Python-爬虫基础十一(POST请求百度翻译)
一、POST请求数据流程
以百度翻译网页进行分析。使用场景为:用户填入信息,页面对其进行翻译。
按 F12 打开控制台,依次点击 Network > XHR(此为异步加载的网络数据包),再点击左侧 URL 链接,在右侧的 payload和Preview 栏能够看到对响应内容的预览信息,其中包含用户输入的内容,故此 URL 是我们需要的。
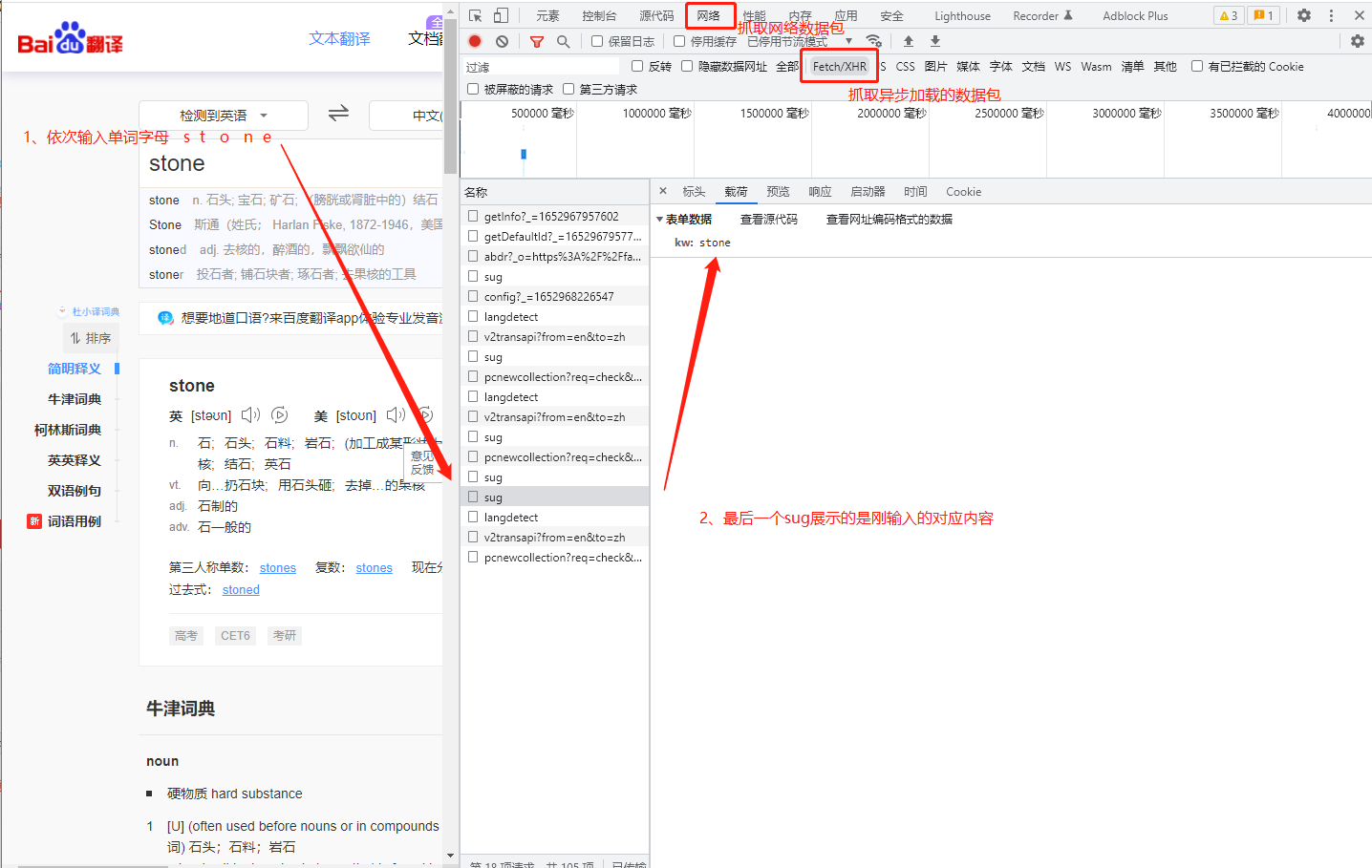
确定了URL信息,点击 Headers 栏,查看整个请求信息
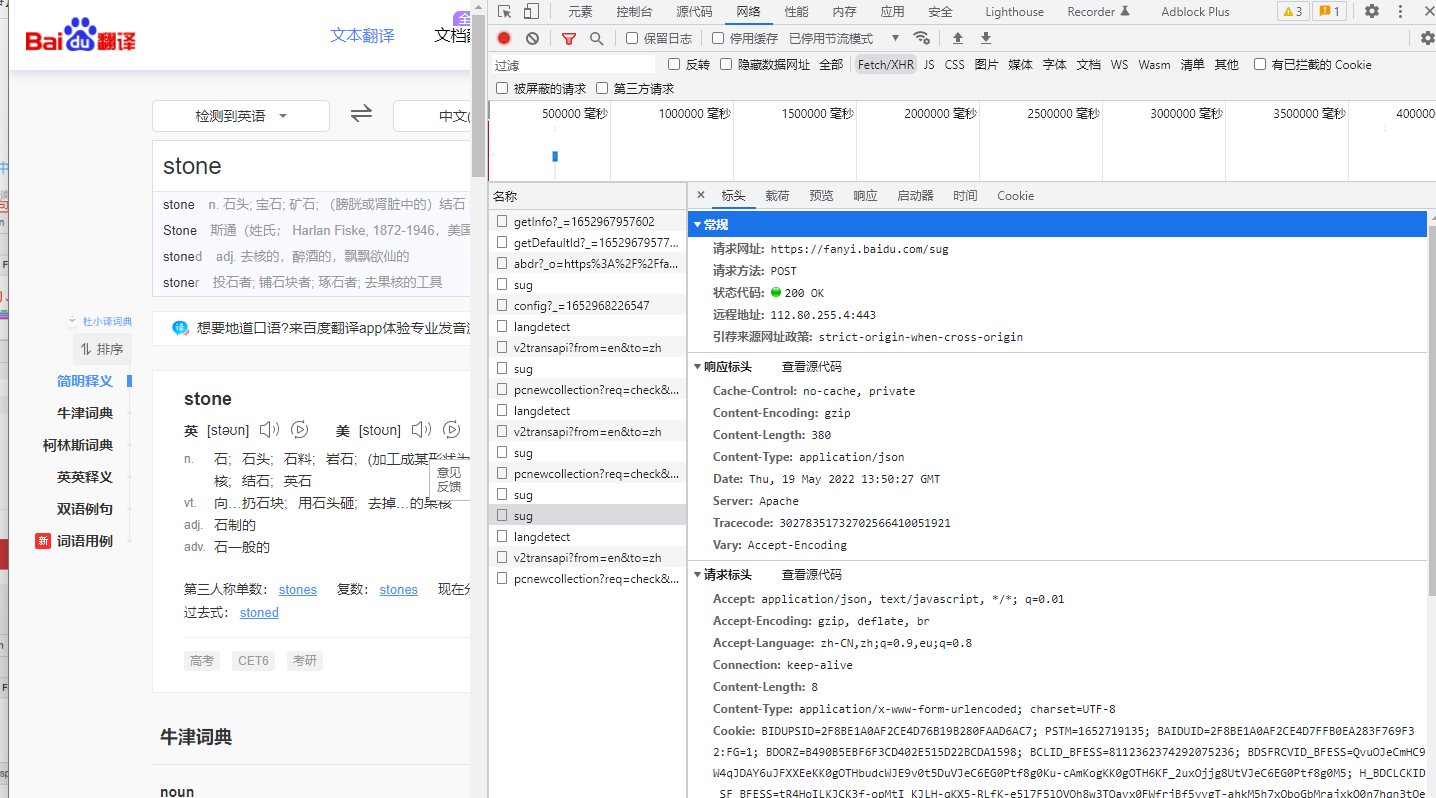
整体逻辑是:用户在页面输入文字信息后,程序会生成对应的表单数据(Payload 栏中的 Form Data),用其数据和 Headers 信息(Headers 栏中 Request Headers)向 URL(Headers 栏中 General 里的 Request URL) 发起 POST 请求,服务端响应并返回数据(Preview 栏中信息)。
实例一:
#post请求 https://fanyi.baidu.com/sug import urllib.request import urllib.parse url = ' https://fanyi.baidu.com/sug' #请求头复制过来 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36' } #声明需要查什么单词语句 q = input('请输入要查询的单词:') data = { 'kw':q } # post请求的参数 必须要进行编码 data = urllib.parse.urlencode(data).encode('utf-8') # post的请求的参数 是不会拼接在url的后面的 而是需要放在请求对象定制的参数中 # post请求的参数 必须要进行编码 request = urllib.request.Request(url=url,data=data,headers=headers) # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(request) # 获取响应的数据 content = response.read().decode('utf-8') # 字符串--》json对象 import json obj = json.loads(content) print(obj)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号