初识elasticsearch
什么是elasticsearch
- 一款非常强大的开源搜索引擎
- elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
- 采用倒排索引
正向索引:正排索引按照文档的顺序存储索引,索引的键是文档的标识符(如ID),值是文档的详细信息,如标题、内容摘要、发布日期等。这种结构使得正排索引适合于通过已知文档标识符快速访问文档内容。
比如:查询ID为1的数据(select * from xxx where id=1)可快速查询到数据
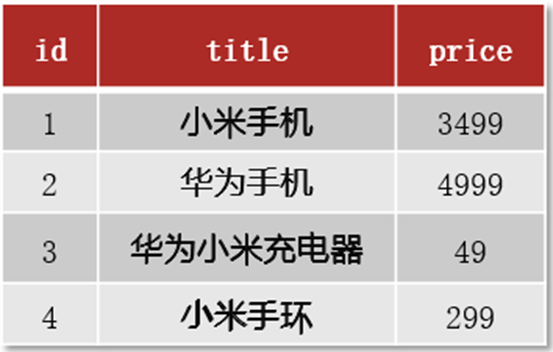
这是这对索引的查询,查询速度是很好的,如果需要根据title(非索引)来查询数据,那么就需要逐条匹配,可想而知在数据量过大的情况下,查询速度就会很慢
比如:现在我需要查询title包含手机的数据(select * from xxx where title like '%手机%'),会逐条检索,查找符合包含手机的数据,存入结果集
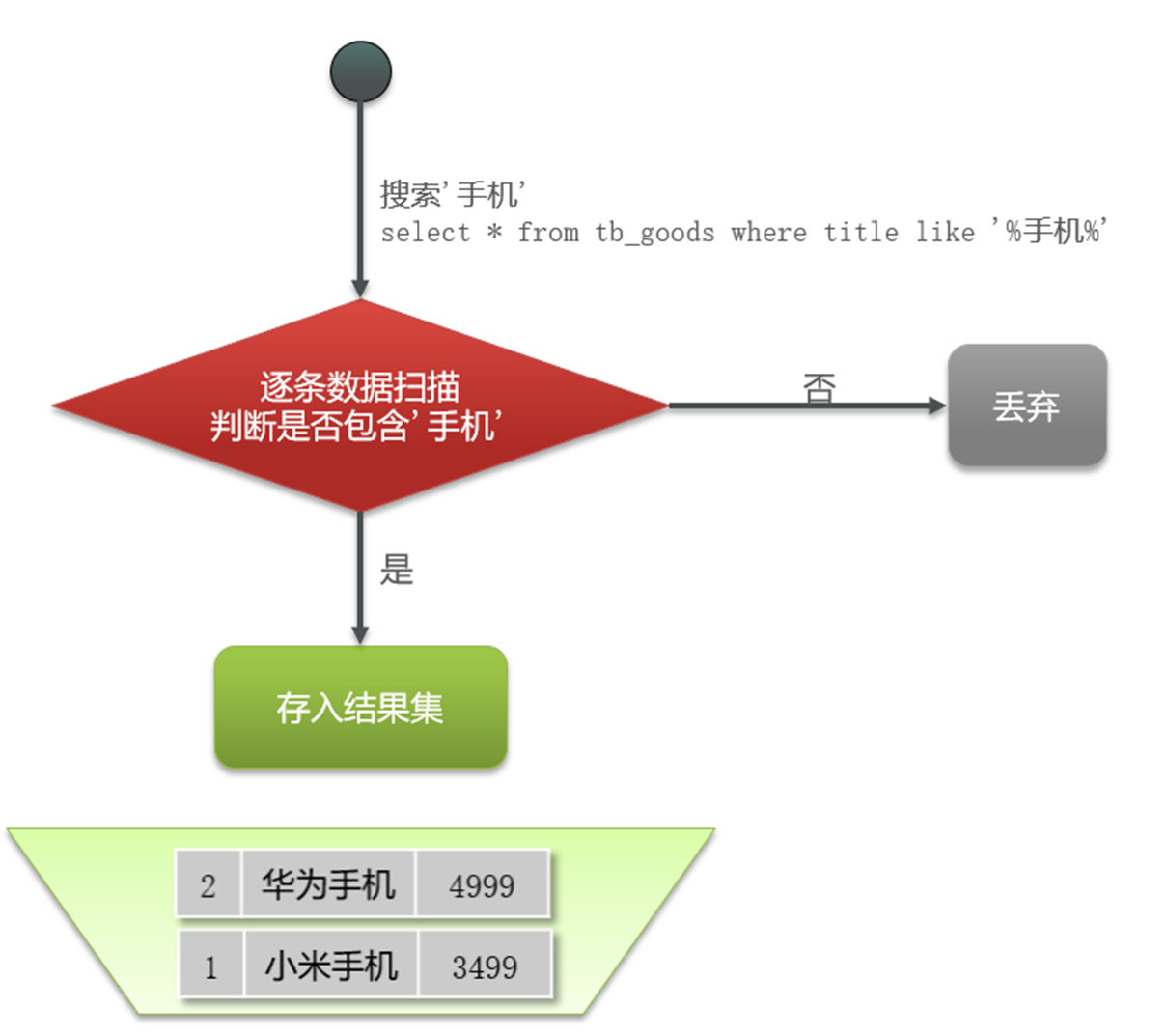
在数据庞大的情况下,其效率就会很慢。
如何解决此类问题呢,最简单的方法就是为Title也创建索引,但是针对模糊查询来说,其索引是无效的。
倒排索引索引就可以解决此类问题
什么是倒排索引?
倒排索引:倒排索引根据关键词来存储索引,每个独特的词汇或关键词都会被记录在一个索引条目中,条目包含一个或多个指向包含该词汇的文档的指针或引用。倒排索引适合于通过关键词快速找到相关文档。
倒排索引的概念来看,
- 倒排索引是将一段话分成多个词语,
- 每个词语都对应这其数据库中索引,
- 每个词语都是唯一
- 将词语做成索引
如下图:
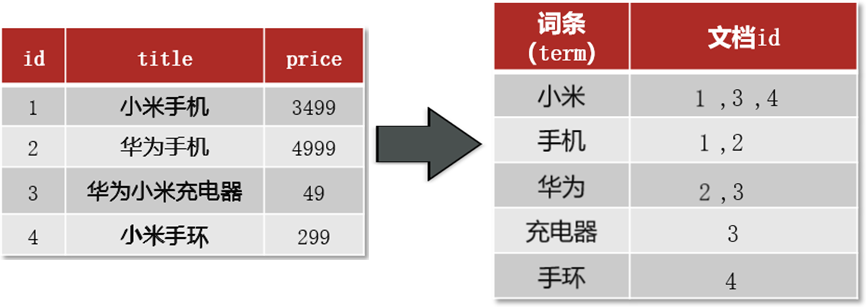
这种情况,获取华为手机的数据,通过分词获取华为和手机两个词条,根据词条去词条列表中获取文档Id,根据文档Id就能获取到对应的数据了。
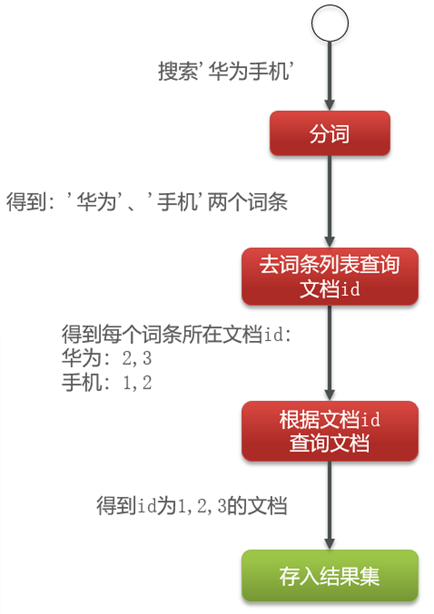
总结:倒排索引为了解决正向索引中非索引字段的模糊查询

 浙公网安备 33010602011771号
浙公网安备 33010602011771号