案例:使用正则表达式中的正向预查和反向预查
需求如下:
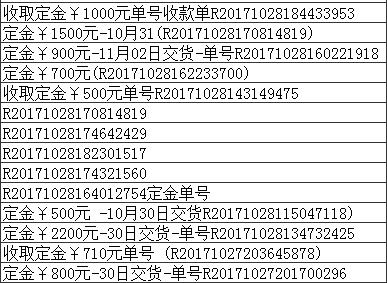
从Excel表格里复制下来的数千行下列字符串如上,需要保存下“R20171028153620837”的字符,其余删除。
最快捷的方法就将这一列值复制到notepad++中,使用正则表达式“R\d{17}”匹配到这一字符,怎么样能得到匹配之外的结果而进行replace替换为空呢,那这样就大工告成了。
然后就用到了正向预查:在子模式的内部前面添加"?=" 正向预查的意思是,子模式仅仅作为条件限制,并不作为匹配结果输出,子模式前面的。
例如:
收取定金¥1000元单号收款单R20171028184433953
匹配“R20171028184433953”前面的数字字母和汉字就用到了正向预查 .*(?=R\d{17})
然后将“R20171028184433953”匹配到的结果进行替换,替换为字符串为空。
接下来该处理“R20171028184433953”后边有字符串字母和数字的了,用到了反向预查。
反向预查:在子模式的内部前面添加"?<="。反向预查与正向预查很相似,子模式仅仅作为条件限制,不作为结果输出。唯一不同的是,正向预查匹配子模式前面的结果作为匹配结果,而反向预查匹配子模式后面的结果作为匹配结果。
R20171028164012754定金单号
匹配“R20171028164012754”前面的汉字就用到了反向预查 (?<=R\d{17}).*
使用上述正则就能匹配到“R20171028164012754”后边相关的字符替换为空,即可。
总结:若想替换掉正则匹配结果的前面和后边的字符为空,可分为将此字符串结合中间字符的正则进行正向预查和反向预查,查到前后字符进行替换为空即为索要的结果。
最后 我想说 正则表达式是强大的,你能通过它得到如何你想要的东西,且轻量化了工作内容,何乐而不为~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号