RL | | EfficientZero
原文
Mastering Atari Games with Limited Data
创新点
针对RL采样效率不足的问题,提出model-based的EfficientZero,该算法在Atari game上性能远超其他算法。
文章脉络
背景
DQN, AlphaGo和OpenAI Five等算法效果显著,但是需要大量的样本数据,同时带来很低的采样效率;
此外,在将图像当作输入的环境中,先前的算法要么采样不足,要么性能不足。
本文贡献
针对背景问题,在model-based的基础上提出三点改进:
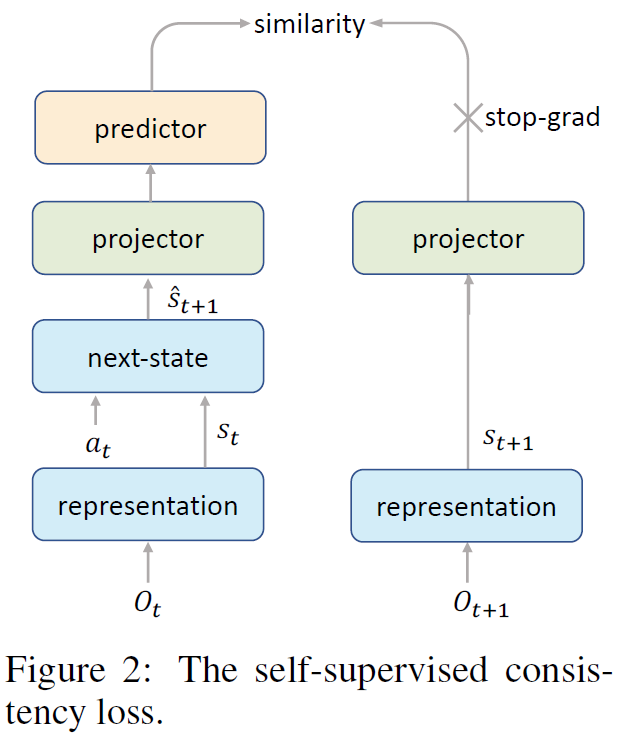
自我监督 --- 用来学习时间一致性环境模型(temporally consistent environment model)
当reward非常稀疏或者the bootstrapped value不精确时,模型便不能很好的建立,所以需要找其他方法。注意到从动态方程\(\mathcal{G}\)拿出来的\(\hat s_{t+1}\)和\(s_{t+1}\)很像,那么在监视\(\hat s_{t+1}\)时用\(s_{t+1}\)会比利用reward和value更加合适
然后作者想到了SimSiam,将它改进后构建了自我监督的网络去学习状态转移概率,主要是如图二所示,相较于SimSiam来说,变更在于利用了相邻状态做一个相似的比较。
value prefix --- 处理模型复合误差(the model compounding error)
在model-based方法中,看的长远会导致出现状态混叠(the state aliasing problem)问题,导致了MCTS(蒙托卡罗树搜索)会出现次优化的情况。
作者针对这种混叠状态做了一个直觉上的说明:人类或者一个优秀的智能体是不会关心且知道到底游戏在哪个精确的时间步结束,而是会对得分与否非常敏感,那么由此,一个人会用发展且长远的眼光看待问题然后做出预测。
返回到本文中,作者发现MCTS的UCT当中的Q值由如下形式得到
,那么定义其中的\(\sum _ { i = 0 } ^ { k - 1 } \gamma ^ { i } r _ { t + i }\)为value prefix,该值由\(f(s_t , \hat s_{t + 1} , \cdots , \hat s_{t + k - 1 })\)得出,\(f\)是LSTM网络。
学习模型 --- 纠正off-policy带来的误差
off-policy存在的问题:旧的策略和新的轨迹不匹配,导致value误差越来越大。
作者提出在MCTS中,将off-policy的回看步长(\(k\))设置的小一些(\(l\)),\(l<k\)
效果
比DQN又快又好,吊打?
作者回顾
三部分分别的作用
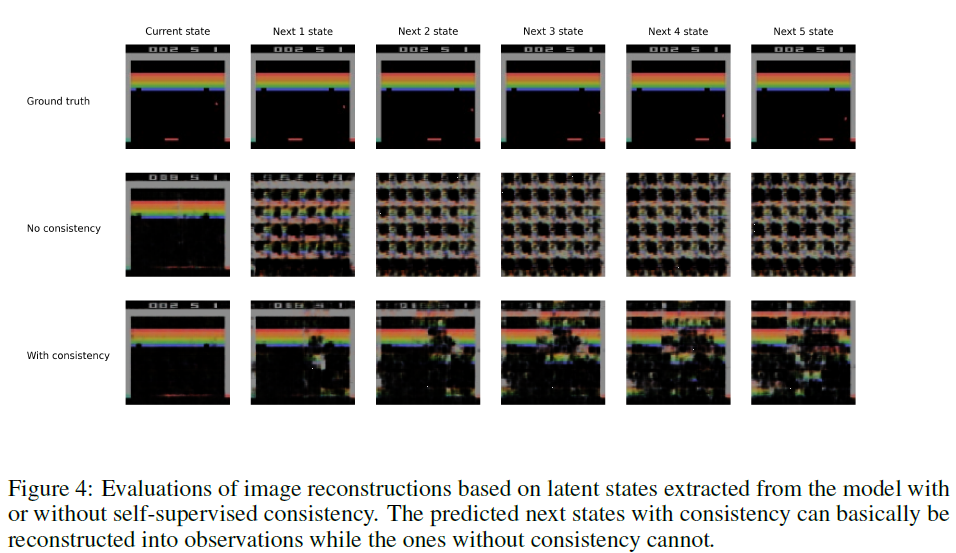
改进一(Temporal Consistency)很有效
如下图,将每层网络输出解码后观察,该改进预测的状态比先前好很多
改进二只在早期有效
改进三在少量数据下效果不明显
回顾
利用上述三点大大提高了在Atari上的效果,目前等待开源
PS:由于基础知识实在是太弱了,所以只能给出一个大概的阐述,很多理解或者描述有偏差或者错误的地方恳请大家指出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号