-
一、数据库的分类
1、关系型数据库:数据和数据之间存在一个或多个连接
DB:最大的关系型数据库,可以存储海量数据
Oracle:Oracle公司旗下的收费的关系型数据库,可以存储较大数据,功能完善
Mysql:Oracle公司旗下的免费的关系型数据库,只能存储较少的数据,功能不完善
SqlServe:微软公司数据库,有着良好的操作界面,可以存储较大的数据,运行效率高,但是只能用于window系统,不能跨平台
2、非关系型数据库【指的是数据之间没有联系】:NOSql:not only Sql 意思是不仅仅是sql,作为关系型数据库的辅助,非关系型数据库不是否定了关系型数据库,而是为关系型数据库提供补充【关系型数据库数据结构清晰,但是查询效率低下,非关系型数据库数据结构不清晰,但是查询效率高】
二、SQL语句
SQL:标准化数据库操作语言,用于操作关系型数据库,SQL语句是在所有的关系型数据库中通用的
1.DDL:数据库定义语言,主要负责数据库结构上的创建(create),更改(alter),删除(drop),查看(show)
2.DQL:数据查询语言,主要负责对数据进行查询(select)
3.DML:数据操作语言,主要负责对数据进行添加(insert),修改(update),删除(delete)
4.DCL:数据控制语句,主要负责数据库权限设置
5.TCL:事务控制语言,主要负责一些流程控制中的开始(begin)、提交(commit)、回滚(rollback)
DDL数据库定义语言
一、数据库操作
1.show databases; 查询现有数据库
2.create database 数据库名 default character set '字符集类型';
创建数据库并指定该数据库的字符集类型
3.show create database 数据库名 ;查看创建数据库的语句
4.alter database 数据库名 character set '字符集';修改数据库的字符集
5.drop database 数据库名;删除某个数据库
6.use 数据库名;切换到某个数据库
二、表操作:
ps:表【table】在数据库【database】创建在下,作为数据库的载体使用,数据被记录在表中,表存在与数据库中,因此操作表时候需要先切换到对应数据库中【use指令】
1.创建表:
create table `表名`(
`字段名1` 字段类型 字段约束1 字段约束2,
`字段名2` 字段类型 字段约束1 字段约束2,
....
)ps:
-
数据库的字段类型于java不同
常用的字段类型
数据库 Java 注意 INT 整形变量 可以不用设置具体长度,默认11位 DOUBLE 浮点类型 创建表时指定具体长度 VARCHAR String字符串 创建时必须注明长度,默认255 DATETIME String字符串/Date时间对象 格式自动yyyy-MM-dd HH:mm:ss,内容不变 TIMESTAMP String字符串/Date时间对象 格式自动yyyy-MM-dd HH:mm:ss,内容可变 TEXT String字符串 文本类型,不限制长度,无需设置具体长度大小 -
约束:约束就是限制,用于限制表中字段列内存储值
ps:SQL一共6中约束,mysql只能支持5种
default:默认约束
设置字段列中的默认值,当插入新的数据时,如果该数据的该列未设置内容,则自动沿用默认约束设置默认值
not null:非空约束
限制字段内必须存储内容,不可以为null【未定义】,只对insert【添加】,update【修改】语句生效
unique:唯一约束
设置该约束的字段列中数据不可以重复,可以为null
primary key:主键约束
该列中的值非空且唯一,注意:一个表只能有一个主键,主键是作为数据的标记
主键分类:
(1)、单一主键:只以一个列作为主键
ps:
1.如果以int字段作为单一主键时,一般会设置其auto_increment【自动递增:没插入一条数据自动增加1】,从一开始,一旦使用就不会重复,即便“清除”整个表也会从清空前最大值开始累加,除非“截断”【truncate】整个表将表重置才会从1重新开始
2.如果以varchar作为字段设置单一主键时,一般会设置其存储UUID通用唯一识别码(Universally Unique identifier)的缩写
(2)、联合主键:以多个列内容相互结合产生——唯一主键
ps:不是限制单一的列,而是限制组合结果,组合结果要唯一不要重复
FOREIGN KEY:外键约束
外键约束是用于限制外键字段中值,增强表中数据的一致性
ps:“外键字段”用于记录与其他表中数据的联系
格式:
create table 表名(
字段 类型 约束...,
外键字段 类型
FOREIGN KEY (外键列) reference 表名(列名)
);
级联操作:是加在外键约束上,当外键参照字段数据发生变化【update更新,delete删除】时,外键中内容需要做出相应改变这个就是级联操作,用于保证数据一致性,级联操作一共有4种,用于两种情况【更新时,删除时】
(1)restrict:默认级联,只要创建外键约束就自动加,表现形式是“当字段被外键依赖时,该字段数据不能删除,不能修改”
(2)cascade:表现形式是“当字段被外键依赖时,如果修改对应外键字段自动修改,如果删除对应外键字段自动删除“
(3)set null:表现形式是“当字段被外键依赖时,如果修改对应外键自动设置null,如果删除对应外键字段自动设置为null”
(4)、no action:和restrict表现形式一致
check:检查约束
用于限制输入的值,只有满足条件数据才可以被插入,注意mysql可以写check约束,但是无效果
##
2.drop table 表名;删除表
3.给表中添加新字段
Alter table 表名 add 新字段 字段类型 约束
4.删除列
Alter table 表名 drop column 列名
5.截断表【重置表】
TRUNCATE TABLE 表名
DML
一、DML:数据库操作语言,用于操作【增,删,改】表中数据
1.增
增:向表中插入数据:
(1)基础格式:向表中插入一条数据,要求value值要与表中字段一一对应,包括自增主键字段也要手动赋值
insert into 表名 value (值,值,值,...)
(2)、指定字段插入格式:向表中插入一条数据,只是向对应字段插入,要求字段和值一一对应
insert into 表名 (表字段,表字段,...) value (值1,值2,...)
(3)、插入多条数据格式:同时向表中插入多条数据
insert into 表名 values (值,值...),(值,值...),(值,值...)......
2.删
删:删除表中的数据
ps:删除语句一定要搭配where条件语句使用,否则会删除整个表中的数据
格式
delete from 表 where 条件
3.改
更新:修改表中数据
ps:必须配合where语句使用,否则会更改整个表
格式:
Update 表名 set 字段=新值,字段=新值...where 条件
where后条件
-
and【且】和 or【或者】
(1)、比较运算符:>,<,>=,<=,!=,=
(2)、在...之间:字段 between A值 and B值
ps:用于代替“字段>=A 且 字段 <=B”,因为同一个字段>=A且<=B有时候会被误识别即=A又=B会产生歧义,因此使用between代替这个情况
(3)、in(...)和not in(...):包含于和不包含于
补充:in常用于代替or,or是或者会分隔前后两组条件
(4)、is null 和is not null:判断字段是否为null
(5)、字段 like “...”:模糊匹配字符串【只能用于字符串类,例如:varchar,text】,只能匹配其中某一部分数据,满足即成立
(5.1)字段like '值%':以xxx值开头的数据
(5.2)字段like '%值':以xxx值结尾的数据
(5.3)字段like '%值%':包含xxx的数据
(6)、使用正则表达式匹配字符串【只能用于字符串类,例如:varchar,text】
注:正则表达式是用于验证字符串格式,是一种格式验证
使用格式: 字段名 regexp '正则表达式'
ps:最后的‘i’代表的是忽略字母大小写,可以省略,省略后代表不忽略字母大小写
DQL
DQL:数据查询语句,用于查询表中数据
一、基础查询语句
基础查询语句:默认查询全部数据
格式:select 查询字段【ps:写“*”代表查询全部字段】 from 表;
二、条件查询语句
条件查询语句:select查询全部数据,使用where将数据进行条件筛选,最后得到满足条件的数据
三、查询结果的列运算
查询结果的列运算:select支持对同一数据中的多个列中值进行横向运算
补充:concat拼接
四、去重查询
SELECT DISTINCT:是对所有查询列的组合结果进行去重
五、聚合函数
聚合函数:纵向的对某列进行跨行运算,每一组【group】只会有一个结果【因此称为聚合函数】,一张表默认为一组
1.sum(列)求和函数
2.avg(列) 平均数函数
3.max(列)最大值函数
4.min(列)最小值函数
5.count(列)计数函数
PS:聚合函数不能在where中使用
六、分组group by
分组group by:可以根据列中的数据进行分组,数据相同的为一组,不同的会在另外一组,常与聚合函数一起使用
格式:
select ... from ...where 【分组前条件】...group by 列名 【依据列】
ps:
1.聚合函数会将多行数据进行整合,因此会造成数据不准确【除了聚合函数外,其他列默认获取该组的第一行数据】
2.有group by 时,聚合函数的列和分组列的数据准确的
七、分组后条件having
分组后条件having:写在group by 之后作为分组后的条件,其中写法与where基本一致,可以聚合函数
结构:
select ... from...where....group by ....having...
八、排序 order by
排序order by:可以对列【支持聚合函数】进行排序,默认是升序,可以使用DESC 让其降序排序
格式:
select ...from...where...group by...having....order by..
ps:
-
order by 可以跟多个列名,多个之间逗号分隔,会从左向右依次满足【先以左边列优先排序,如果左边的无法排序,再依次向右进行排序】
-
九、mysql方言limit分页
mysql方言limit分页:limit只有mysql中有,用于分页查询【取出查询结果的部分结果】
结构:
select ...from...where...group by...having...order by...limit A,B;
PS:
A:代表查询出来的数据的“下标”,下标是每条数据的标记,从0开始
B:代表从A下标开始向后取几条数据,包含A下标那条
十、其他函数
1.UUID():获取uuid
2.LENGTH(...):获取字符串的长度【字节】,汉字在UTF-8下一个汉字占3个字节,GBK【简体中文】中一个汉字占2字节
3.CHAR_LENGTH(...):获取字符串的长度【字符】
4.日期函数:
select NOW();
SELECT CURDATE();
SELECT CURTIME();
5.IFNULL(字段,值):将字段中null变为一个默认值
6.concat(A,B,C):拼接多个字段/值
7.大小写转换:
全部转化为大写
select UPPER("abcdEFg");
全部转化为小写
select LOWER("ERSFabcde");
8.截取字符串:
select substr("abcdefghigk",4);
十一、连表查询
连表查询:通过外键,将多个表之间进行关联,同时查询多个表中的数据
ps:
1、表名过长时可以使用别名代替表名,在当前查询语句中,都要使用该别名来表示该表
2、书写字段时需要注明字段来源与那个表,防止歧义
3、定义表关系时,一定要按照线性顺序定义
线性:避免表关系成为一个循环
子查询、连接查询
一、子查询
子查询:就是查询语句的嵌套【将查询语句结果为条件使用】,子查询总是从内向外处理,性能比较低下,实际开发中尽量不要使用子查询
子查询分类:
(1)、相关子查询:内查询执行依赖于外查询
执行过程:
1、外查询中取出一个元组,将元组相关列的值传递给内查询
2、执行内查询,得到子查询操作值
3、外查询根据子查询返回的结果或者结果集得到满足条件内容
4、重复执行以上步骤
(2)、非相关子查询:
执行过程:
1、执行子查询,其结果不被显示,而是传递给外部查询,并作为外部查询的条件使用
2、执行外部查询,并显示整个结果
子查询的几种情况:
-
一行一列【子查询的结果为单个值】:外部查询可以将子查询的结果作为条件使用
-
多行一列:外部查询需要使用in、not in、any【任意】、all【全部】操作子查询的结果集
-
多列:子查询的结果存在多列时,将作为from后当做一个虚拟表使用
二、连表查询
连表查询:是用于连表查询,MYSQL在处理连接查询时是以“嵌套循环连接算法【Nested-Loop Join Algorithms】”的方式实现,实际上是通过“驱动表【优先执行的表为驱动表】”的结果作为循环数据基础,然后将与“被驱动表【第二执行的表为被驱动表】”中的数据进行依次过滤,最后合并出结果
(1)、JOIN查询原理【算法】
-
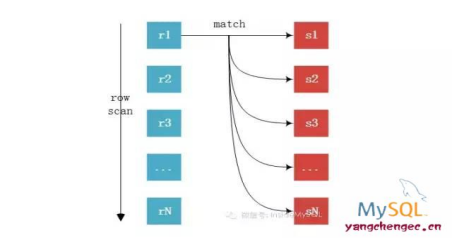
Nested-Loop Join【嵌套循环连接算法】:r为驱动表,s为被匹配表【被驱动表】,可以看到从r中分别取取出r1、r2、....、m去匹配s表的列,然后再合并数据,对s表进行了m次访问,对数据库开销大
![]()
-
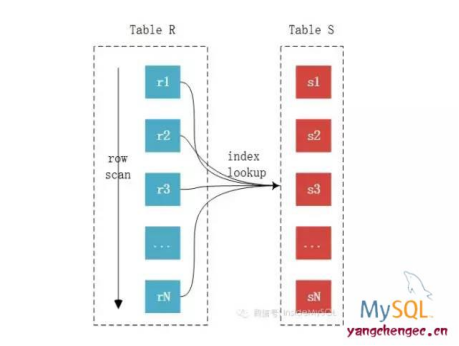
Index Nested-Loop Join(索引嵌套):S匹配表【被驱动表】中带有索引,可以通过索引快速的找到相应的内容,无需对整个匹配表尽心依次匹配
![]()
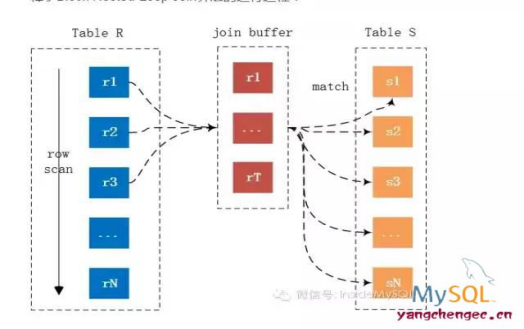
3.Block Nested-Loop Join【基于块的嵌套循环连接】:设立了 join buffer 缓存区,会先从驱动表中读取一部分,存入到缓冲区中,让匹配表依次和缓冲区的内容比较,mysql默认的join_buffer_size=256K,可以通过适当增加join_buffer_size实现对join查询优化
![]()
(2)、常用连接查询方式
1. 内连接inner join /join
格式:select ... from A inner join B on 连表条件

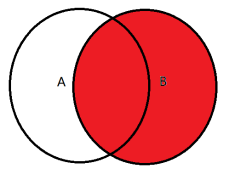
2. 外连接:
2.1:左外连接:left join /left outer join :以join左表为驱动表,将其内容全部查出,右表会根据条件查询出符合内容,左外连接是强制以左表为驱动表,会无视“小表驱动大表”的原则,导致性能降低
![]()
格式:select.... from A left join B on 条件
2.2:右外连接:right join /right outer join :以join右表为驱动表,将其内容全部查出,左表会根据条件查询出符合内容,右外连接是强制以右表为驱动表,会无视“小表驱动大表”的原则,导致性能降低减低
格式:select ...from A right join B on 条件
![]()
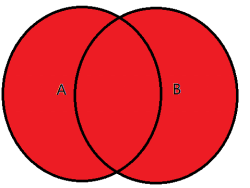
2.3全外连接 full join/full outer join :mysql不支持,可以使用union代替,全外连接实际上就是左连接+右连接
![]()
ps:union和union all用于拼接两个查询语句结果,要求是两个查询语句的结果列数相同,否则无法拼接
union 是合并拼接,会省略重复内容,union all 是拼接全部,会保留所有内容
3.连接查询的用法
用于代替子查询【数据优化的一种方式:使用连接查询代替子查询】,mysql中禁止使用多张表的join查询,因为join查询在mysql中效率低下【当然是比子查询快】,因此mysql优化的思路是将复杂的SQL语句尽量拆分成简单的SQL操作
explain 性能分析
一、用处
用处:模拟执行sql语句,可查看SQL的执行情况
格式:expain +sql语句
![]()
二、字段介绍
1、id:查询的序号,表示的select语句的执行顺序
(1)、ID相同时:表的执行顺序为从上到下且前表为“驱动表”
(2)、ID不相同时:ID越大则优先度越高越先执行
2、select_type:查询类型:用于区别普通查询,联合查询,子查询等
(1)、simple:简单的select查询,查询中不包含子查询或者union联合查询
(2)、primary:查询中包含复杂的子查询【外层查询】
(3)、subquery:在select或where列表中包含子查询
(4)、union查询中包含union联合查询
(5)、union result:联合查询结果集
(6)、derived:衍生表查询,用的是一个虚拟表,这个虚拟表表示通过select出现的,例如将子查询写在from后,where前时
3、table:查询的表
4、type:显示查询使用的类型
ps:一般要保证查询语句到达range
(1)、system:表中仅一行数据
(2)、const:通过索引直接找到
(3)、eq_ref:唯一索引扫描,对于索引建表中只有一条数据与之匹配,常见的唯一索引或主键扫描
(4)、ref:非唯一索引,返回匹配某个索引的全部行
(5)、range:只检索给定范围的行,使用索引来选择,一般出现在where的between/in 中
(6)、index:index和all的区别为index只遍历索引树,通常比all快
(7)、all:全表遍历,代表没有使用到索引
5、possible keys:支出mysql使用哪个索引在表中找出行
6、key:显示mysql实际决定使用的键【索引】
7、key_len:表示索引使用的字节数,在不丢失索引精度的情况下,索引长度越短越好
8、rows:检索的行数
9、extra:额外信息【常见内容】
(1)、Using where :使用了where过滤
(2)、Using join buffer:使用连接缓存
(3)、Using index:使用了覆盖索引
(4)、UsingFileSort:说明MYSQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,即MYSQL无法使用索引完成的排序成为“文件排序”
(5)、Using temporary :使用了临时表来保存中间结果,MYSQL在对查询结果进行排序的时候使用了临时表,常见于排序Order by 和分组查询 group by。
(6)、Impossible Where:where 子句的值总是false,不能获取任何元组
(7)、Select tables optimized away:在没有group by 子句的情况下,基于索引优化min/max操作或者对于MySAM存储引擎优化Count(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即完成优化
(8)、distinct:优化distinct操作,在找到第一个匹配的元组后即停止找同样值的动作
索引
一、什么是索引
索引(index)是帮助MYSQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向数据),这样就可以在这些数据结构上实现高级查找算法。这种数据结构就是索引,简单来说索引就是用于提高查询效率
二、索引的优势和劣势
优势:
1、类似于书籍的目录,提高数据检索的效率,降低数据库的IO【读写】成本
2.通过索引列对数据进行排序,降低数据的排序成本,降低电脑的CPU消耗。
劣势:
-
实际上索引也是一张表,该表中保存了主键和索引字段,并指向实体类的记录。所以,索引也要占据空间;
-
虽然索引大大提高了DQL效率,但是,同时也降低了DML的速度。如对表进行INSERT/DELETE/UPDATE的时候,MYSQL不但要保存数据,还要保存一下索引文件。
三、索引结构【数据结构】
![]()
注意:mysql索引的默认数据结构是B+TREE,其中聚集索引【聚簇索引】/符合索引/前缀索引/唯一索引默认都是使用B+TREE树,成为索引。
补充【重点】:聚簇索引 和 非聚簇索引
聚簇索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
非聚簇索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚簇索引,聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。
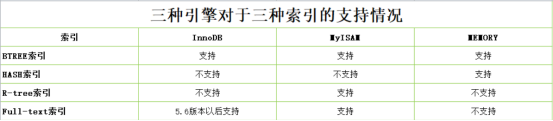
1、BTREE索引:
(1)、BTREE结构:
![]()
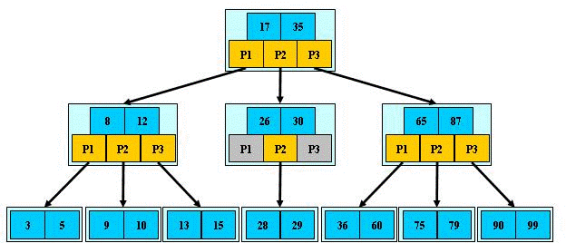
BTREE又叫多路平衡搜索树,一颗m叉的的BTREE特性如下:
-
MYSQL中把一个节点称为分页,一页16kb【默认page_size是16,innodb_page_size最大16】,MYSQL中数据读取的基本单位都是页;
-
m叉树中每个节点最多包含m个孩子;
-
一个节点中的key【所以】从左到右非递减排列
-
除根节点与叶子节点【没有子分支节点】节点外,每个节点至少有ceil(m/2)个孩子
-
若根节点不是叶子结点,则至少有两个孩子
-
每个非叶子节点【带有分支的节点】由n个key与n+1个指针组成,其中key范围是ceil(m/2)-1<=n<=m-1
-
-
|
|
 |
管理
|
管理
MySql
|