汇集最新各大顶会的时序论文整理
时序监督学习
PatchTST
ICLR-2023

TimeMixer
ICLR-2024

ICLR'24 | LIFT :Rethinking Channel Dependence for Multivariate Time Series Forecasting: Learning from Leading Indicators
paper:https://arxiv.org/abs/2401.17548
code:https://github.com/SJTU-DMTai/LIFT
highlights:提出了一种新方法LIFT(Learning from Leading Indicators),该方法识别并利用局部平稳的领先滞后关系。它认为某些变量(滞后变量)在短期内跟随特定的领先指标,从而可以利用这些领先信息来提高预测准确性。具体来说,通过在每个时间步长上估计领先指标及其领先步数,允许滞后变量利用这些提前信息,从而降低了预测难度,尤其是在处理具有时间差的相关变量时。LIFT作为一个插件,可以与任意时间序列预测方法结合使用。
动机:

结构:

实验:


NIPS2024-FilterNet:利用频率滤波器进行时间序列预测
title:Filter:Harnessing Frequency Filters for Time Series Forecasting
paper:https://arxiv.org/pdf/2411.01623
code:https://github.com/aikunyi/Filt
highlights:
-
提出了一种新颖的信号处理视角: 从信号处理的角度出发,将频率滤波技术应用于时间序列预测,开辟了新的研究方向。
-
设计了两种可学习的频率滤波器: 普通成形滤波器和上下文成形滤波器,分别适用于不同的场景和任务。
-
证明了 FilterNet 的有效性和效率: 在多个时间序列预测基准数据集上进行实验,结果表明 FilterNet 在预测精度和计算效率方面优于现有的方法。
-
进行了深入的分析: 对 FilterNet 的建模能力、滤波器的类型、带宽设置等因素进行了分析,并提供了可视化结果,进一步验证了 FilterNet 的有效性。
频率滤波器:首先,论文提出了两种可学习的频率滤波器:普通塑形滤波器和上下文塑形滤波器。普通塑形滤波器采用通用的频率核进行信号滤波和时间建模,而上下文塑形滤波器则根据输入信号的兼容性来学习数据依赖的滤波器。
频率滤波器块:其次,论文将频率滤波器直接应用于频域,替换了传统的基于MLP或Transformer的建模方法。
前馈网络:最后,论文在前馈网络中投影频率滤波器块提取的时间模式,并进行预测。
2024NIPS-CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
论文标题:CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
论文链接:https://arxiv.org/pdf/2409.18479v1
代码链接:https://link.zhihu.com/?target=https%3A//github.com/ACAT-SCUT/CycleNet
highlights:一种通过对周期模式进行建模来提高时间序列预测性能的方法。这种残差周期预测技术使用可学习的循环周期来显式地对时间序列数据中的固有周期性模式进行建模,然后对建模后的周期的残差分量进行预测

TimeMixer++
ICLR-2025

ICLR2025-MMFNET:用于多变量时间序列预测的多尺度频率掩码神经网络
title:MMFNET: MULTI-SCALE FREQUENCY MASKING NEURAL NETWORK FOR MULTIVARIATE TIME SERIES FORECASTING
paper:https://arxiv.org/pdf/2410.02070
code:暂未公开
highlights:MMFNet 是一种新颖的模型,旨在通过多尺度频率掩码分解方法来增强长期多变量时间序列预测。该模型通过将时间序列转换为不同尺度的频率段,并使用可学习的掩码自适应地过滤掉不相关的成分,从而捕捉细粒度、中间和粗粒度的时间模式。
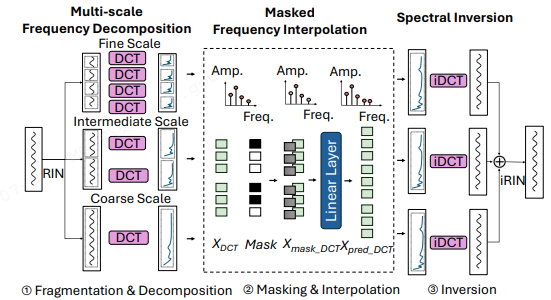
-
MMFNet采用多尺度频域分解方法,以捕捉频域中的动态变化。
-
MMFNet利用可学习的频率掩码,根据时间序列片段的频谱特性,自适应地过滤掉无关的频率成分。
NIPS2023-FreTS:频域中的MLP在时序预测上更有效
title:Frequency-domain MLPs are More Effective Learners in Time Series Forecasting
code:https://github.com/aikunyi/FreTS
highlights:提出了一种新的频率学习架构,该架构在频域中学习通道维度和时间维度的依赖性,并定义了基于频域的MLP学习器。

-
频率通道学习器:将同一时间的不同特征转化到频率,学习特征维度的频率分量
-
频率时间学习器:将不同特征的时间序列转化到频率,学习多元时间序列维度的频率分量
-
频域MLPs:对于复数输入H,定义复数权重矩阵W和复数偏置B,y^l=H:

TFDNet: Time-Frequency Enhanced Decomposed Network for Long-term Time Series Forecasting
highlights:论文提出了一种名为TFDNet的方法。该方法通过时间频率增强编码器处理时间序列数据,其中包括趋势时间频率块和季节时间频率块。趋势时间频率块通过共享核对趋势模式进行处理,而季节时间频率块根据不同数据集的季节特性设计了两个版本,即使用个体核和多个共享核。最后,通过融合编码器表示来预测未来的时间序列。

RIN归一化、时域分解(不同的avgpool尺寸窗口)
短时傅里叶变换,频域滤波器,全连接+tanh函数,逆变换
PatchMixer:一种用于长时间序列预测的Patch混合架构
一种使用patch+CNN结合的序列预测方法

patch对比:定义了频域和时域两种patch化方法
序列全局和局部卷积:patch内和patch间
FreEformer: Frequency Enhanced Transformer for Multivariate Time Series Forecasting
IJCAI-2025
https://arxiv.org/pdf/2501.13989
highlights:定义了一种基于频域的transformer增强架构,在注意力模块引入了一个可学习矩阵,解决低秩性问题

ps:本论文提到的多元序列,只是频域上的多元序列
-
针对输入的序列,先对其进行频域转化;实部和虚部分别进行transformer后,在逆变换至时域,并将时间和特征维度进行flatten拉平操作后,经过linear直接输出预测值
-
注意力机制增强:通过在相似性权重矩阵处,引入一个相同大小的可学习矩阵,解决由于频域引起的低秩性问题

TimeBridge: Non-Stationarity Matters for Long-term Time Series Forecasting | OpenReview
发表会议:ICLR 2025
paper:TimeBridge: Non-Stationarity Matters for Long-term Time Series Forecasting | OpenReview
代码地址:https://github.com/Hank0626/TimeBridge
团队:清华大学、深圳大学
highlights:提出了一种TimeBridge新框架,旨在解决多变量时间序列预测中非平稳性带来的挑战。非平稳性(如短期波动和长期趋势)可能导致虚假回归或掩盖重要的长期关系。现有方法通常要么完全消除非平稳性,要么完全保留,未能有效区分其对短期和长期建模的不同影响。
虚假回归(Spurious Regression)是指在统计分析中,两个或多个非平稳时间序列之间看似存在显著的统计关系,但实际上这种关系是虚假的,仅仅是因为这些序列具有共同的趋势或随机性,而非真正的因果关系。这种现象会导致错误的结论,例如误认为两个无关的变量之间存在相关性。

TimeBridge 的核心思想是通过将输入序列分割为小块(patches),分别处理短期和长期依赖关系:
1、Integrated Attention:用于缓解短期非平稳性,捕捉每个变量内部的稳定依赖关系。
2、Cointegrated Attention:保留非平稳性,建模变量之间的长期协整关系。
CATS
NIPS2024

ICLR2025-TimeKAN
发表会议:ICLR 2025
paper:https://openreview.net/pdf?id=wTLc79YNbh
代码地址:https://github.com/huangst21/TimeKAN
highlights:提出了
动机:任何现实世界中的时间序列常常包含多个相互交织的频率成分,这使得准确的时间序列预测变得具有挑战性。受最近的Kolmogorov-Arnold网络(KAN)的灵活性启发,将混合的频率成分分解为多个单一频率成分是一个自然的选择。由此作者提出了一种基于KAN的频率分解学习架构(TimeKAN),主要由三个组件构成:级联频率分解(CFD)块、多阶KAN表示学习(M-KAN)块和频率混合块。CFD块采用自下而上的级联方法来获取每个频带的序列表示。得益于KAN的高灵活性,作者设计了一种新颖的M-KAN块,用于学习和表示每个频带内的特定时间模式。最后,频率混合块用于将频带重新组合为原始格式。在多个真实世界时间序列数据集上的广泛实验结果表明,TimeKAN作为一种极其轻量级的架构,实现了最先进的性能。
Kolmogorov-Arnold Networks是一种受科尔莫戈洛夫 - 阿诺尔德定理启发的神经网络,核心思想可以用一句话概括:“任何复杂的多变量函数,都能拆成一堆简单的单变量函数的组合”。

- 多级序列
设定一个平滑窗口d,通过移动平均获得多级序列,同时去除高频噪声;接入线性linear嵌入层

这里xi表示第i级序列,x1为原始输入序列
-
频率加强
- 级联频率分解模块,以串级的方式精确分解各个频率分量(分解为高频、中频、低频成分),获得每个频率分量的表示形式。由于第i+1层的长度比第i层的长度小了d个序列点,因此采用零填充的方式;此处只有第一层的x1是无损序列
![]()
![]()
-
多阶 KAN 表示学习模块,作用对不同频率成分进行特征提取,并捕捉时间依赖关系:输入:
- 深度卷积:侧重于序列维度的依赖建模
![]()
这里group数量与嵌入维度相匹配。使用D组卷积核对每个通道的序列进行独立的卷积操作。专注于捕捉时序模式,排除通道间关系干扰。
- 多阶KAN:针对不同频率分量进行特定表示学习,即通道学习;这里使用不同阶数的切比雪夫多项式的线性组合 。切比雪夫多项式(n阶)定义为:
![]()
应用于通道维度的 1 层 ChebyshevKAN 可以表示为:
![]()
![]()
这里n为多项式阶数,D为通道维度,o为输出层索引(低频——>高频)。
将这一组具有不同最高切比雪夫多项式阶数的 KAN 称为多阶 KAN。假设阶数的最低下限为b:
![]()
- 组合:将多阶KAN和深度卷积融合作为第i个尺度的结果:
![]()
-
频域混合








待看列表
-
ENHANCING FOUNDATION MODELS FOR TIME SERIES FORECASTING VIA WAVELET-BASED TOKENIZATIONhttps://arxiv.org/pdf/2412.05244
预训练-自监督学习
时序
AAAI-2022 ——《TS2Vec: Towards Universal Representation of Time Series》
paper地址:https://arxiv.org/pdf/2308.01737
highlights:一种与模型无关的时序表征学习的预训练框架,利用对比学习范式的encoder框架来进行自监督学习。属于前置任务预训练,下游接预测任务。该框架主要包含:
-
数据构造:构造两段长度相等的随机序列:对于每个实例 xi,随机抽取两个重叠的时间片段 [a1, b1]、[a2, b2],使得 0 < a1 ≤ a2 ≤ b1 ≤ b2 ≤ T。
-
encoder设计:编码器由三个组件组成,一个输入投影层(input projection layer)、时间戳Mask模块(timestamp masking )和一个空洞卷积层(dilated CNN)
-
对比损失:从两个维度刻画,一是时间层面的对比,二是实例维度的对比

AAAI 2024 ——TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning
paper地址:https://arxiv.org/pdf/2312.15709
code:https://github.com/Alrash/TimesURL
highlights:和TS2Vec类似,针对用于时间序列表示的对比学习提出了TimesURL,用于捕捉时段级和实例级信息,通过额外的时间重构模块实现通用表示。(在TS2Vec的基础上做了以下三点升级)
-
样本增强:引入了一种基于频域-时间的混合增强方法。
-
在对比学习中注入了新的双重 Universums(一种通过 混合正负样本特征 生成的 难负样本),以解决正负对构建问题,增强对比学习效果。
-
通过随机mask引入了一种时间重构模块(和MAP类似)。

实验:

TPAMI——CA-TCC:Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification
GitHub:https://github.com/emadeldeen24/CA-TCC
highlights:根据强增强和弱增强对输入数据生成两种不同但相关的视图。提出了一个时间对比模块,利用两个自回归模型来探索数据的时间特征。利用一个视图的过去预测另一个视图的未来,从而完成艰难的跨视图预测任务。通过上下文对比模块,最大限度地提高了自回归模型上下文之间的一致性。

对于半监督设置,提出的 CA-TCC 从 TSTCC 预训练阶段开始,包括另外三个阶段来完成半监督训练。

ICLR24—— CARD:Channel Aligned Robust Blend Transformer for Time Series Forecasting
paper:https://arxiv.org/pdf/2305.12095
code:https://github.com/wxie9/CARD
highlights:针对Transformer的通道独立进行改进。引入了一种通道对齐的注意力结构,用来捕捉信号之间的时间相关性以及多个变量随时间的动态依赖性。设计了一个token混合模块来生成不同分辨率(多尺度)的token。引入一种损失,对有限时间范围内的预测重要性进行加权,以减轻过拟合。

NIPS24-patch动态切分:
论文标题:Large Pre-trained time series models for cross-domain Time series analysis tasks
论文链接:https://arxiv.org/abs/2311.11413
论文链接:https://github.com/AdityaLab/Samay
highlights:针对时间序列分析任务中从多领域异构数据提取有效输入的难题,设计了自适应分割模块,它依据自监督预训练损失确定各领域最优分割策略,克服了以往固定长度分割的局限。
动机:自patchTST之后,大多数时序模型都是将输入时间序列分割成patch(等长的片段),并将每个片段作为token输入到模型中。但是这种固定大小的token无法捕捉不同数据集行为的序列语义。不同场景的数据有不同时间尺度和周期性。如,疫情数据通常每周观察一次,可能具有季节性、峰值和突然爆发等特征。相比之下,经济数据通常每季度采集一次,数据分布更单调,有突然的异常和变化。其实对于时间戳更密集的数据,需要比其他松散的数据进行更精细的分割。

-
第一块是打分,这里作者把序列过了一层GRU获得序列表示,然后通过双层循环枚举每种切分可能,并根据公式获得切分的评分值。
-
第二块是选择,枚举每个起始位置对应的最高切分方式。比如:第i时刻,切分方式可能有(i,j),(i,j+1)等等。选出每个起始时刻的最高分。很明显这种选择方式一定能保证切分的序列是连续的,但大概率是有重叠。
-
第三块是去重,因为上一步选择过程大概率是有重复,所以这一步在之前的集合中,从评分最低的序列开始剔除,直到序列不连续为止。这样就获得了变长的patch切分集合。
-
由于每个patch的长度不相等,这样的数据实际是无法并行训练的。所以作者使用self-attention获得不同切片的向量表示,这一步使切片长度得到统一。
AAAI 2025-FEI:Frequency-Masked Embedding Inference: A Non-Contrastive Approach for Time Series Representation Learning
PAPER:https://arxiv.org/pdf/2412.20790
CODE: — https://github.com/USTBInnovationPark/Frequencymasked-Embedding-Inference
Highlights: 一种新颖的非对比学习方法,旨在解决时间序列表示学习中的挑战。传统的对比学习方法依赖于构建正负样本对,但由于时间序列数据的连续性,这种方法在构建困难负样本和引入不适当偏差时存在问题,而FEI无需显示构造负样本,产出的表征应用到下游分类、回归等任务都取得了比较好的效果。

FEI 通过引入频率掩码作为提示,构建两个推理分支:
-
使用频率掩码推断目标序列在嵌入空间中缺失频带的嵌入表示。
-
使用目标序列推断其频率掩码嵌入。
这种方法消除了对正负样本的需求,能够连续地建模时间序列的语义关系
时频一致性:NeurIPS 2022-Self-supervised contrastive pre-training for time series via time-frequency Consistency
分别在时域和频域上进行样本增强,通过多个样本增强的结果计算各自的表征向量,并分别学习时域、频域、及二者结合的loss。

AAAI25-Droppatch:Enhancing Masked Time-Series Modeling via Dropping Patches

先patch化&位置编码 —> 随机drop patch —> 随机mask —> 得到对掩码序列的重建结果
待看列表:
- https://thibaut-germain.github.io/files/papers/shape_analysis_for_time_series.pdf https://nips.cc/media/neurips-2024/Slides/95718.pdf
CTR
KDD'23——MAP: A Model-agnostic Pretraining Framework for Click-through Rate
paper地址:https://arxiv.org/pdf/2308.01737
highlights:一种与模型无关的预训练MAP框架,利用特征损坏和恢复来进行自监督学习。属于前置任务预训练ctr模型,然后用预测目标微调。该框架主要包含两种算法:
-
掩码特征预测(MFP):通过mask和预测一小部分的输入特征来研究每个实例中特征的交互,并引入噪声对比估计(NCE)来处理大型特征空间
-
替换特征检测(RFD):通过替换和检测输入特征的变化,进一步将MFP转变为二分类任务。

时序-自编码器
TimeMAE:解耦掩码自编码器时间序列的自监督表示
论文题目:TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders 论文地址:https://arxiv.org/abs/2303.00320 代码地址:https://github.com/Mingyue-Cheng/TimeMAE
highlights:
-
提出了一个概念简单但非常有效的时间序列表示自监督范式,该范式将基本语义元素从点粒度提升到局部子序列粒度,并同时促进从单向到双向的上下文信息提取。
-
提出了一个端到端解耦的时间序列表示自编码器架构,其中(1)我们解耦了屏蔽和可见输入的学习,以消除屏蔽策略引起的差异问题;(2)基于可见输入,形式化了分类(MCC)和回归(MRR)任务。

归一化
2023 NIPS-SAN:非平稳时间序列预测的自适应归一化:时间片的视角
title:Adaptive Normalization for Non-stationary Time Series Forecasting: A Temporal Slice Perspective 文章链接:https://proceedings.neurips.cc/paper_files/paper/2023/hash/2e19dab94882bc95ed094c4399cfda02-Abstract-Conference.html 开源代码:https://github.com/icantnamemyself/SAN
highlight: 一种SAN的两阶段训练范式,通过简化较低级别的优化目标,在统计预测第一阶段将原来的非平稳预测任务解耦为统计预测任务和平稳预测任务,在训练预测模型的第二阶段将其冻结并作为插件处理。使其能够专注于估计未来的分布,而不是减少某个模型的非规范化输出与基本事实之间的分布差异。
2023 AAAI)Dish-TS: A General Paradigm for Alleviating Distribution Shift in Time Series Forecasting
paper:https://arxiv.org/pdf/2302.14829
code: https://github.com/weifantt/Dish-TS.
highlights:提出了一种新颖的时序归一化方法,通过过去历史窗口数据的归一化系数来预测未来窗口的归一化系数,来解决由于时间序列不平稳带来的分布漂移(Distribution Shift)问题。

2025 ICLR-FredNormer: 非平稳时间序列预测的频域正则化方法
title: FredNormer: Frequency Domain Normalization for Non-stationary Time Series Forecasting
Paper: https://arxiv.org/pdf/2410.01860
Code:暂未公开
highlights:提出了一种新的频率稳定性测量方法,定义为频谱中的各频率成分的统计稳定性。旨在通过频域建模来解决时间序列预测中的分布偏移问题,引入了频率稳定性加权层,通过可训练的线性投影自适应地调整频谱中的关键频率分量,增强模型的泛化能力



 浙公网安备 33010602011771号
浙公网安备 33010602011771号