机器学习(sklearn-KNN数字识别分类)
需求:基于KNN手写数字识别
实验分析:
1.样本数据模型训练,0-9的10数字,每个数字图片共计500张,用于训练数据
2.图片识别:加载一张图片,通过读出图片数据,降维生成同样本数据相同像素进行比较
实验包数据下载:提取码
第一步:样本数据的提炼,存放在样本数据中
import numpy as np # bmp 图片后缀 import matplotlib.pyplot as plt %matplotlib inline from sklearn.neighbors import KNeighborsClassifier # 创建数据列表,存放图片数据 # 存放特征数据 feature = [] # 存放目标数据 target = [] # 图片存放位置 例如:/data/3/3_33.bmp # data文件夹中存放0-9的图片,每个数字500中写法 for i in range(0,10): for j in range(1,501): img_path = './data/'+str(i)+'/'+str(i)+'_'+str(j)+'.bmp' img_arr = plt.imread(img_path) feature.append(img_arr) target.append(i)
第二步:将存放的列表内的样本数据转换成np.array类型数据,再降维变成2维数据
feature = np.array(feature) target = np.array(target) feature.shape #特征是三维 #需要变形成二维 feature = feature.reshape(5000,784) feature.shape # target.shape # 结果>>>(5000, 784)
第三步:样本数据的打乱操作,便于样本数据的模型训练及样本数据测试
随机数种子(因子),种子数值量确定后,则打乱的随机数方式相同,保证特征数据与目标数一一对应
# 将样本数据打乱 # 设置打乱的随机数因子3,随机数因子相同时,每次打乱结果则会相同 # 设置随机数因子 np.random.seed(3) # 打乱特征数据 np.random.shuffle(feature) np.random.seed(3) # 打乱目标数据 np.random.shuffle(target) # 获取训练数据和测试数据 x_train = feature[:4950] y_train = target[:4950] x_test = feature[4950:] y_test = target[4950:]
第四步:实例化模型对象,进行机器模型的训练
knn = KNeighborsClassifier(n_neighbors=15) knn.fit(x_train,y_train) knn.score(x_test,y_test) # k的score结果>>>0.96
第五步:训练模型的保存
数据模型的训练需要花大量的时间,我们把训练好的模型存入本地,每次使用则重本地加载即可
#保存训练好的模型 from sklearn.externals import joblib # 保存训练模型后缀名必须为.m类型文件 joblib.dump(knn,'./digist_knn.m') #结果>>>['./digist_knn.m'] #返回保存路径 #加载训练模型 knn = joblib.load('./digist_knn.m') #结果>>> KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=15, p=2, weights='uniform')
第六步:测试真实目标数据与模型分类生成的目标数据对比
#使用测试数据测试模型的精准度 print('已知分类:',y_test) print('模型分类结果:',knn.predict(x_test)) # 结果>>> 已知分类: [4 5 7 9 7 5 7 6 8 6 4 1 3 4 8 4 2 0 1 2 0 5 8 6 5 9 3 9 1 8 9 6 4 1 5 2 8 7 7 2 5 3 5 5 6 1 1 3 6 3] 模型分类结果: [4 5 7 9 7 5 7 6 8 6 1 1 3 4 8 4 1 0 1 2 0 5 8 6 5 9 3 9 1 8 9 6 4 1 5 2 8 7 7 2 5 3 5 5 6 1 1 3 6 3]
第七步:加载外部图片,剪切处理,获取某一个需要测试的数字图片
#将外部图片带入模型进行识别 img_arr = plt.imread('./数字.jpg') plt.imshow(img_arr)
加载的原始图片
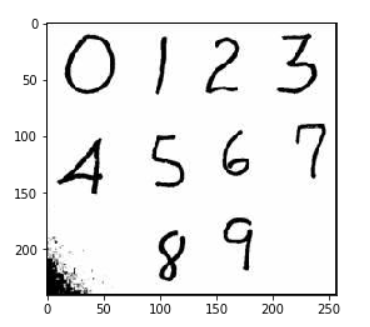
第八步:剪切处理后的图片,这里我们测试数字3,通过数组的切片获取
three = img_arr[3:70,200:240]
plt.imshow(three)
加载剪切后的数字3

第九步:将剪切后图片数据进行处理,最后得到同样本数据相同的数据结构,再通过机器模型分类,得到最后结果
1.需要转换成样本类型np.array
2.需要同样本数据相同的维度2维
3.需要同样本数据相同的像素28*28
# 查看图片数据类型 数据:3维数据类型(像素:67*40 颜色:3) three.shape #结果>>>(67, 40, 3) # 需要对图片数据进行降维 降维有特定算法 # 这里我们采用的不精确的方式,对颜色做平局值计算,达到降维 three = three.mean(axis=2) three.shape #结果>>>(67, 40) # 像素的等比例压缩,使当前图片像素与样本数据像素相同(28*28) import scipy.ndimage as ndimage # 等比缩放到28*28 three = ndimage.zoom(three,zoom = (28/67,28/40)) three.shape #结果>>>(28, 28) # 将二维图片数据转换成样本数据样式1*784 three = three.reshape(1,784) three.shape #结果>>>(1, 784) # 图片结果分类 knn.predict(three) #结果>>>array([3]) #识别图片为数字3
完!
https://www.cnblogs.com/WiseAdministrator/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号