Python-爬虫基础五(文件操作)
一、文件的打开与关闭
打开文件/创建文件
使用open函数可以打开一个已经存在的文件,或者创建一个新文件
open(文件类路径,访问模式)
示例:
f = open('test.txt','w')
说明:
文件路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。
- 例如:E:\python,从电脑的盼复开始,表示的就是一个绝对路径
- 相对路径:是从当前文件所在的文件夹开始的路径。
- test.txt 是在当前文件夹查找test.txt 文件
- ./test.txt 是在当前文件夹查找test.txt 文件, ./ 表示的是当前文件夹
- .//test/txt 从当前文件夹的上一级文件夹里查找test.txt 文件, .// 表示的是上一级文件夹
- demo/test.txt 在当前文件夹里查找 demo 这个文件夹,并在这个文件夹里查找 test.txt 文件
二、文件的读写
写数据(write)
使用write()可以完成向文件写入数据
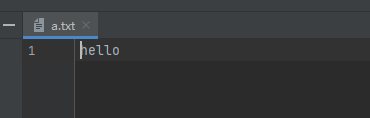
# 文件的打开/新建 无法直接新建文件夹 fp = open('a.txt','w') # 文件的写入 fp.write('hello') # 文件的关闭 fp.close()
读数据 read
- 默认情况下 read是一字节一字节的读 效率比较低
- readline是一行一行的读取 但是只能读取一行
- readlines可以按照行来读取 但是会将所有的数据都读取到 并且以一个列表的形式返回 列表的元素 是一行一行的数据
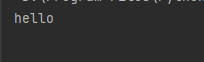
fp = open('test1.txt','r') print(fp.read())
read
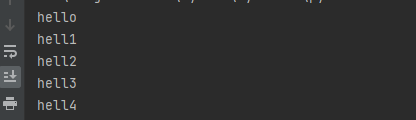
readlines

readline
三、序列化和反序列化
通过文件操作,外面可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、字符串等)就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节顺序,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化。
Python中提供了json这个模块用来实现数据的序列化和反序列化。
JSON模块
JSON(JacaScriptObjectNotaction,JS对象简谱)是一种轻量级的数据交换标准。JSON的本质是字符串
使用JSON实现序列化
JSON提供了dump和dumps方法,将一个对象进行序列化。
dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
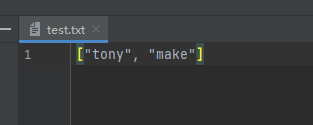
##导入JSON模块到该文件中 import json #文件的序列化和反序列化 #1、创建一个文件 fp = open('test.txt','w') ## 默认情况下 对象是无法写入到文件中 如果想写入到文件 那么必须使用序列化操作 #2、定义一个列表 name_list = ['tony','make'] #3、序列化 #将python对象变成 JSON字符串 #应用场景 在使用scrapy框架的时候 该框架会返回一个对象 我们要将对象写入到文件中 就要使用json.dumps names = json.dumps(name_list) print(type(names)) ##>><class 'str'> #此时已经将列表转换成了字符串 #4、将names写入到文件中 fp.write(names) #5、关闭 fp.close()
反序列化
- loads
##导入JSON模块到该文件中 import json #反序列化 loads load fp = open('test.txt','r') content = fp.read() print(content) #>>["tony", "make"] print(type(content)) ##此时为str #>><class 'str'>##将JSON字符串变成python对象 result = json.loads(content) ##转换之后 print(result) #>>['tony', 'make'] print(type(result)) ##此时为列表类型 #>><class 'list'>
- load
##导入JSON模块到该文件中 import json fp = open('test.txt','r') result = json.load(fp) print(result) #>>['tony', 'make'] print(type(result)) #>><class 'list'> ##此时转换成了list fp.close() ##此时加载的是文件 一定要close

 浙公网安备 33010602011771号
浙公网安备 33010602011771号