
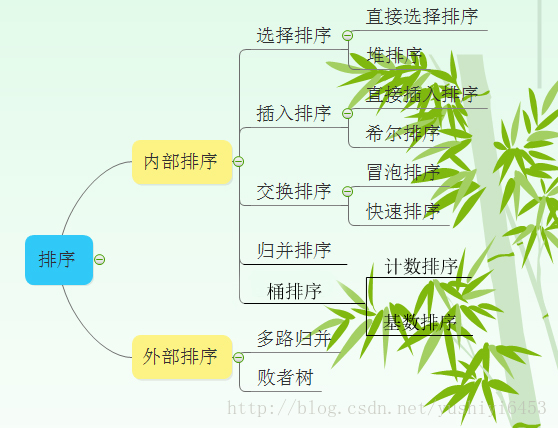
排序算法比较表格填空
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|
| 冒泡排序 | :————-: | :—–: | :—–: | :—–: |
| 选择排序 | :————-: | :—–: | :—–: | :—–: |
| 直接插入排序 | :————-: | :—–: | :—–: | :—–: |
| 归并排序 | :————-: | :—–: | :—–: | :—–: |
| 快速排序 | :————-: | :—–: | :—–: | :—–: |
| 堆排序 | :————-: | :—–: | :—–: | :—–: |
| 希尔排序 | :————-: | :—–: | :—–: | :—–: |
| 计数排序 | :————-: | :—–: | :—–: | :—–: |
| 基数排序 | :————-: | :—–: | :—–: | :—–: |
排序算法比较表格
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|
| 冒泡排序 | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 是 |
| 选择排序 | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 不是 |
| 直接插入排序 | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 是 |
| 归并排序 | O(nlogn)O(nlogn) | O(nlogn)O(nlogn) | O(n)O(n) | 是 |
| 快速排序 | O(nlogn)O(nlogn) | O(n2)O(n2) | O(logn)O(logn) | 不是 |
| 堆排序 | O(nlogn)O(nlogn) | O(nlogn)O(nlogn) | O(1)O(1) | 不是 |
| 希尔排序 | O(nlogn)O(nlogn) | O(ns)O(ns) | O(1)O(1) | 不是 |
| 计数排序 | O(n+k)O(n+k) | O(n+k)O(n+k) | O(n+k)O(n+k) | 是 |
| 基数排序 | O(N∗M)O(N∗M) | O(N∗M)O(N∗M) | O(M)O(M) | 是 |
注:
1 归并排序可以通过手摇算法将空间复杂度降到O(1),但是时间复杂度会提高。
2 基数排序时间复杂度为O(N*M),其中N为数据个数,M为数据位数。
辅助记忆
- 时间复杂度记忆-
- 冒泡、选择、直接 排序需要两个for循环,每次只关注一个元素,平均时间复杂度为O(n2)O(n2)(一遍找元素O(n)O(n),一遍找位置O(n)O(n))
- 快速、归并、希尔、堆基于二分思想,log以2为底,平均时间复杂度为O(nlogn)O(nlogn)(一遍找元素O(n)O(n),一遍找位置O(logn)O(logn))
- 稳定性记忆-“快希选堆”(快牺牲稳定性)
- 排序算法的稳定性:排序前后相同元素的相对位置不变,则称排序算法是稳定的;否则排序算法是不稳定的。
原理理解
1 冒泡排序
1.1 过程
冒泡排序从小到大排序:一开始交换的区间为0~N-1,将第1个数和第2个数进行比较,前面大于后面,交换两个数,否则不交换。再比较第2个数和第三个数,前面大于后面,交换两个数否则不交换。依次进行,最大的数会放在数组最后的位置。然后将范围变为0~N-2,数组第二大的数会放在数组倒数第二的位置。依次进行整个交换过程,最后范围只剩一个数时数组即为有序。
1.2 动图
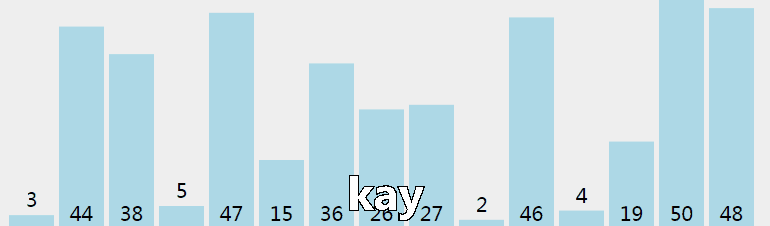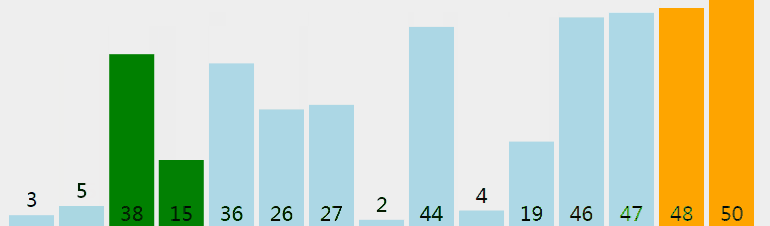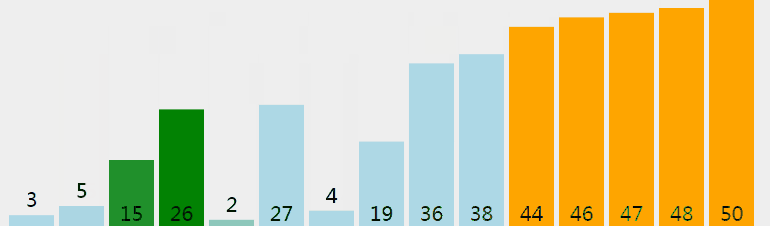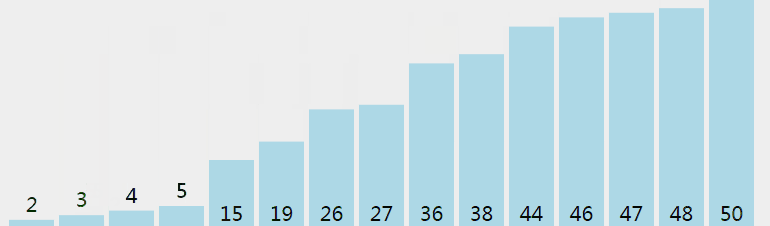
1.3 核心代码(函数)
//array[]为待排序数组,n为数组长度1 void BubbleSort(int array[], int n) 2 { 3 int i, j, k; 4 for(i=0; i<n-1; i++) 5 for(j=0; j<n-1-i; j++) 6 { 7 if(array[j]>array[j+1]) 8 { 9 k=array[j]; 10 array[j]=array[j+1]; 11 array[j+1]=k; 12 } 13 } 14 }
2 选择排序
2.1 过程
选择排序从小到大排序:一开始从0~n-1区间上选择一个最小值,将其放在位置0上,然后在1~n-1范围上选取最小值放在位置1上。重复过程直到剩下最后一个元素,数组即为有序。
2.2 动图

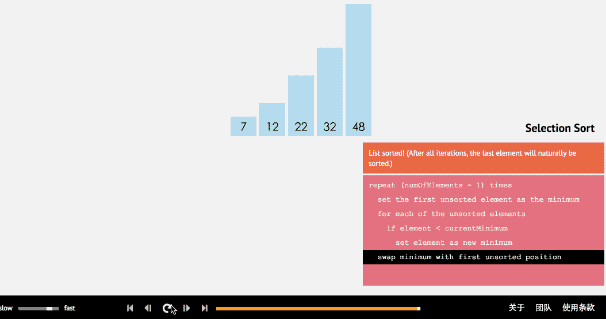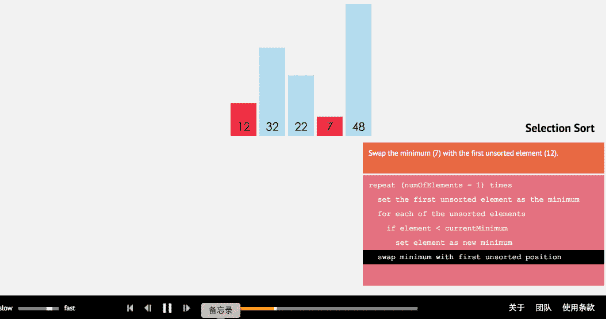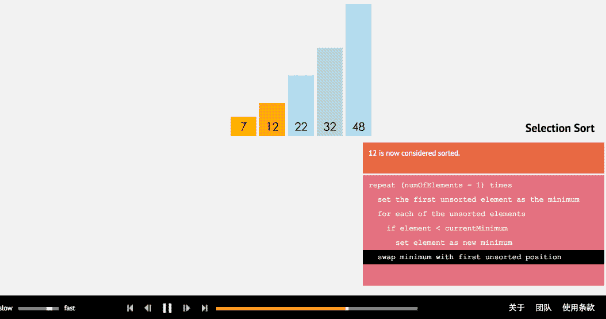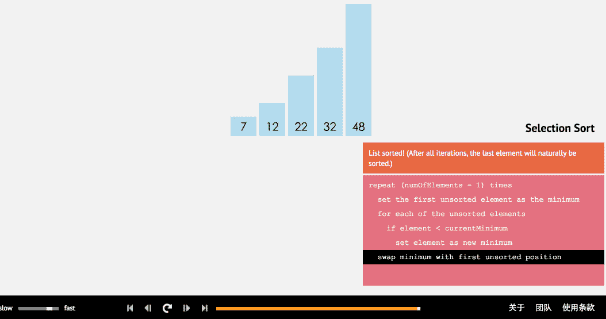
2.3 核心代码(函数)
//array[]为待排序数组,n为数组长度
1 void selectSort(int array[], int n) 2 { 3 int i, j ,min ,k; 4 for( i=0; i<n-1; i++) 5 { 6 min=i; //每趟排序最小值先等于第一个数,遍历剩下的数 7 for( j=i+1; j<n; j++) //从i下一个数开始检查 8 { 9 if(array[min]>array[j]) 10 { 11 min=j; 12 } 13 } 14 if(min!=i) 15 { 16 k=array[min]; 17 array[min]=array[i]; 18 array[i]=k; 19 } 20 } 21 }
3 插入排序
3.1 过程
插入排序从小到大排序:首先位置1上的数和位置0上的数进行比较,如果位置1上的数大于位置0上的数,将位置0上的数向后移一位,将1插入到0位置,否则不处理。位置k上的数和之前的数依次进行比较,如果位置K上的数更大,将之前的数向后移位,最后将位置k上的数插入不满足条件点,反之不处理。
3.2 动图
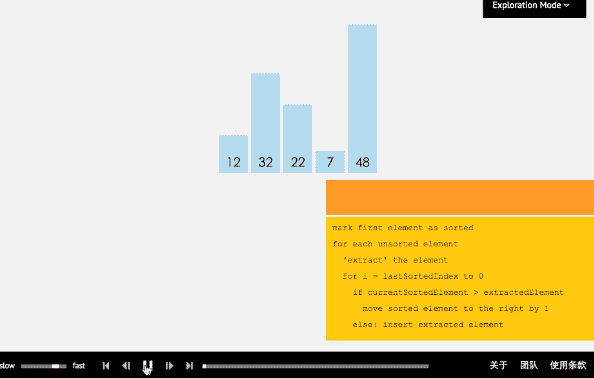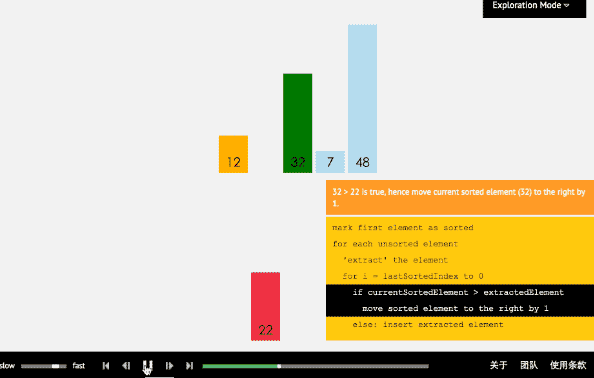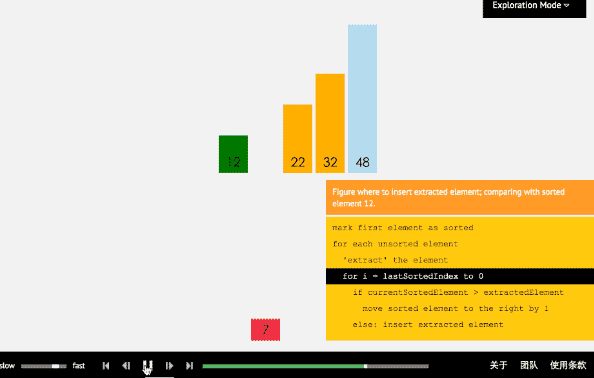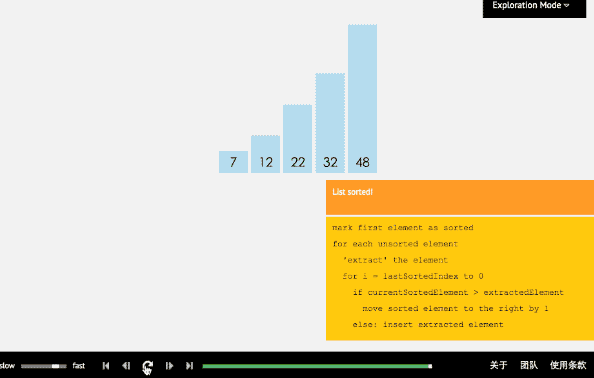
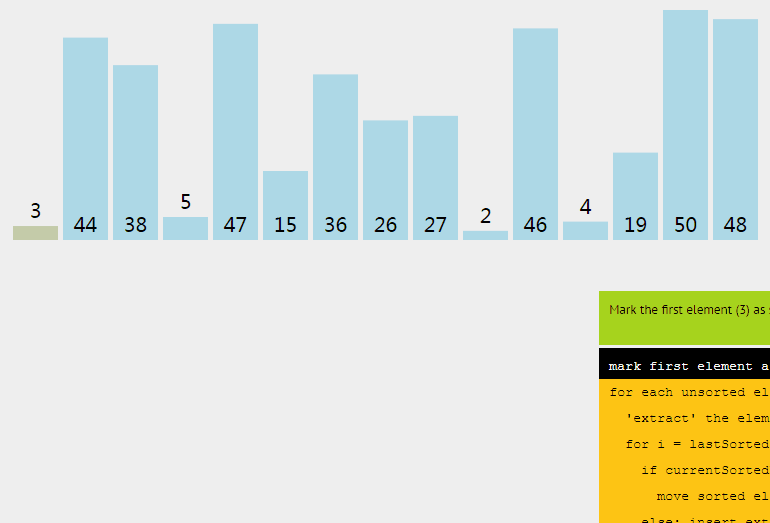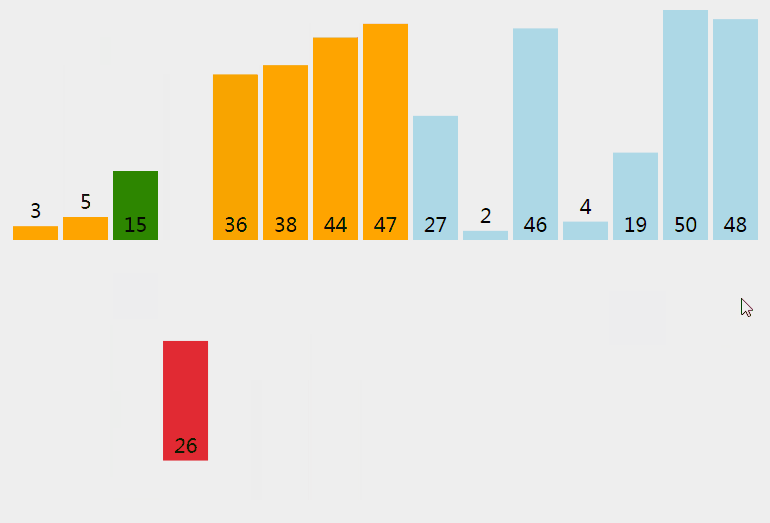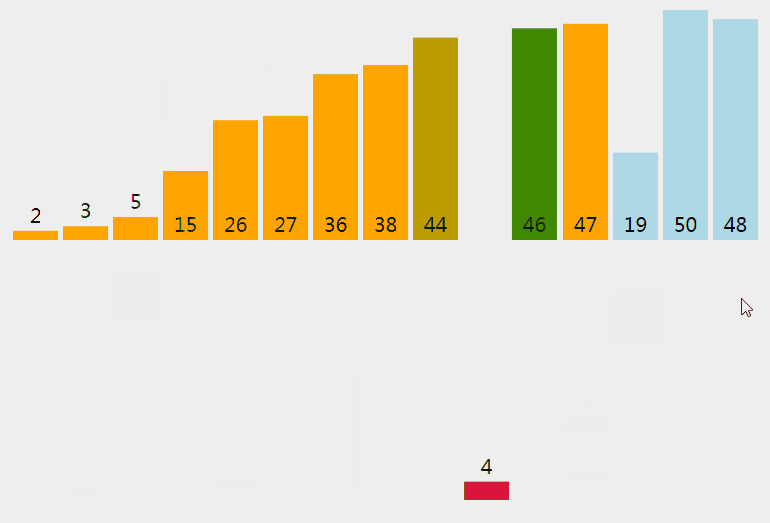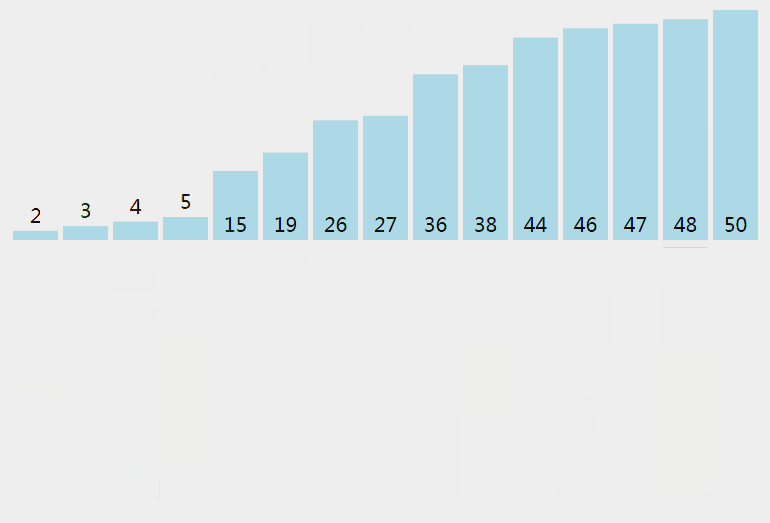
3.3 核心代码(函数)
//array[]为待排序数组,n为数组长度1 void insertSort(int array[], int n) 2 { 3 int i,j,temp; 4 for( i=1;i<n;i++) 5 { 6 if(array[i]<array[i-1]) 7 { 8 temp=array[i]; 9 for( j=i;array[j-1]>temp;j--) 10 { 11 array[j]=array[j-1]; 12 } 13 array[j]=temp; 14 } 15 } 16 }
4 归并排序
4.1 过程
归并排序从小到大排序:首先让数组中的每一个数单独成为长度为1的区间,然后两两一组有序合并,得到长度为2的有序区间,依次进行,直到合成整个区间。
4.2 动图

4.3 核心代码(函数)
- 递归实现
////实现归并,并把数据都放在list1里面1 void merging(int *list1, int list1_size, int *list2, int list2_size) 2 { 3 int i=0, j=0, k=0, m=0; 4 int temp[MAXSIZE]; 5 6 while(i < list1_size && j < list2_size) 7 { 8 if(list1[i]<list2[j]) 9 { 10 temp[k++] = list1[i++]; 11 } 12 else 13 { 14 temp[k++] = list2[j++]; 15 } 16 } 17 while(i<list1_size) 18 { 19 temp[k++] = list1[i++]; 20 } 21 while(j<list2_size) 22 { 23 temp[k++] = list2[j++]; 24 } 25 26 for(m=0; m < (list1_size+list2_size); m++) 27 { 28 list1[m]=temp[m]; 29 } 30 }
//如果有剩下的,那么说明就是它是比前面的数组都大的,直接加入就可以了void mergeSort(int array[], int n) { if(n>1) { int *list1 = array; int list1_size = n/2; int *list2 = array + n/2; int list2_size = n-list1_size; mergeSort(list1, list1_size); mergeSort(list2, list2_size); merging(list1, list1_size, list2, list2_size); } }
//归并排序复杂度分析:一趟归并需要将待排序列中的所有记录
//扫描一遍,因此耗费时间为O(n),而由完全二叉树的深度可知,
//整个归并排序需要进行[log2n],因此,总的时间复杂度为
//O(nlogn),而且这是归并排序算法中平均的时间性能
//空间复杂度:由于归并过程中需要与原始记录序列同样数量级的
//存储空间去存放归并结果及递归深度为log2N的栈空间,因此空间
//复杂度为O(n+logN)
//也就是说,归并排序是一种比较占内存,但却效率高且稳定的算法
- 迭代实现
1 void MergeSort(int k[],int n) 2 { 3 int i,next,left_min,left_max,right_min,right_max; 4 //动态申请一个与原来数组一样大小的空间用来存储 5 int *temp = (int *)malloc(n * sizeof(int)); 6 //逐级上升,第一次比较2个,第二次比较4个,第三次比较8个。。。 7 for(i=1; i<n; i*=2) 8 { 9 //每次都从0开始,数组的头元素开始 10 for(left_min=0; left_min<n-i; left_min = right_max) 11 { 12 right_min = left_max = left_min + i; 13 right_max = left_max + i; 14 //右边的下标最大值只能为n 15 if(right_max>n) 16 { 17 right_max = n; 18 } 19 //next是用来标志temp数组下标的,由于每次数据都有返回到K, 20 //故每次开始得重新置零 21 next = 0; 22 //如果左边的数据还没达到分割线且右边的数组没到达分割线,开始循环 23 while(left_min<left_max&&right_min<right_max) 24 { 25 if(k[left_min] < k[right_min]) 26 { 27 temp[next++] = k[left_min++]; 28 } 29 else 30 { 31 temp[next++] = k[right_min++]; 32 } 33 } 34 //上面循环结束的条件有两个,如果是左边的游标尚未到达,那么需要把 35 //数组接回去,可能会有疑问,那如果右边的没到达呢,其实模拟一下就可以 36 //知道,如果右边没到达,那么说明右边的数据比较大,这时也就不用移动位置了 37 38 while(left_min < left_max) 39 { 40 //如果left_min小于left_max,说明现在左边的数据比较大 41 //直接把它们接到数组的min之前就行 42 k[--right_min] = k[--left_max]; 43 } 44 while(next>0) 45 { 46 //把排好序的那部分数组返回该k 47 k[--right_min] = temp[--next]; 48 } 49 } 50 } 51 }
//非递归的方法,避免了递归时深度为log2N的栈空间,
//空间只是用到归并临时申请的跟原来数组一样大小的空间,并且在时间性能上也有一定的提升,
//因此,使用归并排序是,尽量考虑用非递归的方法。5 快速排序
5.1 过程
快速排序从小到大排序:在数组中随机选一个数(默认数组首个元素),数组中小于等于此数的放在左边,大于此数的放在右边,再对数组两边递归调用快速排序,重复这个过程。
5.2 动图

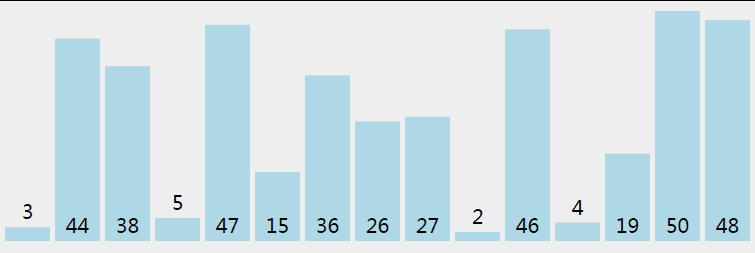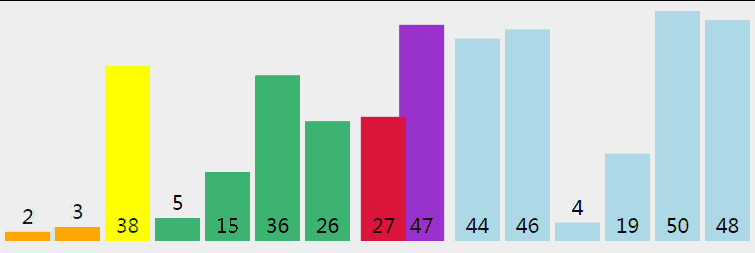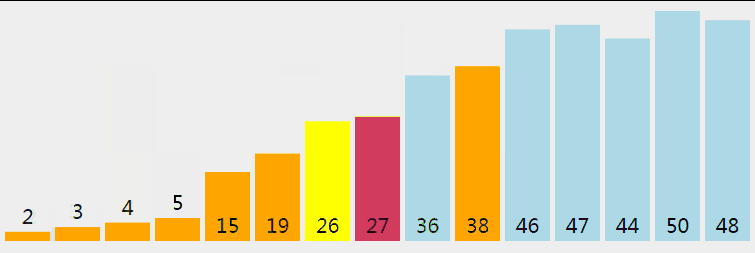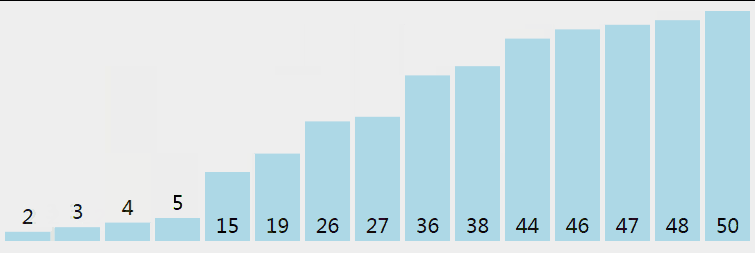
5.3 核心代码(函数)
推荐程序(好理解)
//接口调整1 void adjust_quicksort(int k[],int n) 2 { 3 quicksort(k,0,n-1); 4 } 5 void quicksort(int a[], int left, int right) 6 { 7 int i,j,t,temp; 8 if(left>right) //(递归过程先写结束条件) 9 return; 10 11 temp=a[left]; //temp中存的就是基准数 12 i=left; 13 j=right; 14 while(i!=j) 15 { 16 //顺序很重要,要先从右边开始找(最后交换基准时换过去的数要保证比基准小,因为基准 17 //选取数组第一个数,在小数堆中) 18 while(a[j]>=temp && i<j) 19 j--; 20 //再找右边的 21 while(a[i]<=temp && i<j) 22 i++; 23 //交换两个数在数组中的位置 24 if(i<j) 25 { 26 t=a[i]; 27 a[i]=a[j]; 28 a[j]=t; 29 } 30 } 31 //最终将基准数归位 (之前已经temp=a[left]过了,交换只需要再进行两步) 32 a[left]=a[i]; 33 a[i]=temp; 34 35 quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程 36 quicksort(i+1,right);//继续处理右边的 ,这里是一个递归的过程 37 }
6 堆排序
6.1 过程
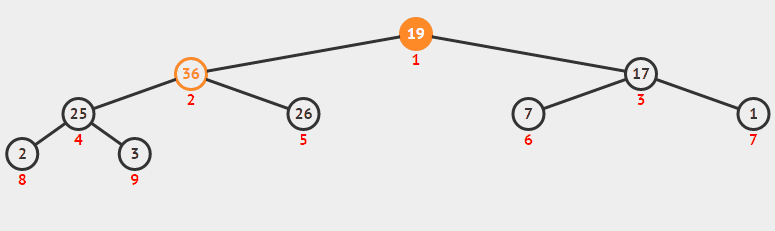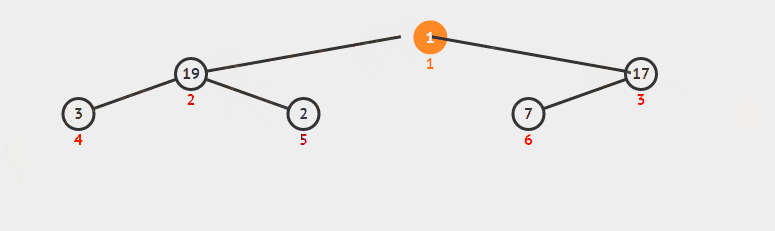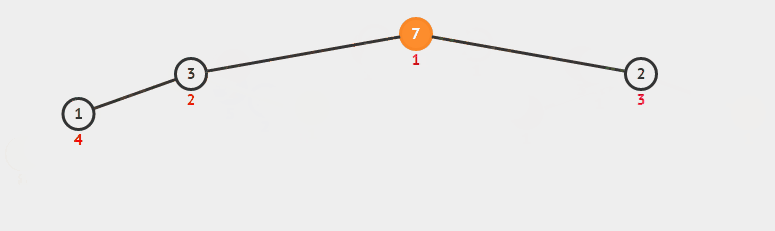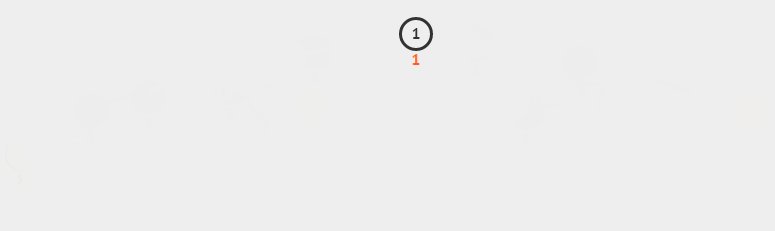
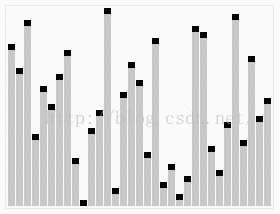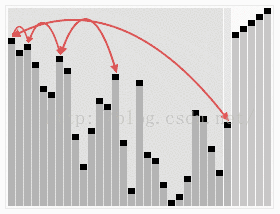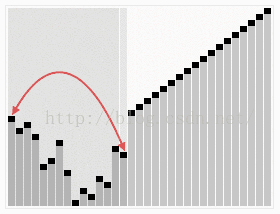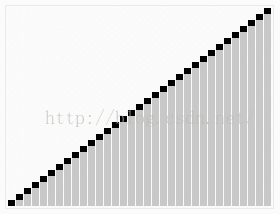
堆排序从小到大排序:首先将数组元素建成大小为n的大顶堆,堆顶(数组第一个元素)是所有元素中的最大值,将堆顶元素和数组最后一个元素进行交换,再将除了最后一个数的n-1个元素建立成大顶堆,再将最大元素和数组倒数第二个元素进行交换,重复直至堆大小减为1。
-
注:完全二叉树
假设二叉树深度为n,除了第n层外,n-1层节点都有两个孩子,第n层节点连续从左到右。如下图 -
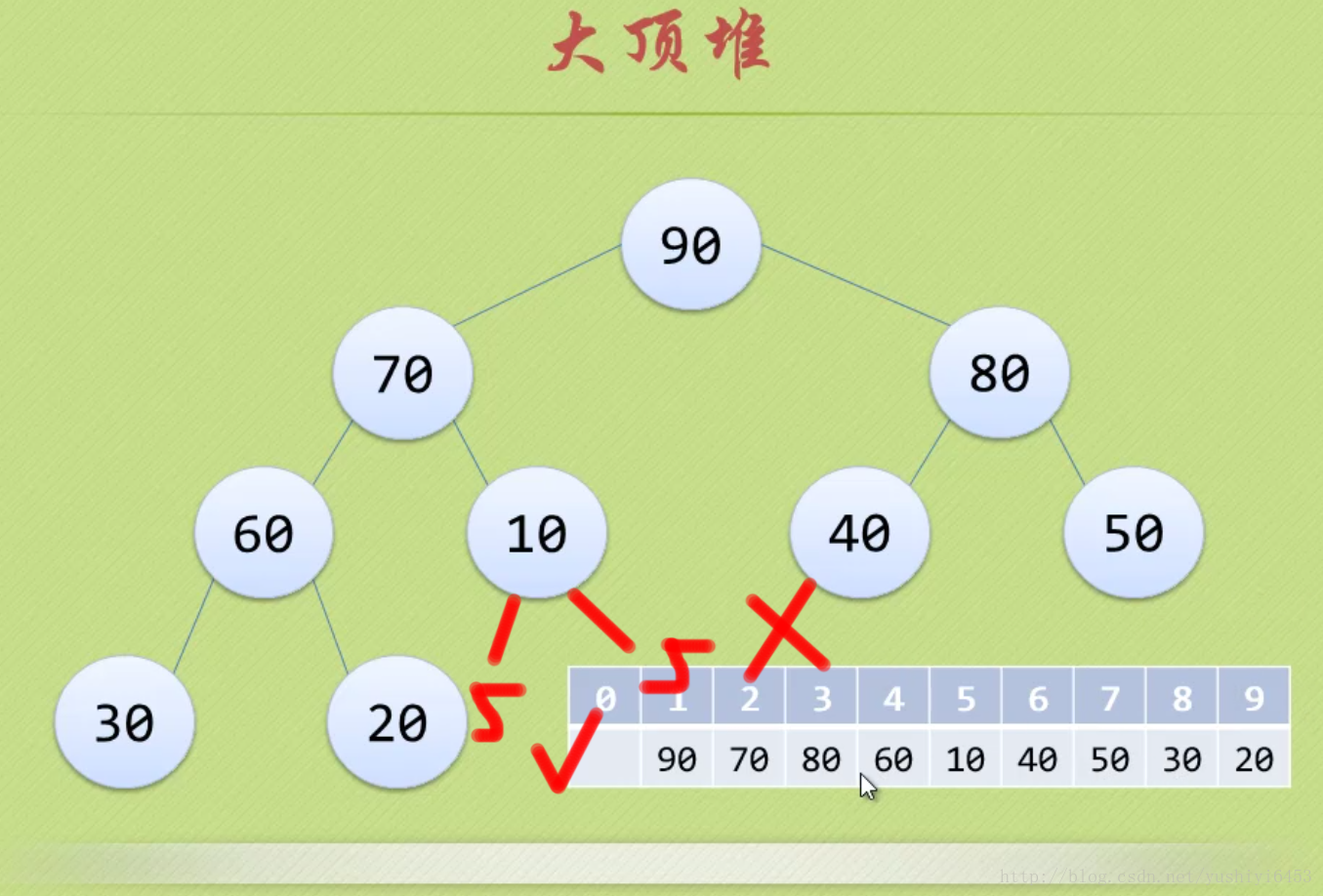
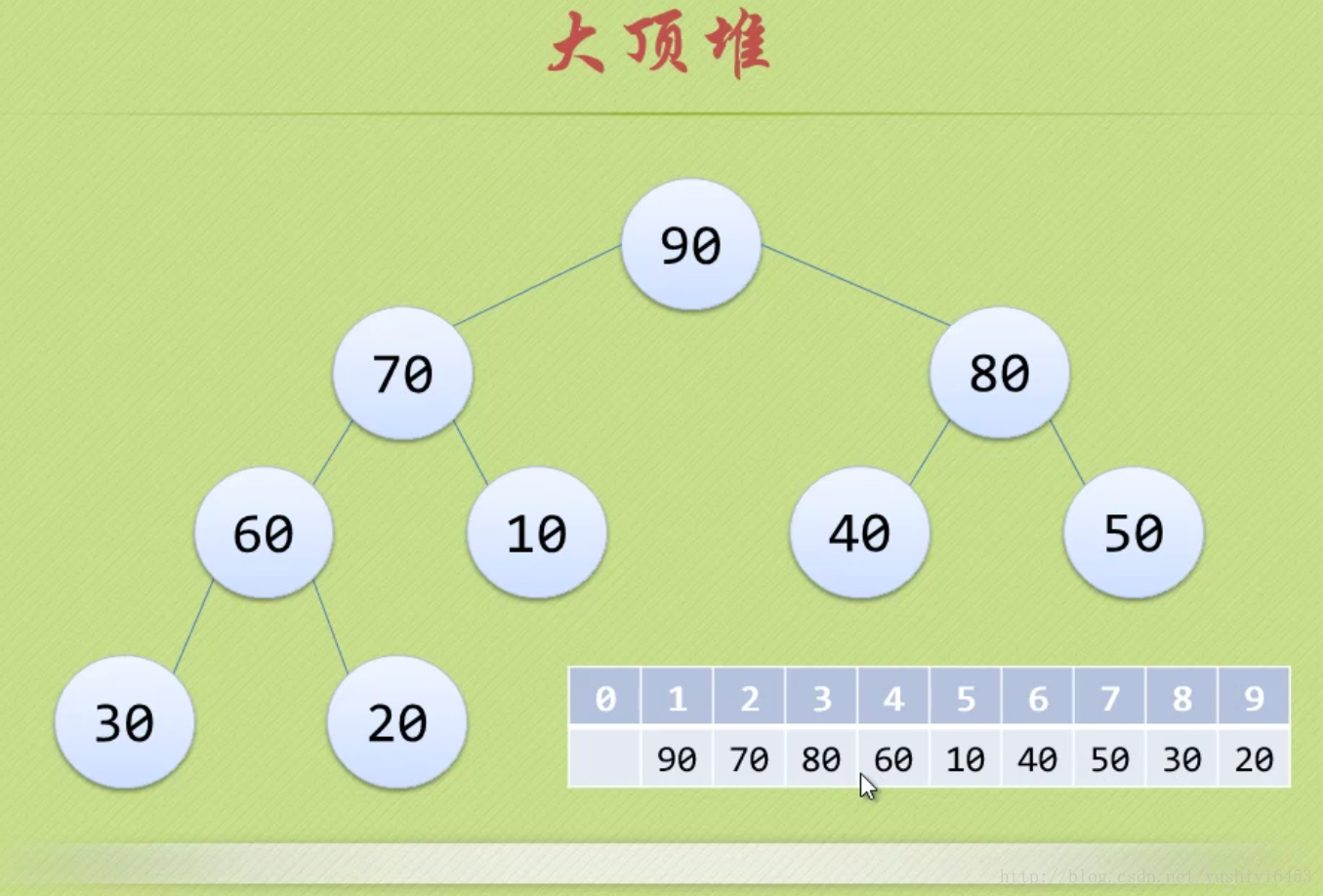
注:大顶堆
大顶堆是具有以下性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值。
即,根节点是堆中最大的值,按照层序遍历给节点从1开始编号,则节点之间满足如下关系:(1<=i<=n/2)
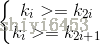 (1<=i<=n/2)
(1<=i<=n/2)6.2 动图

6.3 核心代码(函数)
注意!!!数组从1开始,1~n
1 void heapSort(int array[], int n) 2 { 3 int i; 4 for (i=n/2;i>0;i--) 5 { 6 HeapAdjust(array,i,n);//从下向上,从右向左调整 7 } 8 for( i=n;i>1;i--) 9 { 10 swap(array, 1, i); 11 HeapAdjust(array, 1, i-1);//从上到下,从左向右调整 12 } 13 } 14 void HeapAdjust(int array[], int s, int n ) 15 { 16 int i,temp; 17 temp = array[s]; 18 for(i=2*s;i<=n;i*=2) 19 { 20 if(i<n&&array[i]<array[i+1]) 21 { 22 i++; 23 } 24 if(temp>=array[i]) 25 { 26 break; 27 } 28 array[s]=array[i]; 29 s=i; 30 } 31 array[s]=temp; 32 } 33 void swap(int array[], int i, int j) 34 { 35 int temp; 36 37 temp=array[i]; 38 array[i]=array[j]; 39 array[j]=temp; 40 }
7 希尔排序
7.1 过程
希尔排序是插入排序改良的算法,希尔排序步长从大到小调整,第一次循环后面元素逐个和前面元素按间隔步长进行比较并交换,直至步长为1,步长选择是关键。
7.2 动图

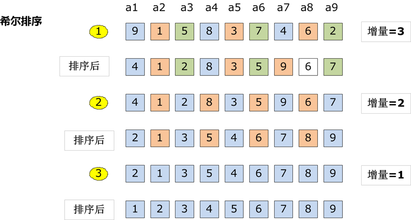
7.3 核心程序(函数)
//下面是插入排序1 void InsertSort( int array[], int n) 2 { 3 int i,j,temp; 4 for( i=0;i<n;i++ ) 5 { 6 if(array[i]<array[i-1]) 7 { 8 temp=array[i]; 9 for( j=i-1;array[j]>temp;j--) 10 { 11 array[j+1]=array[j]; 12 } 13 array[j+1]=temp; 14 } 15 } 16 } 17 //在插入排序基础上修改得到希尔排序 18 void SheelSort( int array[], int n) 19 { 20 int i,j,temp; 21 int gap=n; //~~~~~~~~~~~~~~~~~~~~~ 22 do{ 23 gap=gap/3+1; //~~~~~~~~~~~~~~~~~~ 24 for( i=gap;i<n;i++ ) 25 { 26 if(array[i]<array[i-gap]) 27 { 28 temp=array[i]; 29 for( j=i-gap;array[j]>temp;j-=gap) 30 { 31 array[j+gap]=array[j]; 32 } 33 array[j+gap]=temp; 34 } 35 } 36 }while(gap>1); //~~~~~~~~~~~~~~~~~~~~~~ 37 38 }
8 桶排序(基数排序和基数排序的思想)
8.1 过程
桶排序是计数排序的变种,把计数排序中相邻的m个”小桶”放到一个”大桶”中,在分完桶后,对每个桶进行排序(一般用快排),然后合并成最后的结果。
8.2 图解

8.3 核心程序
1 #include <stdio.h> 2 int main() 3 { 4 int a[11],i,j,t; 5 for(i=0;i<=10;i++) 6 a[i]=0; //初始化为0 7 8 for(i=1;i<=5;i++) //循环读入5个数 9 { 10 scanf("%d",&t); //把每一个数读到变量t中 11 a[t]++; //进行计数(核心行) 12 } 13 14 for(i=0;i<=10;i++) //依次判断a[0]~a[10] 15 for(j=1;j<=a[i];j++) //出现了几次就打印几次 16 printf("%d ",i); 17 18 getchar();getchar(); 19 //这里的getchar();用来暂停程序,以便查看程序输出的内容 20 //也可以用system("pause");等来代替 21 return 0; 22 }
9 计数排序
9.1 过程
算法的步骤如下:
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
9.2 图解
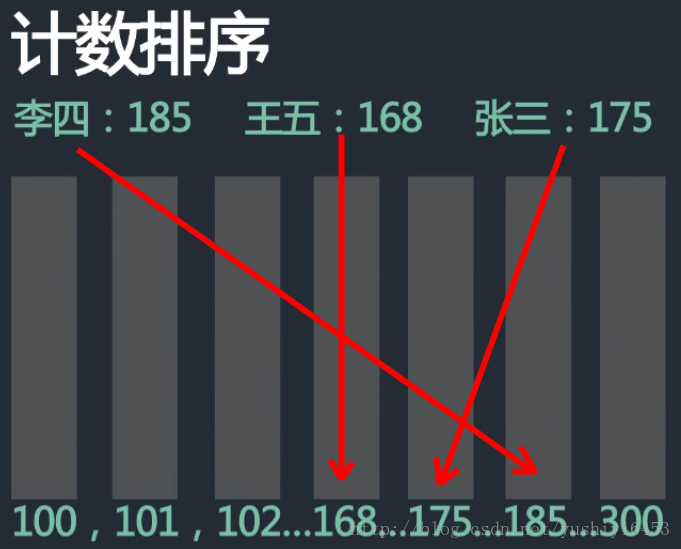
9.3 核心程序(函数)
程序1:1 #define NUM_RANGE (100) //预定义数据范围上限,即K的值 2 3 void counting_sort(int *ini_arr, int *sorted_arr, int n) //所需空间为 2*n+k 4 { 5 int *count_arr = (int *)malloc(sizeof(int) * NUM_RANGE); 6 int i, j, k; 7 8 //初始化统计数组元素为值为零 9 for(k=0; k<NUM_RANGE; k++){ 10 count_arr[k] = 0; 11 } 12 //统计数组中,每个元素出现的次数 13 for(i=0; i<n; i++){ 14 count_arr[ini_arr[i]]++; 15 } 16 17 //统计数组计数,每项存前N项和,这实质为排序过程 18 for(k=1; k<NUM_RANGE; k++){ 19 count_arr[k] += count_arr[k-1]; 20 } 21 22 //将计数排序结果转化为数组元素的真实排序结果 23 for(j=n-1 ; j>=0; j--){ 24 int elem = ini_arr[j]; //取待排序元素 25 int index = count_arr[elem]-1; //待排序元素在有序数组中的序号 26 sorted_arr[index] = elem; //将待排序元素存入结果数组中 27 count_arr[elem]--; //修正排序结果,其实是针对算得元素的修正 28 } 29 free(count_arr); 30 }
程序2:C++(最大最小压缩桶数)1 public static void countSort(int[] arr) { 2 if (arr == null || arr.length < 2) { 3 return; 4 } 5 int min = arr[0]; 6 int max = arr[0]; 7 for (int i = 1; i < arr.length; i++) { 8 min = Math.min(arr[i], min); 9 max = Math.max(arr[i], max); 10 } 11 int[] countArr = new int[max - min + 1]; 12 for (int i = 0; i < arr.length; i++) { 13 countArr[arr[i] - min]++; 14 } 15 int index = 0; 16 for (int i = 0; i < countArr.length; i++) { 17 while (countArr[i]-- > 0) { 18 arr[index++] = i + min; 19 } 20 }
10 基数排序
10.1 过程
基数排序是基于数据位数的一种排序算法。
它有两种算法
①LSD–Least Significant Digit first 从低位(个位)向高位排。
②MSD– Most Significant Digit first 从高位向低位(个位)排。
时间复杂度O(N*最大位数)。
空间复杂度O(N)。
10.2 图解

对a[n]按照个位0~9进行桶排序: 
对b[n]进行累加得到c[n],用于b[n]中重复元素计数
!!!b[n]中的元素为temp中的位置!!!跳跃的用++补上: 
temp数组为排序后的数组,写回a[n]。temp为按顺序倒出桶中的数据(联合b[n],c[n],a[n]得到),重复元素按顺序输出:

10.3 核心程序
//基数排序1 //LSD 先以低位排,再以高位排 2 //MSD 先以高位排,再以低位排 3 void LSDSort(int *a, int n) 4 { 5 assert(a); //判断a是否为空,也可以a为空||n<2返回 6 int digit = 0; //最大位数初始化 7 for (int i = 0; i < n; ++i) 8 { //求最大位数 9 while (a[i] > (pow(10,digit))) //pow函数要包含头文件math.h,pow(10,digit)=10^digit 10 { 11 digit++; 12 } 13 } 14 int flag = 1; //位数 15 for (int j = 1; j <= digit; ++j) 16 { 17 //建立数组统计每个位出现数据次数(Digit[n]为桶排序b[n]) 18 int Digit[10] = { 0 }; 19 for (int i = 0; i < n; ++i) 20 { 21 Digit[(a[i] / flag)%10]++; //flag=1时为按个位桶排序 22 } 23 //建立数组统计起始下标(BeginIndex[n]为个数累加c[n],用于记录重复元素位置 24 //flag=1时,下标代表个位数值,数值代表位置,跳跃代表重复) 25 int BeginIndex[10] = { 0 }; 26 for (int i = 1; i < 10; ++i) 27 { 28 //累加个数 29 BeginIndex[i] = BeginIndex[i - 1] + Digit[i - 1]; 30 } 31 //建立辅助空间进行排序 32 //下面两条可以用calloc函数实现 33 int *tmp = new int[n]; 34 memset(tmp, 0, sizeof(int)*n);//初始化 35 //联合各数组求排序后的位置存在temp中 36 for (int i = 0; i < n; ++i) 37 { 38 int index = (a[i] / flag)%10; //桶排序和位置数组中的下标 39 //计算temp相应位置对应a[i]中的元素,++为BeginIndex数组数值加1 40 //跳跃间隔用++来补,先用再++ 41 tmp[BeginIndex[index]++] = a[i]; 42 } 43 //将数据重新写回原空间 44 for (int i = 0; i < n; ++i) 45 { 46 a[i] = tmp[i]; 47 } 48 flag = flag * 10; 49 delete[] tmp; 50 } 51 }
附:
1 完整程序框架(冒泡排序举例)
1.1 VS2010程序
1 #include "stdafx.h" 2 #include "stdio.h" 3 #include <stdlib.h> 4 5 void BubbleSort(int array[], int n){ 6 int i,j,k,count1=0, count2=0; 7 for(i=0; i<n-1; i++) 8 for(j=n-1; j>i; j--) 9 { 10 count1++; 11 if(array[j-1]>array[j]) 12 { 13 count2++; 14 k=array[j-1]; 15 array[j-1]=array[j]; 16 array[j]=k; 17 } 18 } 19 printf("总共的循环次序为:%d, 总共的交换次序为:%d\n\n", count1, count2); 20 } 21 22 23 int main(int argc, _TCHAR* argv[]) 24 { 25 int as[]={0,1,2,3,4,6,8,5,9,7}; 26 BubbleSort(as, 10); 27 for(int i=0; i<10; i++) 28 { 29 printf("%d", as[i]); 30 } 31 printf("\n\n"); 32 system("pause"); 33 return 0; 34 }
1.2 执行程序(OJ)
1 #include <stdio.h> 2 3 void BubbleSort(int array[], int n){ 4 int i,j,k,count1=0, count2=0; 5 for(i=0; i<n-1; i++) 6 for(j=n-1; j>i; j--) 7 { 8 count1++; 9 if(array[j-1]>array[j]) 10 { 11 count2++; 12 k=array[j-1]; 13 array[j-1]=array[j]; 14 array[j]=k; 15 } 16 } 17 printf("总共的循环次序为:%d, 总共的交换次序为:%d\n\n", count1, count2); 18 } 19 20 int main() 21 { 22 int as[]={0,1,2,3,4,6,8,5,9,7}; 23 BubbleSort(as, 10); 24 int i=0; 25 for(i=0; i<10; i++) 26 { 27 printf("%d", as[i]); 28 } 29 return 0; 30 }
2 关于交换的优化
不用中间变量进行交换
if(A[j] <= A[i]){
A[j] = A[j] + A[i];
A[i] = A[j] - A[i];
A[j] = A[j] - A[i];
}
3 C语言实现数组动态输入
1 #include <stdio.h> 2 #include <assert.h> //断言头文件 3 #include <stdlib.h> 4 5 int main(int argc, char const *argv[]) 6 { 7 int size = 0; 8 scanf("%d", &size); //首先输入数组个数 9 assert(size > 0); //判断数组个数是否非法 10 11 int *array = (int *)calloc(size, sizeof(int)); //动态分配数组 12 if(!R1) 13 { 14 return; //申请空间失败 15 } 16 17 int i = 0; 18 for (i = 0; i < size; ++i) { 19 scanf("%d", &array[i]); 20 } 21 22 mergeSort(array, size); 23 printArray(array, size); 24 25 free(array); 26 return 0; 27 }
- 注:
1.colloc与malloc类似,但是主要的区别是存储在已分配的内存空间中的值默认为0,使用malloc时,已分配的内存中可以是任意的值.
2.colloc需要两个参数,第一个是需要分配内存的变量的个数,第二个是每个变量的大小.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号