MySQL——优化(一):理论基础
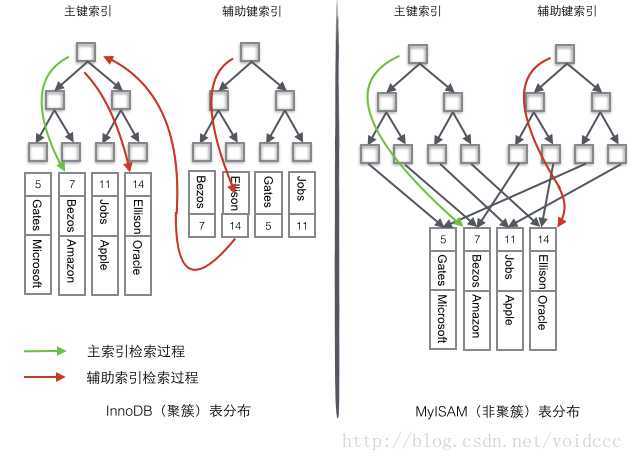
一、InnoDB和MyISAM的存储方式
1、InnoDB存储方式
- 使用的B+Tree数据结构,物理存储角度是聚簇索引
- 对于主键索引: 叶子节点会存储主键以及主键所对应数据块的指针;
- 对应非主键索引(二级索引、辅助索引):叶子节点存储索引以及这条数据对应的主键;需要先通过非主键索引查到主键,然后通过主键查询出数据;
2、MyISAM存储方式
- 使用的B+Tree数据结构,物理存储角度是非聚簇索引
- 主键/非主键索引的叶子节点都是存储着指向数据块的指针;
3、索引类型
从数据结构角度,可分为:B+树索引、Hash索引、空间数据索引(R-Tree索引)、全文索引
从物理存储角度,可分为:聚簇索引、非聚簇索引
从功能逻辑角度,可分为:普通索引、唯一索引、主键索引、组合索引、全文索引
二.索引数据结构
1、二叉树
最大查询时间复杂度O(n),查询不稳定

2、平衡二叉树
平衡二叉树(Balanced Binary Tree)又被称为AVL树
每个节点的左子树和右子树的高度差不超过1;
优点:对应n个节点而言,树的深度是 log2n,查询的时间复杂度是 O(log2n),查询比上面的二叉树稳定;
缺点:对于更多的节点,树的深度还是很大的,这也意味着查询次数会很多
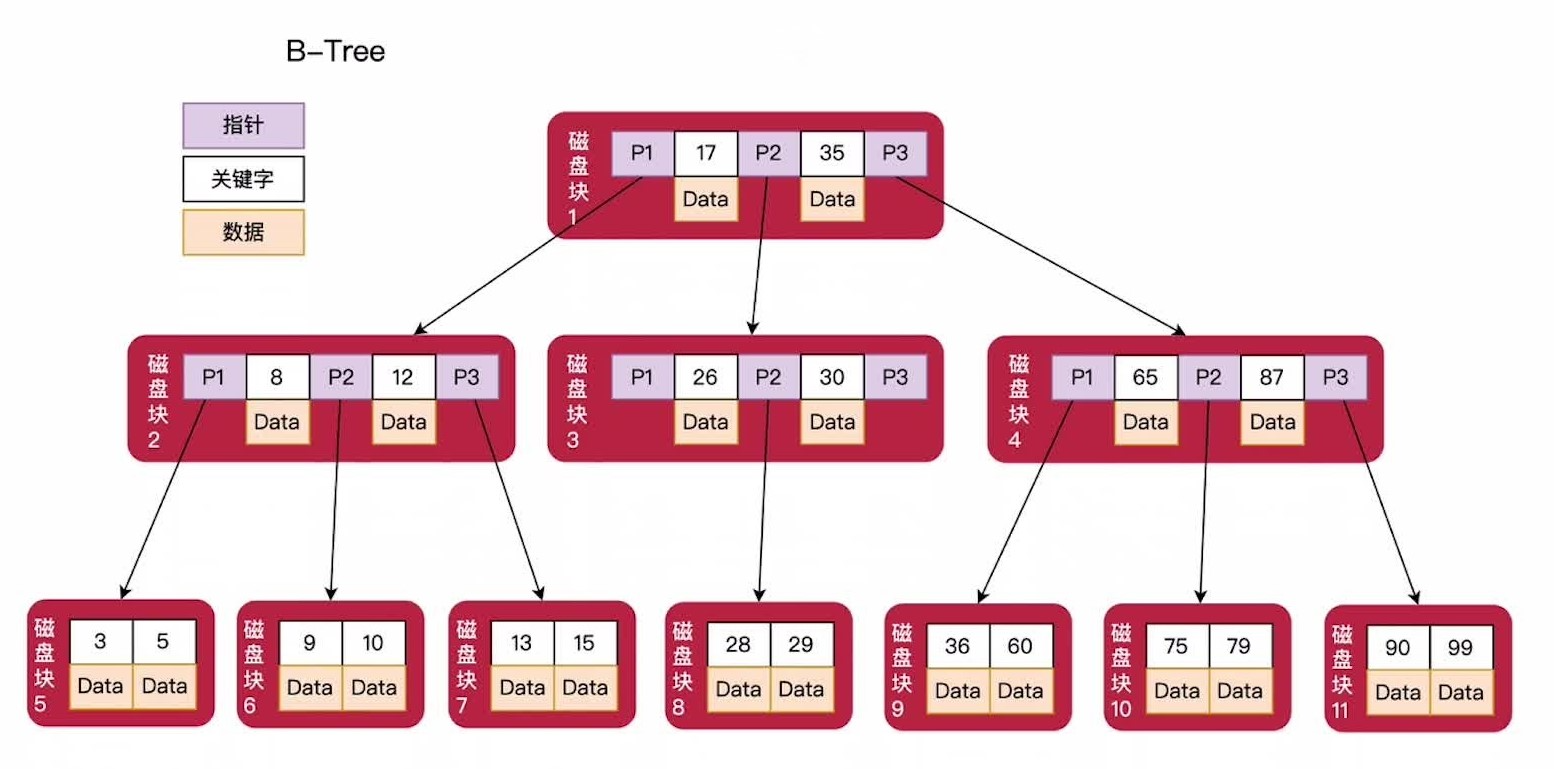
3、B-Tree(Balance Tree)
B-Tree特性:
- 根节点的子节点个数 2<=x<=m, m是树的阶;假设m=3; 根节点可以拥有2到3个子节点;
- 中间节点的子节点个数在 m/2<=y<=m之间;假设m=3,中间节点至少有两个子节点,最多有三个子节点;
- 每个中间节点允许包含子节点个数-1个关键字,并且关键字按照升序进行排序;
- 一个磁盘节点包含关键字n个,那么同时他会包含n+1个磁盘指针
4、B+Tree
- B+Tree是B-Tree基础上的一种优化;
- MySql中的InnoDB和MyISAM存储引擎使用的就是B+Tree数据结构;
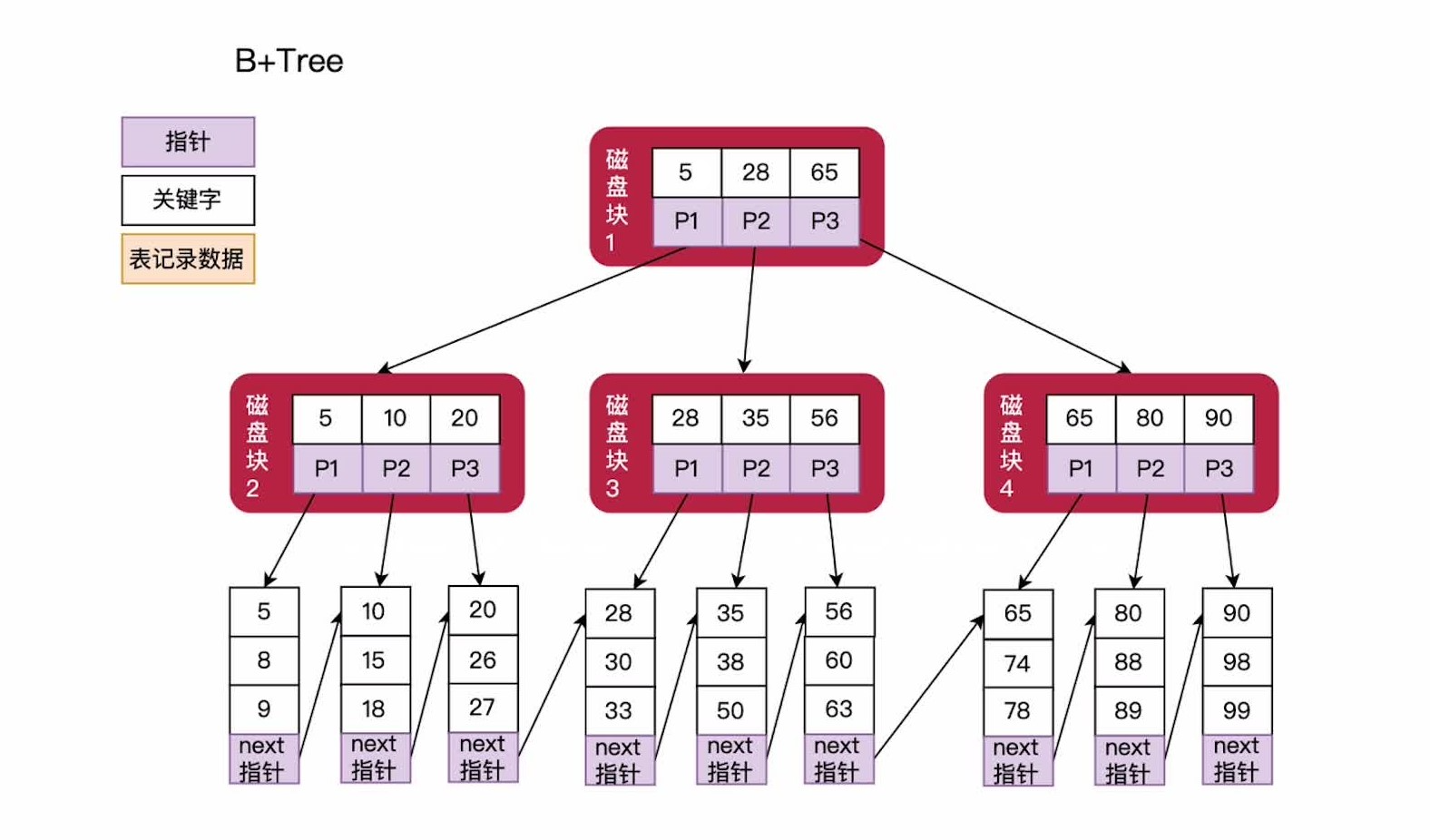
4.1、搜索过程
- 假设 我们搜索关键字n,先将n和磁盘根节点的关键字做比对,假设n等于8,关键字指针就会指向P1,找到字节点 磁盘块2;
- 然后继续做比对,发现8在 5-10之间,那么就会指向磁盘块2的P1指向指向下一节点;
- 如果下一节点为 叶子节点,那么就会去从叶子节点中,将关键字信息查找出来;
4.2、B-Tree和B+Tree之间的差异
结构差异:
- 包含关键字个数不同
- B+Tree有n个子节点的节点,他可以包含n个关键字
- B-Tree中含有n个子节点的节点,只能包含n-1个关键字;
- 叶子节是否包含全部关键字
- B+Tree中,所有的叶子节点包含了全部关键字信息;并且叶子节点按照关键字大小从小到大顺序连接,构成一个有序链表;
- B-Tree的叶子节点不包括全部关键字,他的关键字可能出现在中间节点甚至在根节点;
- 非叶子节点存储内容不同
- 在B+Tree中,非叶子节点仅用于索引,不保存数据记录;
- B-Tree,非叶子节点既可以保存索引,也保存数据;
- 由于B+Tree的中间节点只存放索引,所以对于相同的空间,B+Tree中间节点存放的关键字更多;所以B+Tree稍微矮胖一些;
功能差异:
- 查询效率稳定性
- B-Tree的查询效率不稳定,可能会在根节点都找到数据,也可能在叶子节点找到数据;
- B+Tree不管怎么样都只能在叶子节点查询到数据
- B+Tree的范围查询比B-Tree支持的更好;
- B-Tree只能一次一次查询,B+Tree可以一次性查询;
5、B-Tree(B+Tree)的共同特性
完全匹配: index(name) ==> 使用 where name = ‘ ’可以用到索引的;
范围匹配: index(age) ==> 使用 where age > 5 可以用到索引;
前缀匹配: index(name) ==> where name like 'xxx%' 可以使用到索引;注意: %放在前面就无法使用索引
6、B-Tree(B+Tree)索引的限制(最左前缀原则)
- 组合索引限制index(name,age,sex)
- 查询条件不包括最左列,无法使用索引;比如,这里最左列是 ‘name’,语句 where age=5 and sex=1无法使用索引;
- 查询条件不能跳过索引中的列,否则无法完全使用索引;比如,where name = 'xx' and sex = 32 ===> 只能使用name这一列索引;
- 查询中有某个列的范围(模糊)查询,则它的右边的所有列都无法使用索引;比如,where name = 'xx' and age>32 and sex = 1, 这时sex无法使用索引,因为age使用了范围查询
- 总结:最左前缀原则,索引按照最左优先的方式匹配索引,不满足上面所说的三个条件的时候,则无法完全使用索引;
特殊优化技巧:创建索引的列相同,但是索引列的顺序不同的索引(已废弃,优化器会自动优化,不完全相同的列有共同的索引列时可考虑)
7、Hash索引
1、hash索引不是按照索引值排序,所以排序(包含 Order By )不能用索引
2、Hash索引是使用索引列的全部值去计算的,不支持部分匹配 hash(a,b),不支持只有a的条件查询 where a = ?;
3、只支持等值查询(例如=、IN),不支持范围查询、模糊查询
4、一般比B-Tree(B+Tree)的性能稍微好一些,只要hash不冲突,那么他的时间复杂度就是O(1),hash冲突越严重,性能下降越快。

其他参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号