
第一次作业——结合三次小作业
作业1
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息
代码:
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
print("排名\t学校名称\t省市\t类型\t总分")
for tr in soup.find('tbody').children:
r = tr.find_all("td")
for i in range(5):
print(r[i].text.strip(), end="\t")
print()
结果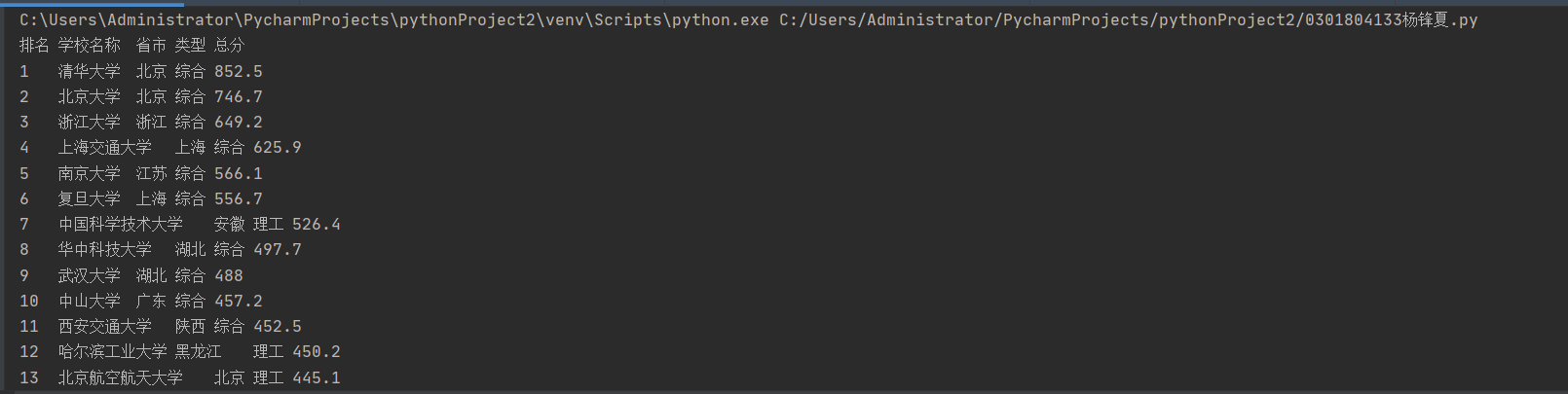
并不是第一次接触爬虫,之前有跟朋友做过一个爬4k图片的,所以并不是很难
作业2
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“笔记本电脑”搜索页面的数据,爬取商品名称和价格。
代码:
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (XHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
})
if response.status_code == 200:
return response.text
else:
return ""
def main():
keyword = '笔记本电脑'
url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
soup = BeautifulSoup(getHTMLText(url), 'lxml')
goods = soup.find_all('li', class_='gl-item')
plot = "{:4}\t{:8}\t{:16}"
print(plot.format("序号", "价格", "商品信息"))
count = 0
for good in goods:
count += 1
print(count, good.find('div', {'class': 'p-price'}).strong.i.get_text(), good.find("div", {"class": "p-name p-name-type-2"}).find('em').get_text().replace("\n", "").replace("\t", ""))
main()
结果: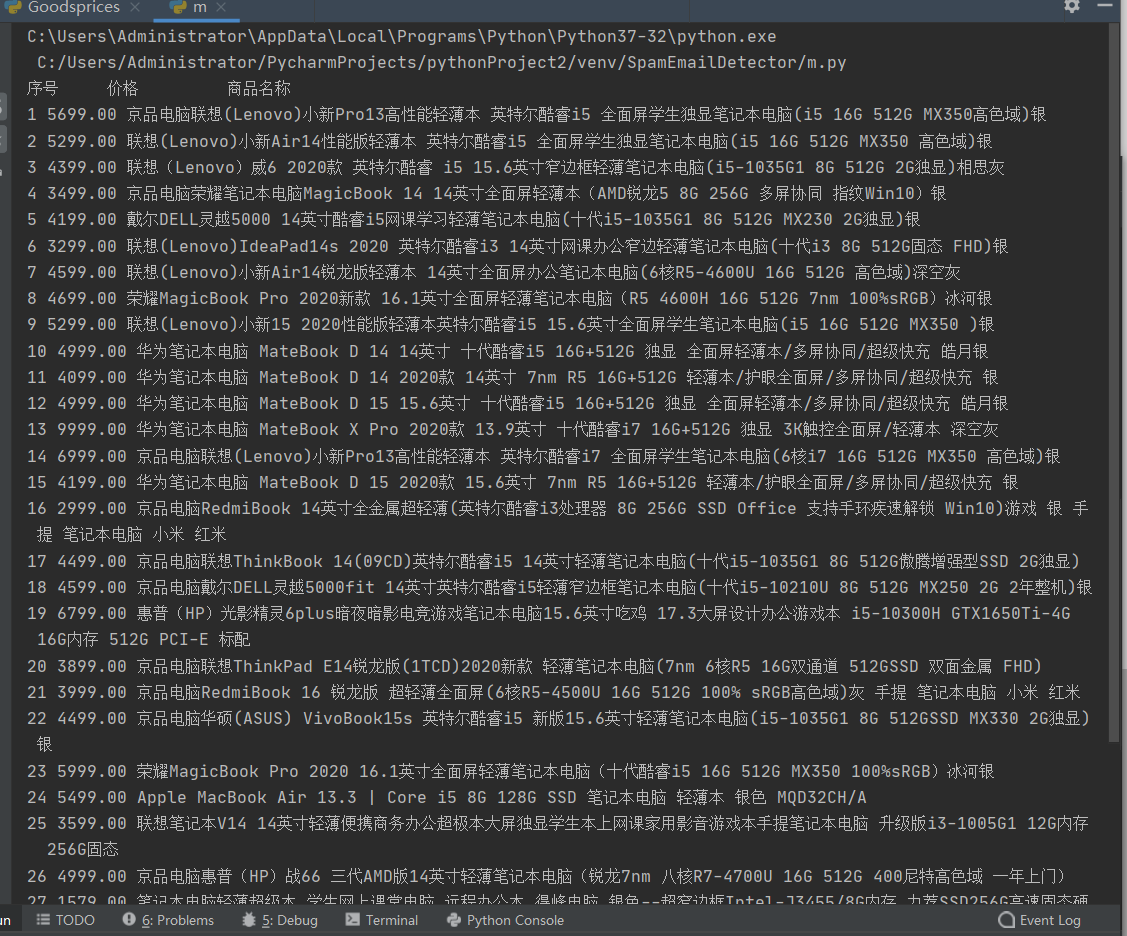
原本想爬取淘宝的,但那个淘宝的搜索接口和翻页处理就有点摸不着头脑,加上反扒处理,一会爬取成功,一会爬取失败的,所以选了京东作为爬取的对象
作业3
爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
代码:
import urllib.request
from bs4 import BeautifulSoup
import re
path = 'E:/Desktop/爬虫/imgs/'
url = "http://www.fzu.edu.cn/"
soup = BeautifulSoup(urllib.request.urlopen(url).read().decode(), "html.parser")
reg = "([\w./]+\.(jpg|JPG))"
jpg = soup.find_all("img", {"src": re.compile(reg)})
for r in jpg:
name = r.attrs["src"].replace("/", "_")
try:
urllib.request.urlretrieve(url+r.attrs["src"], path + name)
except:
print("爬取失败")
结果: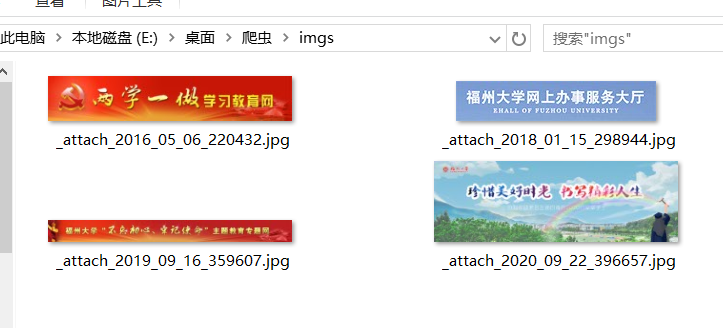

 浙公网安备 33010602011771号
浙公网安备 33010602011771号