MySQL——优化(四):优化技巧2
以下内容只针对innodb,mysql版本基于5.6
一.join优化
1、优化算法
优化算法了解:嵌套循环-NLJ(Nested-Loop Join)、块嵌套循环-BNLJ(Block Nested-Loop Join)、MRR(mUlti Range Read)、批量键值访问-BKA(Batched Key Access Join)、Hash Join(mysql 8.0后引入)
- NLJ
最基础的算法,相当于只实现了功能,没考虑性能

- BNLJ
利用缓存将t1,t2的join结果存入缓存
缓存默认256K,show variables like 'join_ buffer_size'
存在问题?t3每条匹配结果都存在一次IO

- MRR
将随机IO转换为顺序IO,从而提升性能;
利用缓存按照主键排序后一次性读取,但是排序也会影响性能
read_ rnd_ buffer size :指定mrr缓存大小
- BKA
可理解为BNLJ和MRR的结合
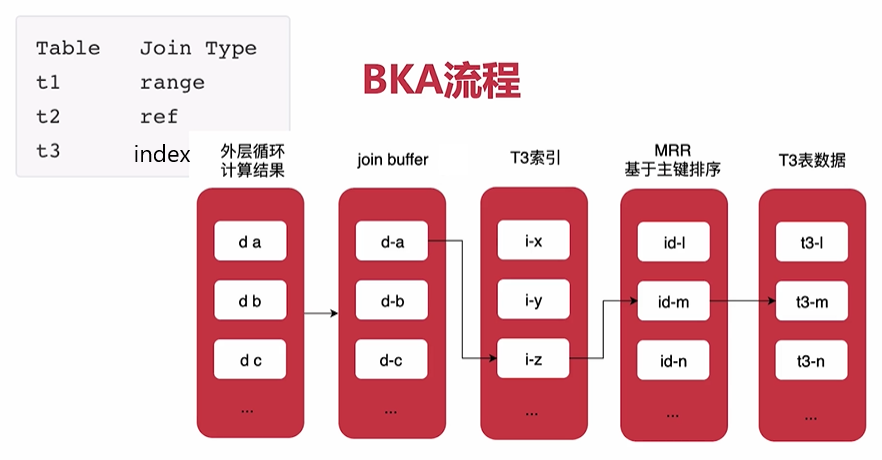
- Hash Join
用来代替BNLJ
2、优化原则
- 小表驱动大表:一般优化器会自动处理,如果优化器自动处理不符合原则,可使用 STRAIGHT_JOIN
- where条件:应当使用索引,并尽可能的减少外层循环的数据量
- join字段应有索引,并且join字段的类型要一致
- 尽量减少扫描的行数(explain-rows控制在百万内性能较好)
- 尽可能参与join的表不要太多,阿里规约建议不超过3张,超过的建议进行SQL拆分为多个SQL,并在服务器内存中再组装数据
二、limit优化
示例:select * from t_order limit 300000,10;
方案1:覆盖索引
select order_no from t_order limit 300000,10;
如果一定要查询覆盖索引字段外的其他字段呢?
方案2:覆盖索引+join
select * from t_order o inner join
(select id from t_order limit 300000,10) t on o.id = t.id;
方案3:覆盖索引+子查询
select * from t_order where id >=
(select id from t_order limit 300000,1) limit 10
方案4:范围查询+limit
select * from t_order where id > 100000 limit 10
前提条件:能拿到上一页主键的最大值
5、如果能够获得起始主键值和结束主键值
select * from t_order where id between 100000 and 100010
6、禁止传入过大页码
比如超过设计目标页码时则提示禁止或者执行默认页码的逻辑
三、count优化
1、优化结论
COUNT(*)和COUNT(1)对于innodb性能一样没有区别,MyISAM 不带where条件时count(*)会更快

COUNT(*)会选择最小的非主键索引,不存在则使用主键
COUNT(字段)会排除为null的行,count(*)不会排除
尽量使用COUNT(*):mysql后续版本innodb也会对不带任何条件的COUNT(*)做优化,
2、count(*)自动优化分析
- 结论
- 当没有非主键索引,会使用主键索引
- 如果存在非主键索引,使用非主键索引
- 如果存在多个非主键索引,会食用最小的非主键索引
- 原因
- innodb非主键索引的叶子节点存储内容是:索引+主键;
- 主键索引叶子节点存储内容是:主键+表数据,
- 所以非主键索引的数据的更小,在1个page里,非主键索引可以存储更多的条目,从而扫描次数会更小,性能更快
- 多个非主键索引之前他会选择性能更快的,及非主键索引存储内容数据更小的
- 示例和优化方案
select count(*) from t_order;
方案1:创建一个更小的非主键索引
主流的基本方案
方案2:换成MyISAM引擎-->一般不这样做
方案3:添加一张汇总表table,增加了维护的成本
方案4:sql_calc_found_rows
SELECT SQL_CALC_FOUND_ROWS * from t_order where user_no >0 ;
SELECT FOUND_ROWS() ;
在做完本条查询后,会自动执行count
缺点:mysql8.0.17已经废弃,需要在mysql终端执行才能正常返回结果,并且没有索引覆盖时,性能低于count(*)
方案5:缓存
优点:性能高,结果比较准确。
缺点:引入额外的组件,增加了架构的复杂度
以下6、7、8都是估算值
方案6:information_schema.tables
优点:不操作原始表,返回结果迅速
缺点:估算值,并不准确
方案7:show table status where name = 'salaries'
优缺点同方案6
方案8: explain select * from salaries
rows就是行数 优缺点同方案7
四、order by优化
1、利用索引避免排序
如果order by子句的条件正好是索引,就可以利用索引本身的有序性,让mysql跳过排序过程
比如 t_order表有组合索引 index idx_create_time_pay_time(create_time,pay_time)
那么是否能使用索引避免排序
【能】 select * from t_order order by create_time, pay_time;
【不能】select * from t_order order by create_time desc, pay_time asc;
【能】 select * from t_order WHERE create_time = '2020-01-01' order by pay_time;
【能】 select * from t_order WHERE create_time < '2020-01-01' order by create_time;
【不能】select * from t_order WHERE create_time < '2020-01-01' order by pay_time;
【能】 select * from t_order WHERE create_time = '2020-01-01' and pay_time > '2020-01-01' order by pay_time;
【不能】select * from t_order order by create_time, id;
- 分析:
- 利用索引本身的有序性和用比较的思路来分析,排序类比Java和.net中的排序比较接口:Comparable和IComparable
- 测试说明
- mysq优化器发现全表扫描开销更低,会直接用全表扫描
- 无法利用索引避免排序的情况(都可归类为不符合最左前缀原则)
- 排序字段存在于多个索引
- 组合索引的排序升降序不一致
2、文件排序
rowid排序
1.从表中获取满足WHERE条件的记录
2、对于每条记录,将记录的主键及排序键(id,order. column)取出放入sort buffer (由sort. buffer. size控制)(第一次IO)
3、如果sort buffer能存放所有满足条件的(id,order_ column) ,则进行排序;否则sort buffer满后,排序并写到临时文件
- 排序算法:快速排序算法
4、若排序中产生了临时文件,需要利用归并排序算法,从而保证记录有序
- 排序算法:归并排序算法
5、循环执行上述过程,直到所有满足条件的记录全部参与排序
6、扫描排好序的(id,order_ _column)对,并利用id去取SELECT需要返回的其他字段(第二次IO)
7、返回结果集
全字段排序
在rowid基础上进行的优化(空间换时间),直接取出SQL中所需要的所有字段,放到sort buffer
optimizer_trace分析
filesort_summary解读(不同分析器版本字段位置会有所不同)
1、memory_available :可用内存,其实就是sort_buffer_size配置的值
2、num_rows_found :有多少条数据参与排序,越小越好
3、num_initial_chunks_spilled_to_disk :产生了几个临时文件, 0表示完全基于内存排序
4、sort_mode
●<sort_ key,="" rowid=""> :使用了rowid排序模式
●<sort_ key,="" additional_="" fields=""> :使用了全字段排序
●<sort_ key,="" packed_="" additional_="" fields=""> :使用了打包字段排序
五、group by/distinct优化
处理groupby的三种方式
- 松散索引扫描,性能最好, explain中会有Using index for group-by
- 紧凑索引扫描,性能第二, explain中无明显标识
- 临时表,性能最差, explain中会有Using temporary
优化措施:避免临时表,使用松散/紧凑索引扫描
1、松散索引扫描
举例说明松散索引扫描
select name,min(score) from t_student group by name
index(name,score)
[A,75]
[A,80]
[A,90]
...
[B,70]
[B,80]
[B,95]
...
基本搜索:
1.先扫描name =A的数据,并计算出最低的score是多少[A,75]
2.扫描name =B的数据,并计算出最低的score是多少[B,70]
3.再遍历返回每个学生的最低分数
松散搜索:
1.先扫描name =A的数据,取出第一条[A,75] =>就是最低的score
2.扫描name =B的数据,取出第一条[B,70] =>就是最低的score
3.以此类推
假设有index(C1,c2,c3)作用在表t1(C1,c2,C3,c4)上,下面这些SQL都能使用松散索引扫描:
SELECT c1, c2 FROM t1 GROUP BY c1, c2;
SELECT DISTINCT cl, c2 FROM t1;
SELECT c1, MIN(C2) FROM t1 GROUP BY c1;
SELECT c1, c2 FROM t1 WHERE c1 < const GROUP BY c1,c2;
SELECT MAX(C3),MIN(C3), c1, c2 FROM t1 WHERE c2 > const GROUP BY c1, c2;
SELECT c2 FROM t1 WHERE c1≤const GROUP BY cl, c2;
SELECT c1, c2 FROM t1 WHERE c3 = const GROUP BY cl, c2;
SELECT cl, SUM(c2) FROM t1 GROUP BY c1;
下面这些SQL不能使用松散索引扫描:
--聚合函数不是MIN( )或MAX()
SELECT cl, SUM(c2) FROM t1 GROUP BY c1;
--不符合最左前缀原则
SELECT cl, c2 FROM t1 GROUP BY c2,c3;
--查询了c3字段,但是c3字段上没有等值查询
--改成SELECT c1, c3 FROM t1 WHERE c3=const GROUP BY c1, c2;则可以使用
SELECT c1, c3 FROM t1 GROUP BY c1,c2;
总结:
查询要作用在单张表上
group指定字段要符合最左前缀原则,且没有其他字段
如果有集合函数,只能有min()、max()
索引必须是整个字段的值,不能是前缀索引
2、紧凑索引扫描
需要扫描满足条件的所有索引键才能返回结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号