUTE_INSTALL_DESTINATION |
要求cmake_install.cmake脚本在遇到一个文件指定的INSTALL DESTINATION 是绝对路径时,给出警告信息 |
|
描述系统的变量 |
|
|
APPLE |
为true表示当前运行的平台是Mac OSX |
|
BORLAND |
如果当前使用的是Borland编译器,则为true. |
|
CMAKE_CL_64 |
如果使用的是微软的64位编译器,则为true |
|
CMAKE_COMPILER_2005 |
如果使用的是微软的Visual Studio 2005编译器,则为true. |
|
CMAKE_HOST_APPLE |
当主机系统为Apple OSX时,为true. |
|
CMAKE_HOST_SYSTEM |
cmake当前运行的主机系统 |
|
CMAKE_HOST_SYSTEM_NAME |
cmake当前运行的主机系统的名称 |
|
CMAKE_HOST_SYSTEM_PROCESSOR |
cmake当前运行的主机系统CPU的名称 |
|
CMAKE_HOST_SYSTEM_VERSION |
cmake当前运行的OS版本号 |
|
CMAKE_HOST_UNIX |
当操作系统为Unix或类Unix系统时,为true。(如Cygwin和Apple) |
|
CMAKE_HOST_WIN32 |
当操作系统为Windows系统,包括64位Window系统时,为true. |
|
CMAKE_LIBRARY_ARCHITECTURE |
如果检测到,则是指目标架构库目录 |
|
CMAKE_LIBRARY_ARCHITECTURE_REGEX |
匹配所有可能的目标架构库目录的正则表达式 |
|
CMAKE_OBJECT_PATH_MAX |
本地构建工具允许的对应文件全路径长度的最大值 |
|
CMAKE_SYSTEM |
CMake编译的目标系统名称 |
|
CMAKE_SYSTEM_NAME |
CMake编译的目标操作系统 |
|
CMAKE_SYSTEM_PROCESSOR |
CMake编译的目标系统的CPU名称 |
|
CMAKE_SYSTEM_VERSION |
CMkae编译的目标系统的版本号 |
|
CYGWIN |
使用cygwin系统 |
|
MSVC |
使用Microsoft Visual C |
|
MSVC80 |
使用Microsoft Visual C 8.0 |
|
MSVC_IDE |
使用Microsoft Visual C IDE |
|
MSVC_VERSION |
Microsoft Visual C/C++ 使用的版本号 |
|
UNIX |
Unix和类Unix系统 |
|
WIN32 |
Windows系统,包括64位Window系统 |
|
XCODE_VERSION |
XCode的版本 |

构建后得到ALL_BUILD、RUN_TESTS、ZERO_CHECK三个VC Project。使用VS打开ALL_BUILD项目,选择Release 方式构建项目。
下载、安装VS 2015,注意一定要通过打开项目打开此文件。右键该项目选择属性,按下图所示选择Release,×64方式。确定后,按菜单栏的“生成(Build)”,构建ALL_BUILD项目。
这时候,编译并不成功,需要进行完下述操作再次进行编译。
继续使用CMake
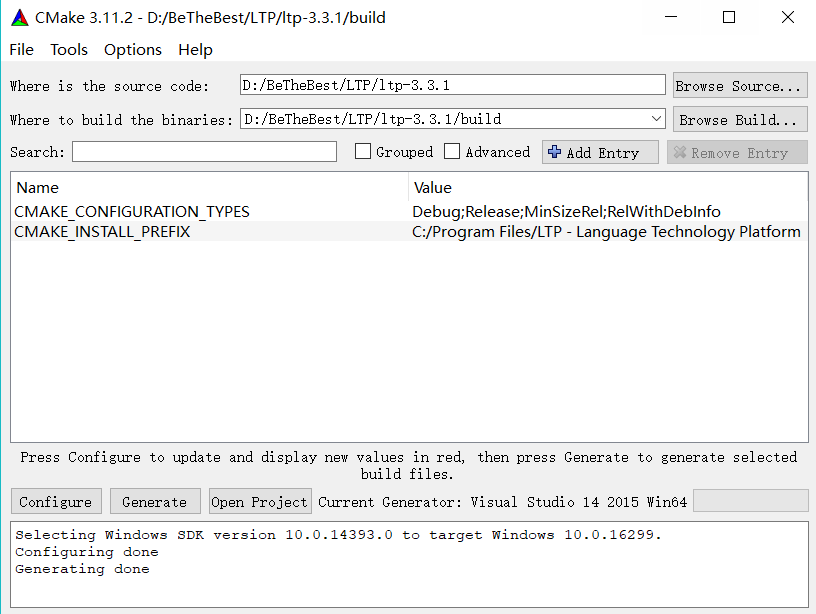
后续进行操作时,因为我把VS安装到了D盘,导致cMake找不到运行的文件。
看了一下,最新的VS 2017支持多种编程语言,包括ios和android开发,那就卸载一波软件,在c盘上给vs按个家吧。
vs的卸载和重新安装,我入坑了。。
中间还出现了cMake认为Windows SDK 版本不对的问题,算了吧,LTP我们友尽。
为此,我还得改一下这篇随笔的文章名字。
FNLP的使用
这是复旦大学的法宝。
FNLP是一个致力于中文自然语言处理的开源项目,提供了进行自然语言处理的工具,包括分词、词性标注、句法分析、文本相似度计算等等,以及进行处理所需的数据集。从功能的角度而言,FNLP与著名的Python自然语言处理工具包NLTK较为类似,但后者对中文处理的能力较差。
FNLP采用Java编写,使得它可以轻松运行在各种不同的平台之上,不仅可以通过命令行调用,同时也可以十分便捷的集成到各种Java项目之中。
接下来,我就一边实施着,一边复制一下官方文档了哈。。
1.1.1下载FNLP
FNLP是一个开源项目,其代码托管在Github.com之上。有多种方法从FNLP的Github页面下载最新源码。
-
直接下载ZIP包
进入Github中的FNLP项目首页,在页面右侧点击“Download ZIP”按钮,即可从Github下载到FNLP的最新源码包。得到的ZIP包解压缩后即可使用。用这种方法得到的是一份纯净的FNLP源码。
-
直接利用Git下载
对于习惯使用源码管理工具Git的用户,可以直接使用Git下载最新源码,命令如下:
git clone https://github.com/xpqiu/fnlp.git采用这种方法得到的是一份包含Git仓库的源码,除了纯净的源码外,还可以利用Git的版本控制功能查阅每个文件的任何一个历史版本。Git是一个支持多人协作的源码版本管理系统,详情参见Wikipedia页面,或Git官方网站。
除了源码文件,还需要下载FNLP语言模型文件。由于模型文件交大,不便于存放在源码库之中,请至Release页面下载,并将模型文件放在“models”目录。
- seg.m 分词模型
- pos.m 词性标注模型
- dep.m 依存句法分析模型
下载后得到文件结构应与FNLP Github页面中呈现的一致,确认无误后即可开始编译运行。
1.1.2 编译FNLP
FNLP的编译并不复杂,但需要确保系统中已经安装好了编译所必备的工具。
-
安装与配置JDK
在编译前,确保已经正确安装并配置了JDK(版本需Java 1.6或以上)。配置后,
PATH环境变量中应包含JDK目录,确保可以在命令行中运行java与javac工具。java -version javac -version -
安装与配置Maven
Maven是一款先进的Java项目管理工具,用于项目的管理与编译,FNLP也采用Maven构建。完成了Maven的安装与配置后,确保可以在命令行中查看Maven版本号:
mvn -version -
编译FNLP
在命令行中进入FNLP的源码目录(即“README.md”所在的目录),执行如下命令进行编译:
mvn install -Dmaven.test.skip=true
此时Maven会显示编译结果,如果见到类似如下的语句,说明编译成功。
[INFO] Reactor Summary:
[INFO]
[INFO] fnlp-all ........................................... SUCCESS [ 0.225 s]
[INFO] fnlp-core .......................................... SUCCESS [ 1.417 s]
[INFO] fnlp-dev ........................................... SUCCESS [ 0.182 s]
[INFO] fnlp-train ......................................... SUCCESS [ 0.193 s]
[INFO] fnlp-app ........................................... SUCCESS [ 0.246 s]
[INFO] fnlp-demo .......................................... SUCCESS [ 0.153 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
通过这种方法,会编译四个Jar包:fnlp-core、fnlp-dev、fnlp-train、fnlp-app、fnlp-demo。它们分别位于源码目录中,各自对应目录中的"target"目录之中,例如fnlp-core的软件包位于: fnlp-core/target/fnlp-core-2.0-SNAPSHOT.jar
如果遇到错误“软件包 org.junit 不存在”,则可修改源码目录下的“pom.xml”文件。找到包含“junit”的依赖设置: junit junit 4.11 test 删除其中的scope元素所在行。完成编辑保存后,再次执行编译命令,即可顺利编译。
1.2 命令行调用
FNLP提供了命令行下的调用方法,这也是测试是否正确编译最简单的手段。下面简单地列举FNLP支持的部分功能与使用方式。 然而在执行前,还需要下载两个Java工具包。
假设命令行当前位于源码目录,且依赖的Jar包位于“libs”目录下。
可以通过两种方式:
1 执行maven命令:
mvn dependency:copy-dependencies -DoutputDirectory=libs
这样jar包都会copy到工程目录下的libs里面
2 手动方式:
下载两个依赖包,下载后的工具包可以存放于“libs”目录。
FNLP目录结构

然后可以通过下列命令调用FNLP。
-
中文分词
java -Xmx1024m -Dfile.encoding=UTF-8 -classpath "fnlp-core/target/fnlp-core-2.1-SNAPSHOT.jar:libs/trove4j-3.0.3.jar:libs/commons-cli-1.2.jar" org.fnlp.nlp.cn.tag.CWSTagger -s models/seg.m "自然语言是人类交流和思维的主要工具,是人类智慧的结晶。"执行结果如下:
自然 语言 是 人类 交流 和 思维 的 主要 工具 , 是 人类 智慧 的 结晶 。命令行运行截图
参数“-Xmx1024m”设置Java虚拟机的可用内存为1024M。FNLP载入语言模型所需内存较大,因此可以利用此参数修改可用内存量。
参数“-classpath ...”载入Jar文件。因此在引号内依次写下fnlp-core、trove、commons-cli的Jar包路径,使用英文冒号分隔文件名(Windows系统下用英文分号分隔文件名)。
参数“org.fnlp.nlp.cn.tag.CWSTagger”指定了本次调用的类名,表示调用中文分词器CWSTagger。而后续的参数是根据所调用的类确定的,例如,CWSTagger需要通过“-s”参数指定语言模型文件“models/seg.m”。
中文分词从输入文件:
java -Xmx1024m -Dfile.encoding=UTF-8 -classpath "fnlp-core/target/fnlp-core-2.1-SNAPSHOT.jar:libs/trove4j-3.0.3.jar:libs/commons-cli-1.2.jar" org.fnlp.nlp.cn.tag.CWSTagger -f models/seg.m <input file> <output file>以"-f"代"-s"参数来分词从文件。
-
中文词性标注
java -Xmx1024m -Dfile.encoding=UTF-8 -classpath "fnlp-core/target/fnlp-core-2.1-SNAPSHOT.jar:libs/trove4j-3.0.3.jar:libs/commons-cli-1.2.jar" org.fnlp.nlp.cn.tag.POSTagger -s models/seg.m models/pos.m "周杰伦出生于台湾,生日为79年1月18日,他曾经的绯闻女友是蔡依林。"执行结果如下:
周杰伦/人名 出生/动词 于/介词 台湾/地名 ,/标点 生日/名词 为/介词 79年/时间短语 1月/时间短语 18日/时间短语 ,/标点 他/人称代词 曾经/副词 的/结构助词 绯闻/名词 女友/名词 是/动词 蔡依林/人名 。/标点 -
实体名识别
java -Xmx1024m -Dfile.encoding=UTF-8 -classpath "fnlp-core/target/fnlp-core-2.1-SNAPSHOT.jar:libs/trove4j-3.0.3.jar:libs/commons-cli-1.2.jar" org.fnlp.nlp.cn.tag.NERTagger -s models/seg.m models/pos.m "詹姆斯·默多克和丽贝卡·布鲁克斯 鲁珀特·默多克旗下的美国小报《纽约邮报》的职员被公司律师告知,保存任何也许与电话窃听及贿赂有关的文件。"执行结果如下:
{詹姆斯·默多克=人名, 鲁珀特·默多克旗=人名, 丽贝卡·布鲁克斯=人名, 纽约=地名, 美国=地名}

使用命令行的方式,不必编写Java代码即可体验到FNLP的强大功能,是进行功能测试与开发轻量级应用的绝佳方法。除了以上三种功能,FNLP还提供了更多的命令行接口,将在第3章节详细介绍。同时,下一个版本的FNLP也会开放更多的命令行接口供用户使用。
在Eclipse项目中引用FNLP
Eclipse是老牌的Java IDE,在项目中引用FNLP非常简单(以JUNO 4.2版本为例)。
-
添加库引用
在IDE左侧的
Package Explorer中选择项目名称,右击,在菜单中选择Build Path,Add External Archives...,则会弹出文件选择对话框,依次查找并添加下列文件:- fnlp-core-2.1-SNAPSHOT.jar
- trove4j-3.0.3.jar
- commons-cli-1.2.jar
Add External Archives菜单
这三个文件分别为FNLP的核心程序包,与两个库依赖的工具包。前者通过FNLP源码编译得到,而后者可以从互联网中下载。在命令行调用一节中已经提供了下载地址。
完成以上操作后,在
Package Explorer中的项目目录之下,可以在Referenced Libraries目录中看到以上三个Jar程序包,则成功引用了FNLP。 -
修改最大内存量
接下来修改程序的可用内存大小。由于FNLP的语言模型加载需要较大内存,Java默认的内存量通常不足,因此尽量设为1024MB或更大。
在
Package Explorer中选择项目名称,右击,在菜单中选择Properties。在弹出的属性窗口左侧选择Run/Debug Settings,则会呈现项目所有的启动配置。选择当前的启动配置,并点击右侧Edit...,出现Edit Configuration窗口。选择Arguments栏,找到VM arguments输入框,并添加如下参数:-Xmx2048m其中2048m表示允许最大内存空间2048MB,可以按需要进行修改,最后点击确认离开配置窗口。
修改内存量
-
添加模型文件
模型文件指词典、训练后的中文分词器、POS标注器等,它们位于FNLP源码目录下的“models”目录之中。将此目录复制到Eclipse项目目录之下即可。
项目目录可以通过如下方法找到:在
Package Explorer的项目名称上右击,选择Properties,出现属性窗口。窗口左侧选择Resource,则Location的内容即为项目目录。Eclipse项目文件结构



1.3.2 在Intellij IDEA中引用FNLP
Intellij IDEA是近几年流行起来的IDE,引用FNLP库也十分简单(以IDEA 13版本为例)。
-
添加库引用
对于单个模块的应用程序,建议在IDE左侧
Project视图的项目目录中添加“libs”目录,查找并向此目录中复制如下Jar文件:- fnlp-core-2.1-SNAPSHOT.jar
- trove4j-3.0.3.jar
- commons-cli-1.2.jar
以上三个文件的获取请参考上一节。完成上述操作后,可以在
Project视图的“libs”目录中看到三个Jar文件。依次在文件上右键,选择Add as Library...,出现创建库窗口,在窗口中选择合适的配置,确认即可。对于多模块的应用程序,也可以在
Project Structure窗口的Libraries中添加库引用。使用这种方法添加的引用,需要添加了如上三个Jar程序包后,在Libraries中的程序包上分别右键,选择Add to Modules...,选择合适模块,以便所有调用FNLP的模块可以得到引用。 -
修改最大内存量
FNLP在载入语言模型时需要内存量较大,建议设为1024MB以上。点击菜单
Run,Edit Configurations...,出现运行配置窗口。在窗口的左侧Application栏目中选择当前的应用程序后,在窗口中的VM options中添加如下参数:-Xmx2048m其中2040m表示最大内存为2048MB,可以按需要进行修改,最后点击确认离开配置窗口。
Intellij IDEA 修改内存量
-
添加模型文件
FNLP的模型文件包含中文词典、已训练的分词器、POS标注器等,它们位于FNLP源码目录的“models”目录之中。只需把“models”目录复制到当前的项目目录即可。
项目目录可以通过如下方式查找:在IDE的
Project视图中,选择项目名称,右击并选择Show in Explorer(Windows系统)或Reveal in Finder(OS X系统)。

1.3.3 Hello World!
创建一个Java项目,参考上一节准备好环境配置,就可以顺利的调用FNLP进行自然语言处理了。接下来以一个控制台项目为例,一步一步实现最简单常见的任务。
FNLP提供了一系列中文处理工具,其中中文分词、词性标注、实体名识别等基础功能已经封装在工厂类CNFactory之中。CNFactory位于org.fnlp.nlp.cn包之中,经过初始化后就可以使用其提供的全部功能:
import org.fnlp.nlp.cn.CNFactory;
CNFactory factory = CNFactory.getInstance("models");
以上代码创建了一个CNFactory对象,并载入位于“models”目录下的模型文件。接下来就可以使用CNFactory的对象来进行各种中文语言处理任务。
-
中文分词
CNFactory.seg(String)方法提供了中文分词功能。在main函数中写入如下代码:public static void main(String[] args) throws Exception { // 创建中文处理工厂对象,并使用“models”目录下的模型文件初始化 CNFactory factory = CNFactory.getInstance("models"); // 使用分词器对中文句子进行分词,得到分词结果 String[] words = factory.seg("关注自然语言处理、语音识别、深度学习等方向的前沿技术和业界动态。"); // 打印分词结果 for(String word : words) { System.out.print(word + " "); } System.out.println(); }编译运行,就可以得到分词结果:
关注 自然 语言 处理 、 语音 识别 、 深度 学习 等 方向 的 前沿 技术 和 业界 动态 。 -
中文词性标注
CNFactory.tag2String方法提供了中文词性标注功能。在main函数处写入如下代码:public static void main(String[] args) throws Exception { // 创建中文处理工厂对象,并使用“models”目录下的模型文件初始化 CNFactory factory = CNFactory.getInstance("models"); // 使用标注器对中文句子进行标注,得到标注结果 String result = factory.tag2String("关注自然语言处理、语音识别、深度学习等方向的前沿技术和业界动态。"); // 显示标注结果 System.out.println(result); }编译运行,可以得到标注结果:
关注/动词 自然/名词 语言/名词 处理/动词 、/标点 语音/名词 识别/名词 、/标点 深度/形容词 学习/名词 等/省略词 方向/名词 的/结构助词 前沿/名词 技术/名词 和/并列连词 业界/名词 动态/名词 。/标点 -
实体名识别
CNFactory.ner(String)函数提供了实体名识别功能。在main函数中写入如下代码:public static void main(String[] args) throws Exception { // 创建中文处理工厂对象,并使用“models”目录下的模型文件初始化 CNFactory factory = CNFactory.getInstance("models"); // 使用标注器对包含实体名的句子进行标注,得到结果 HashMap<String, String> result = factory.ner("詹姆斯·默多克和丽贝卡·布鲁克斯 鲁珀特·默多克旗下的美国小报《纽约邮报》的职员被公司律师告知,保存任何也许与电话窃听及贿赂有关的文件。"); // 显示标注结果 System.out.println(result); }编译运行,得到识别结果:
{詹姆斯·默多克=人名, 鲁珀特·默多克旗=人名, 丽贝卡·布鲁克斯=人名, 纽约=地名, 美国=地名}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号