推荐系统——预训练论文解读
AAAI-2022 ——《TS2Vec: Towards Universal Representation of Time Series》
paper地址:https://arxiv.org/pdf/2308.01737
highlights:一种与模型无关的时序表征学习的预训练框架,利用对比学习范式的encoder框架来进行自监督学习。属于前置任务预训练,下游接预测任务。该框架主要包含:
-
数据构造:构造两段长度相等的随机序列:对于每个实例 xi,随机抽取两个重叠的时间片段 [a1, b1]、[a2, b2],使得 0 < a1 ≤ a2 ≤ b1 ≤ b2 ≤ T。
-
encoder设计:编码器由三个组件组成,一个输入投影层(input projection layer)、时间戳Mask模块(timestamp masking )和一个空洞卷积层(dilated CNN)
-
对比损失:从两个维度刻画,一是时间层面的对比,二是实例维度的对比
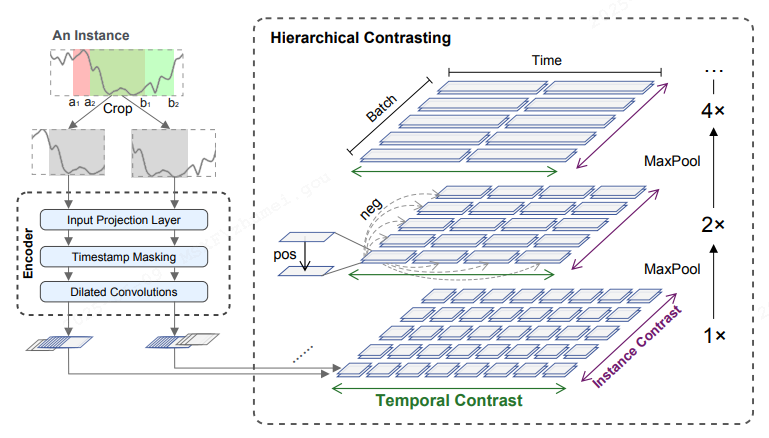
Temporal Contrastive Loss (时间对比损失)
用于计算同一实例在不同时间点的对比损失,强化时间上的表征差异。令 i 为输入时间序列样本的索引, t 为时间戳。 计算相同时间戳 t 下,正样本对为样本 xi 的两个增强的context表示。时间对比损失旨在挖掘动态随时间变化的趋势:
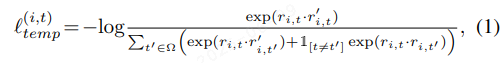
Instance-wise Contrastive Loss (实例对比损失)
计算同一时间点不同实例间的对比损失,确保相似的表示被拉近,不同的表示被推远。可以学习到用户特定的特征:

KDD'23——MAP: A Model-agnostic Pretraining Framework for Click-through Rate
paper地址:https://arxiv.org/pdf/2308.01737
highlights:一种与模型无关的预训练MAP框架,利用特征损坏和恢复来进行自监督学习。属于前置任务预训练ctr模型,然后用预测目标微调。该框架主要包含两种算法:
-
掩码特征预测(MFP):通过mask和预测一小部分的输入特征来研究每个实例中特征的交互,并引入噪声对比估计(NCE)来处理大型特征空间
-
替换特征检测(RFD):通过替换和检测输入特征的变化,进一步将MFP转变为二分类任务。

MFP
-
对于F个特征的样本,用随机替换部分特征,得到损坏的样本。要mask的特征比例是由超参数γ控制。
-
传入emb层,所有field用的的emb是一样的。
-
经过特征交互层之后,得到表征。对于第f个field的每个mask特征,构造一个独立的MLP,然后用softmax函数来计算候选特征上的预测概率。
-
每个masked field的预测空间(即候选特征)都被扩展到全局特征空间,以增加前置预训练任务的难度,模型必须从整个特征空间中选择原始特征,然后将MFP预训练视为一个多类分类问题,并利用多类交叉熵损失进行优化
-
采用噪声对比估计(NCE)来降低softmax开销
RFD
-
检测所有field中哪些字段是被更改了
-
随机破环部分字段形成mask特征
-
类似MFP中的emb和交互层,预测是否被替换过
AAAI 2024 ——TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning
paper地址:https://arxiv.org/pdf/2312.15709
code:https://github.com/Alrash/TimesURL
highlights:和TS2Vec类似,针对用于时间序列表示的对比学习提出了TimesURL,用于捕捉时段级和实例级信息,通过额外的时间重构模块实现通用表示。(在TS2Vec的基础上做了以下三点升级)
-
样本增强:引入了一种基于频域-时间的混合增强方法。
-
在对比学习中注入了新的双重 Universums(一种通过 混合正负样本特征 生成的 难负样本),以解决正负对构建问题,增强对比学习效果。
-
通过随机mask引入了一种时间重构模块(和MAP类似)。

FTAug 方法
优势在于保持了上下文一致性策略,该策略将两个增强上下文中同一时间戳的表征视为正对
-
混频:通过快速傅立叶变换计算出xi 中的频率成分的一定比率替换为同一批次中另一个随机训练实例 xk 的相同频率成分,从而生成新的上下文视图。然后使用反向 FFT 转换,得到一个新的时域时间序列。在样本之间交换频率成分不会引入意外噪声或人为周期性,可以提供更可靠的增强功能,以保留数据的语义特征。
-
随机裁剪:对于每个实例 xi,随机抽取两个重叠的时间片段 [a1, b1]、[a2, b2],使得 0 < a1 ≤ a2 ≤ b1 ≤ b2 ≤ T。

双重Universums学习
硬负样本(硬负样本是模型难以正确分类的负样本,通常与正样本在特征空间中非常接近,训练过程中特别关注这些样本,可以使模型更好地泛化到新数据)在对比学习中发挥着重要作用,由于时间序列的局部平滑性和马尔可夫特性,大多数负样本都是易负样本(易负样本是模型可以轻易正确分类的负样本,与正样本在特征空间中有着明显的区别),不足以捕捉时间信息,因为它们从根本上缺乏驱动对比学习所需的学习信号。这些易负样本片段往往与锚点(锚点是用作参考点,与正负样本一起使用,来训练模型学习区分不同类别或实体,比如一个场景:模型的目标是将锚点与正样本之间的距离最小化,同时将锚点与负样本之间的距离最大化,从而学会区分不同的对象或类别)表现出语义上的不相似性,而且只贡献了很小的梯度。
提出的双重Universums在实例和时间上都是混合诱导Universums,它是嵌入空间中特定于锚的混合,将特定的正向特征(锚)与未标注数据集的负向特征混合在一起:



对比损失

最后采用了多尺度信息学习,方法是对公式(3)和(4)中沿时间轴学习到的表征进行最大池化处理。作者指出重要的时间变化信息,如趋势和季节性信息,会在多次最大池化操作后丢失,因此高层对比实际上无法为下游任务捕捉到足够的实例级信息。

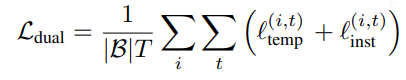
实例级信息的时间重构
根据部分观察结果重建原始信号的思想。设计了一种重构模块,以保留重要的时变信息。使用随机掩码策略,计算每个时间戳上重建值与原始值之间的均方误差(MSE)。


最终的联合loss:

(代码里面,这里的Ldual权重只有0.01,而mse的权重为1,难道Ldual的重要度很低?)
实验:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号