
8. SparkSQL综合作业
综合练习:学生课程分数
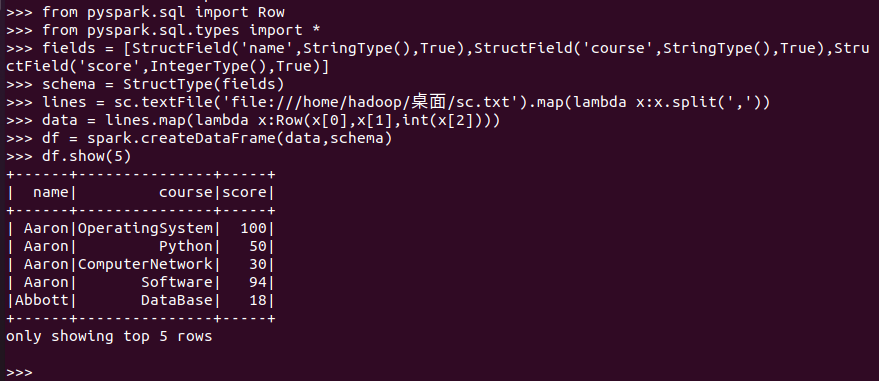
网盘下载sc.txt文件,创建RDD,并转换得到DataFrame。

>>> lines = spark.sparkContext.textFile('file:///home/hadoop/wc/sc.txt')
>>> parts = lines.map(lambda x:x.split(','))
>>> people = parts.map(lambda p : Row(p[0],p[1],int(p[2].strip()) ))
>>> from pyspark.sql.types import IntegerType,StringType
>>> from pyspark.sql.types import StructField,StructType
>>> from pyspark.sql import Row
>>> fields = [StructField('name',StringType(),True),StructField('course',StringType(),True), StructField('age',IntegerType(),True)]
>>> schema = StructType(fields)
>>> lines = spark.sparkContext.textFile('file:///home/hadoop/wc/sc.txt')
>>> parts = lines.map(lambda x:x.split(','))
>>> people = parts.map(lambda p : Row(p[0],p[1],int(p[2].strip()) ))
>>> schemaPeople = spark.createDataFrame(people,schema)
>>> schemaPeople.printSchema()
>>> schemaPeople.show(10)
分别用DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
准备: 创建RDD,并转换为DataFrame;scm持久化;创建spark.sql临时表等预处理:


-
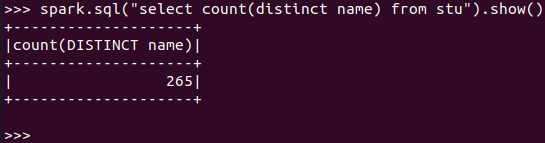
总共有多少学生?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
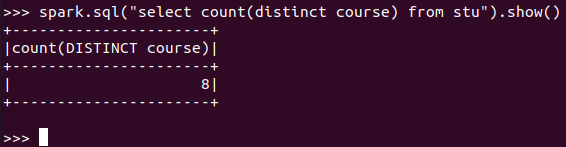
总共开设了多少门课程?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
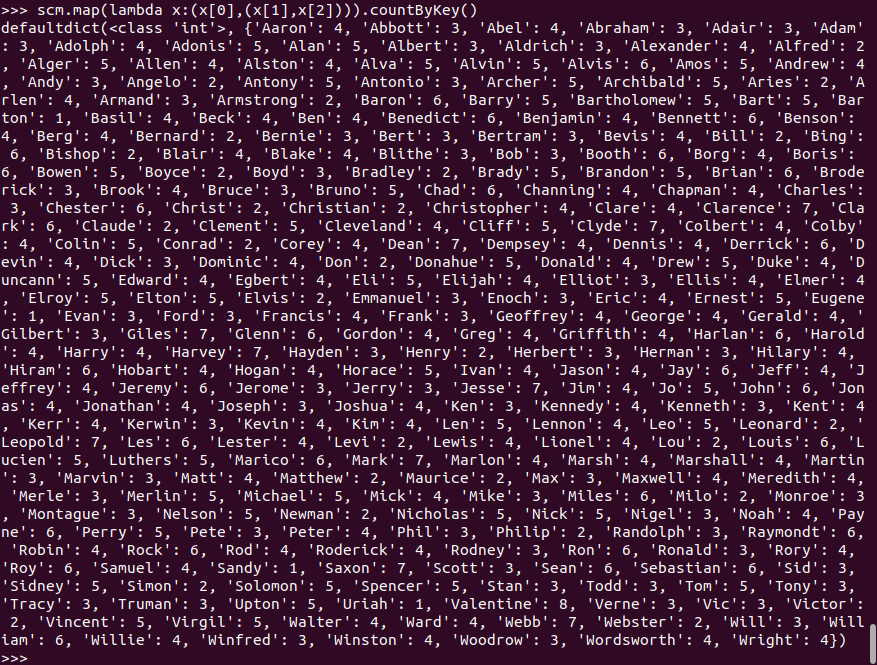
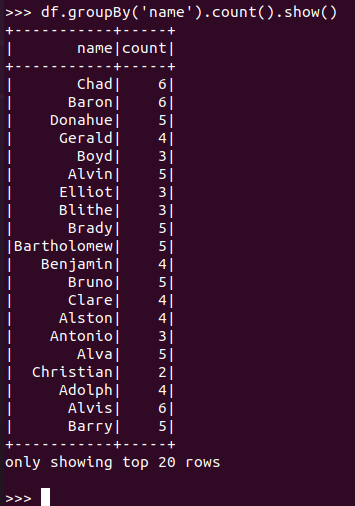
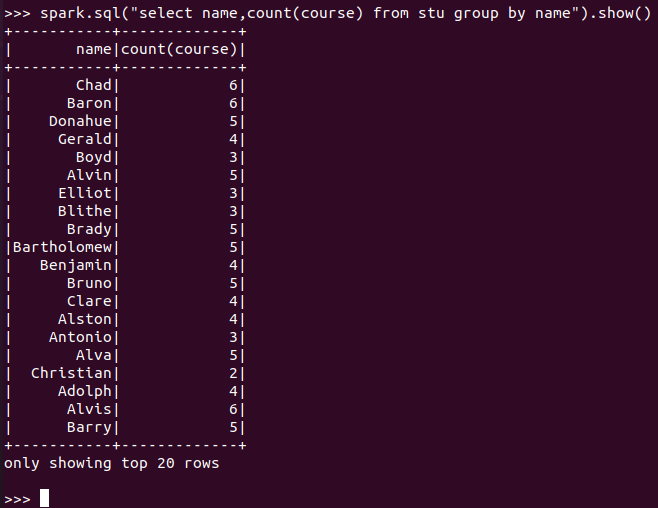
每个学生选修了多少门课?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
每门课程有多少个学生选?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
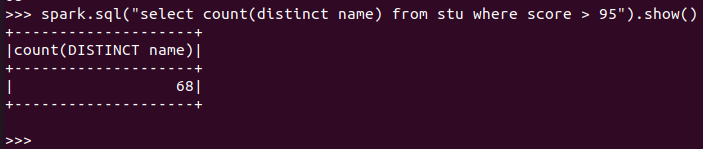
- 每门课程>95分的学生人数
RDD:
DataFrame:
![]()
spark.sql:
![]()
-
课程'Python'有多少个100分?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
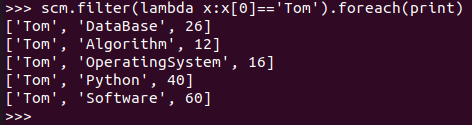
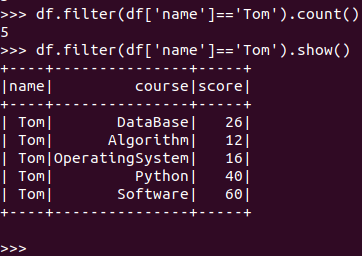
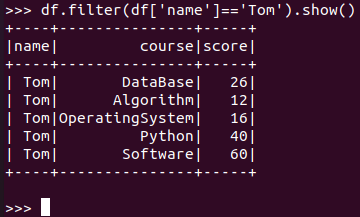
Tom选修了几门课?每门课多少分?
RDD:
![]()
![]()
DataFrame:
![]()
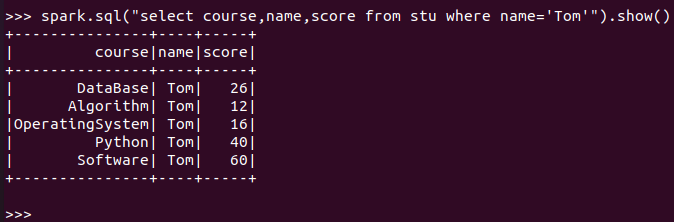
spark.sql:
![]()
![]()
-
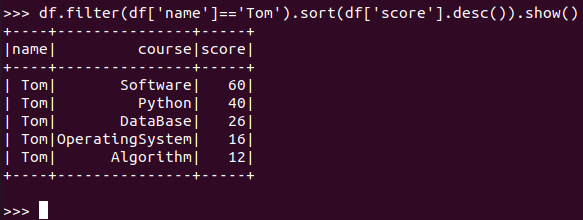
Tom的成绩按分数大小排序。
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
Tom选修了哪几门课?
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
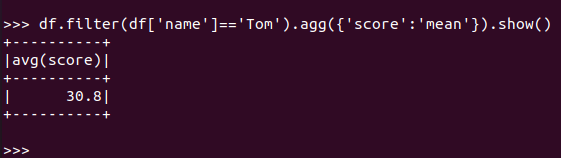
Tom的平均分。
RDD:
![]()
DataFrame:
![]()
spark.sql:(保留了2位小数,round())
![]()
-
'OperatingSystem'不及格人数
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
'OperatingSystem'平均分
RDD:
![]()
DataFrame:
![]()
spark.sql:(保留了2位小数,round())
![]()
-
'OperatingSystem'90分以上人数
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
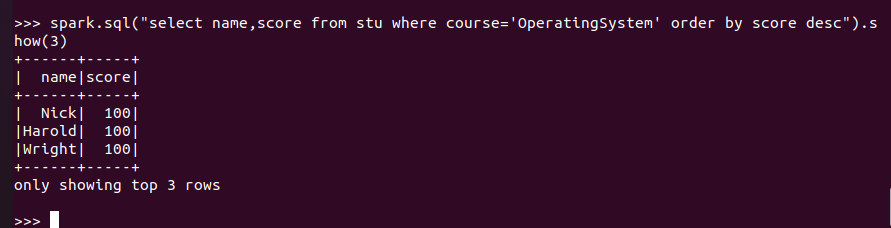
'OperatingSystem'前3名
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
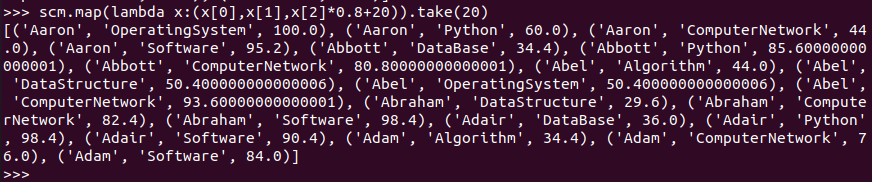
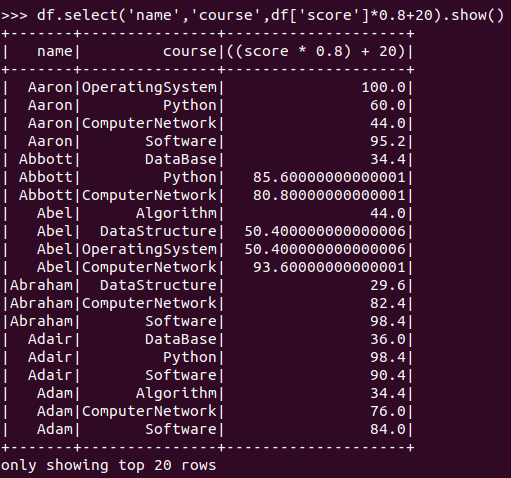
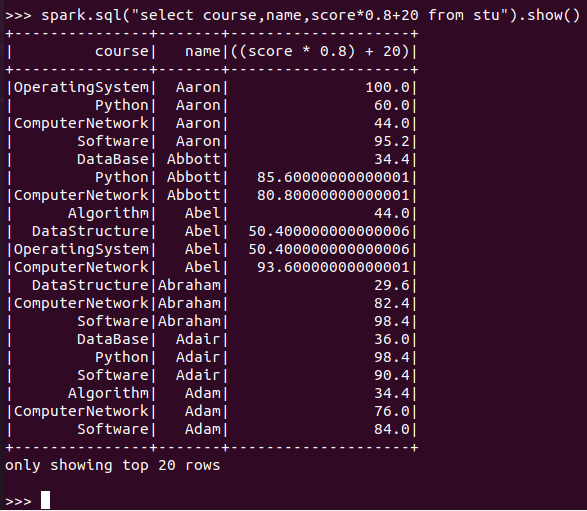
每个分数按比例+20平时分。
RDD:
![]()
DataFrame:
![]()
spark.sql:
![]()
-
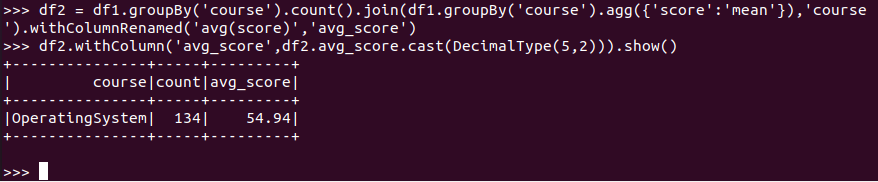
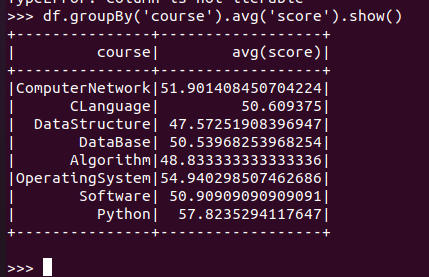
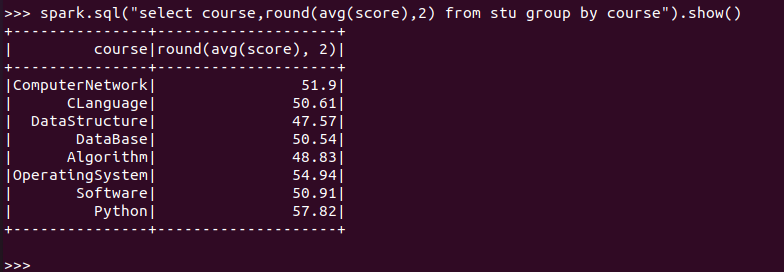
求每门课的平均分
RDD:
DataFrame:
![]()
spark.sql:
![]()
-
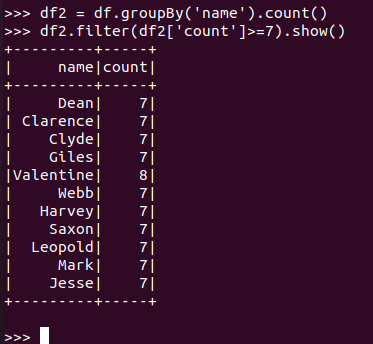
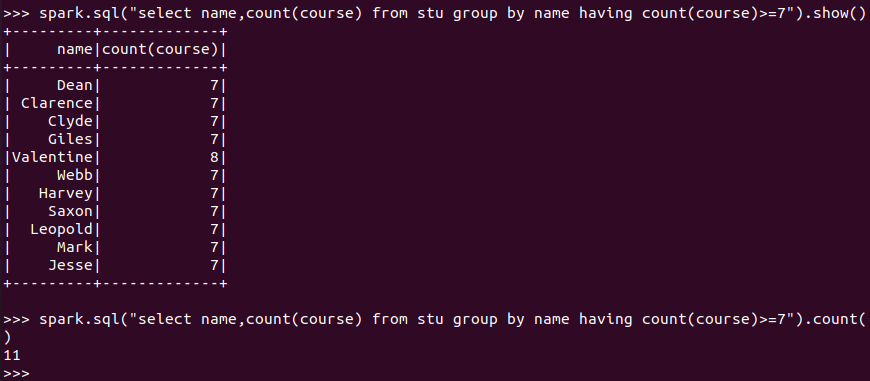
选修了7门课的有多少个学生?
RDD:
DataFrame:
![]()
spark.sql:
![]()
-
每门课大于95分的学生数
RDD:
DataFrame:
spark.sql:
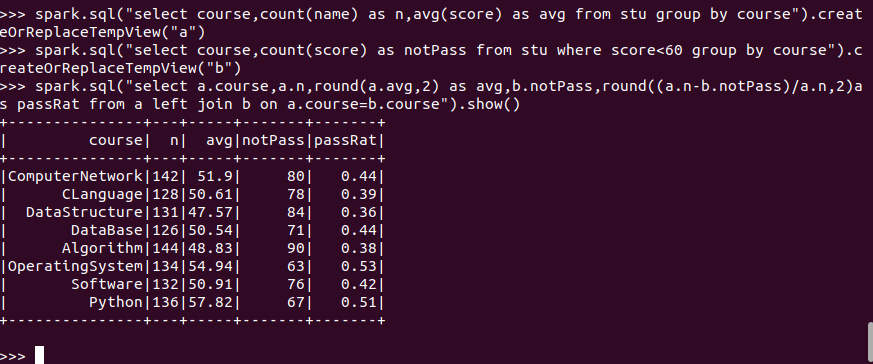
- 每门课的选修人数、平均分、不及格人数、通过率
RDD:
DataFrame:
spark.sql:
![]()






























 浙公网安备 33010602011771号
浙公网安备 33010602011771号