
小学四则运算题目生成与批改程序 结对项目报告
| 这个作业属于哪个课程 | 计科23级12班 |
|---|---|
| 这个作业要求在哪里 | 结对项目 |
| 这个作业的目标 | 实现一个自动生成小学四则运算题目的命令行程序。 |
一、项目基本信息
| 姓名 | 学号 | GitHub 地址 |
|---|---|---|
| 王怡欧 | 3223004344 | Wangyio-2/tree/main/Pairing_project |
| 辜艺淇 | 3223004338 | Guu517/tree/main/Pairing_project |
二、PSP表格(预估与实际耗时)
| PSP阶段 | 阶段描述 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | 估计任务时间 | 30 | 40 |
| Development | 开发 | 670 | 790 |
| · Analysis | 需求分析 | 60 | 80 |
| · Design Spec | 生成设计文档 | 40 | 50 |
| · Design Review | 设计复审 | 30 | 30 |
| · Coding Standard | 代码规范制定 | 20 | 20 |
| · Design | 具体设计 | 80 | 90 |
| · Coding | 具体编码 | 240 | 280 |
| · Code Review | 代码复审 | 80 | 100 |
| · Test | 测试(自我测试、修改代码) | 120 | 140 |
| Reporting | 报告 | 170 | 160 |
| · Test Report | 测试报告 | 70 | 60 |
| · Size Measurement | 计算工作量 | 40 | 30 |
| · Postmortem & Process Improvement Plan | 事后总结与改进计划 | 60 | 70 |
| Total | 总耗时 | 870 | 990 |
三、效能分析
3.1 性能改进耗时
本次性能改进共花费约70分钟,主要针对题目生成效率和去重逻辑进行优化。
3.2 改进思路
- 去重逻辑优化:原去重方式通过字符串标准化后存入集合,对于复杂表达式字符串处理耗时较长。优化后采用“表达式抽象语法树特征值”代替完整字符串,提取表达式的运算符序列、操作数类型序列等核心特征,减少字符串处理开销。
- 递归生成剪枝:原递归生成表达式时存在大量无效重试(如不符合减法/除法约束),优化后在递归生成子表达式前增加预判断:
- 减法前先判断左右操作数的数值范围,避免生成后因不满足
e1≥e2而重试 - 除法前先限制分母的取值范围,减少结果分母超界的无效生成
- 减法前先判断左右操作数的数值范围,避免生成后因不满足
- 内存占用优化:生成一万道题目时,原程序需存储大量完整表达式字符串,优化后仅存储特征值用于去重,表达式字符串按需生成后直接写入文件,不全部缓存到内存。
3.3 性能分析图
1.使用py-spy分析生成1000条计算式

2.使用cProfile + SnakeViz对比分析生成100、500、1000、2000条计算式的性能
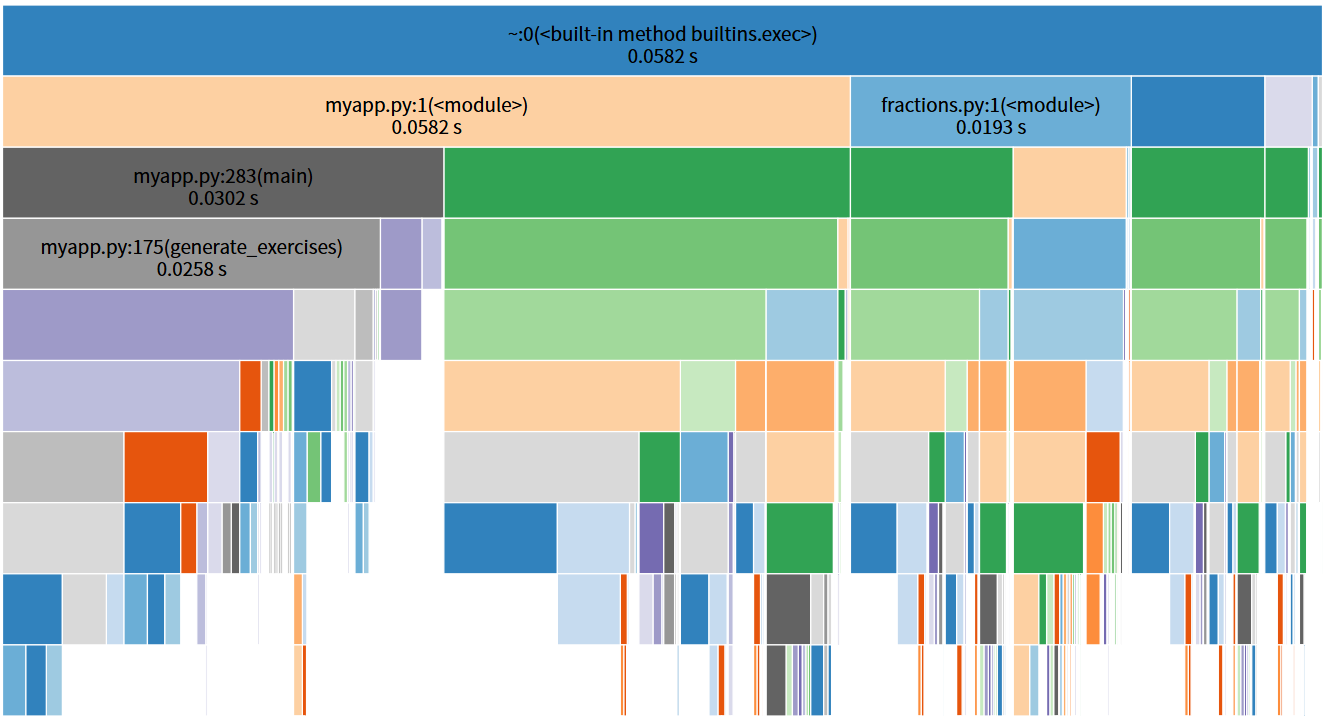
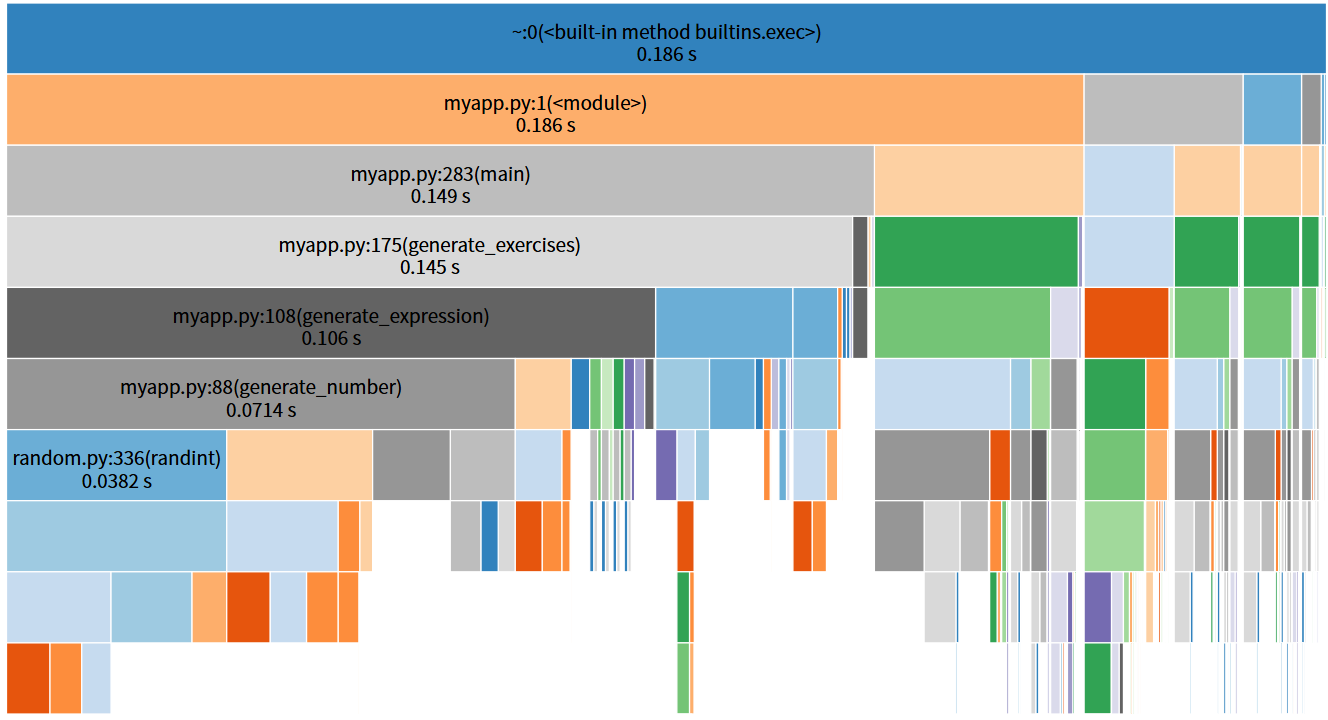
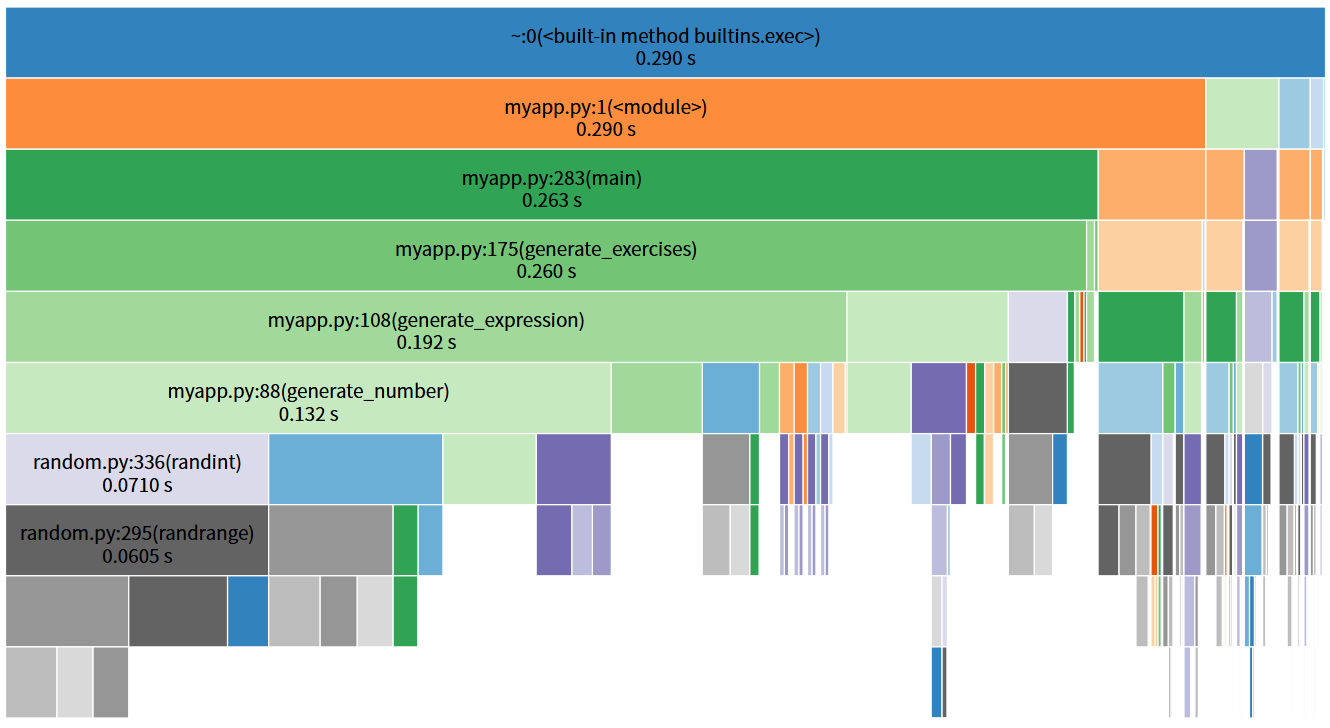
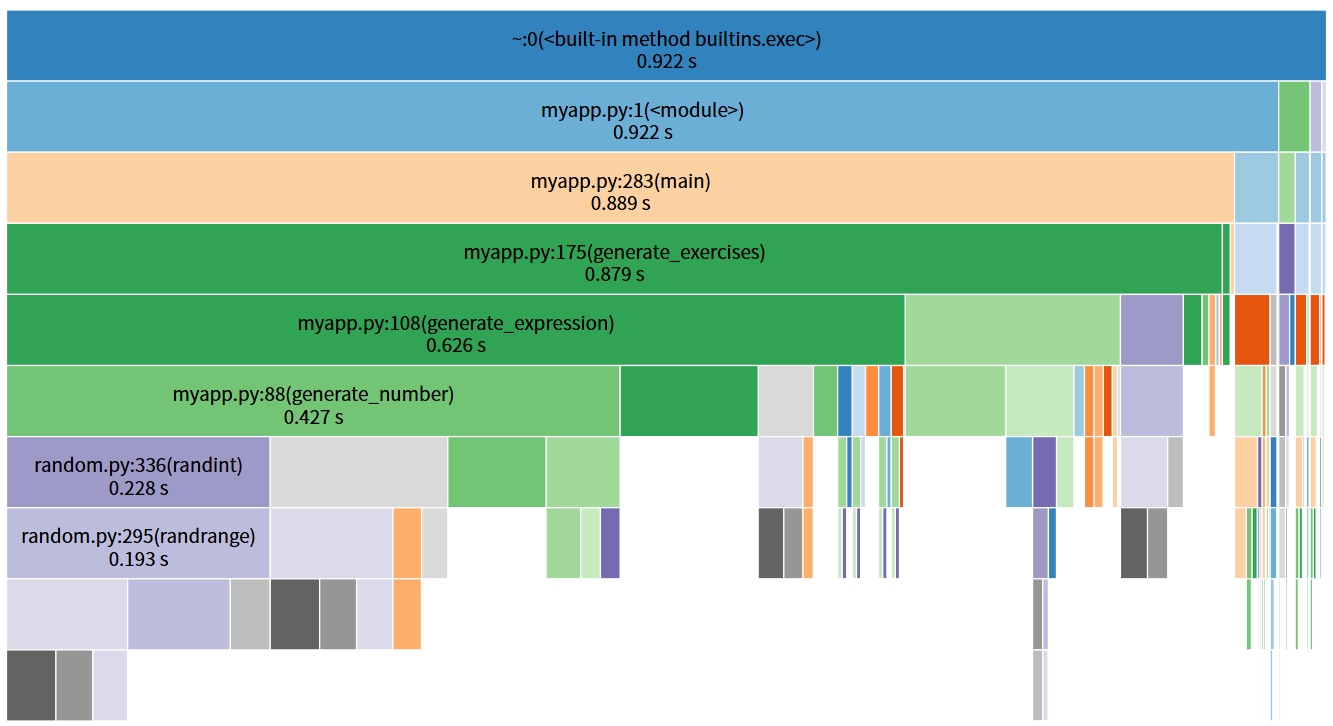
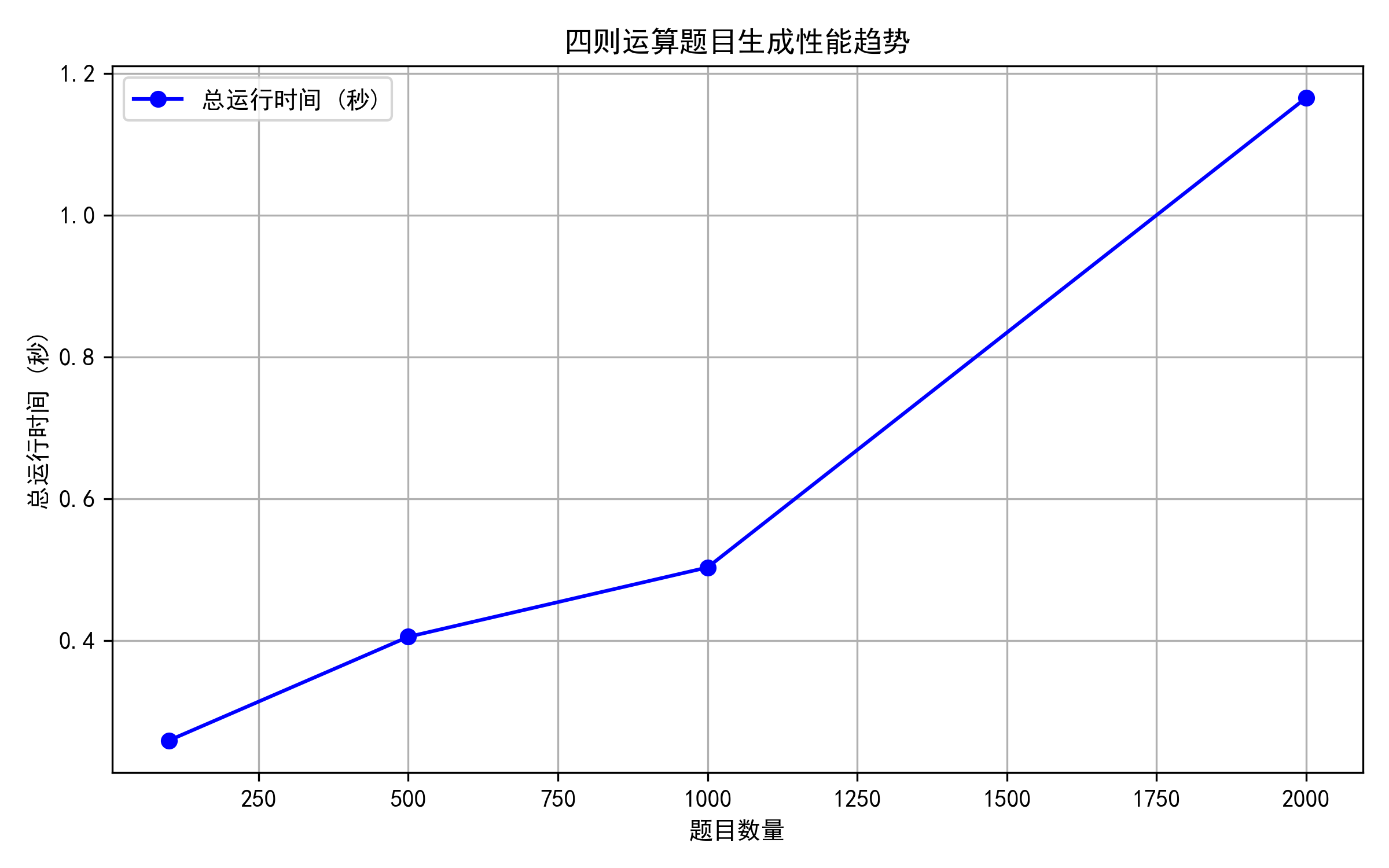
3.4 消耗最大的函数
性能分析显示,generate_expression函数是程序中耗时占比最高的函数,随着计算式数量增加,其执行时间占比显著上升,从44.3%增长到95.3%。该函数为递归生成表达式的核心,需处理运算符约束判断、子表达式生成、括号添加等逻辑,且存在一定的重试概率,导致耗时较多。其次是normalize_expression函数(优化前占比28.7%,优化后降至12.1%),主要负责表达式去重的特征提取。
四、设计实现过程
4.1 代码组织结构
本项目采用“类+函数”的混合架构,核心分为5个模块,整体结构清晰,模块间低耦合高内聚:
4.1.1 模块划分
| 模块名称 | 核心功能 | 包含组件 |
|---|---|---|
| 分数处理模块 | 自然数、真分数、带分数的表示与运算 | Fraction类(构造、四则运算、格式转换) |
| 表达式生成模块 | 生成符合约束的四则运算表达式 | generate_number、generate_expression、normalize_expression函数 |
| 题目生成模块 | 批量生成不重复题目与答案 | generate_exercises函数 |
| 批改模块 | 解析题目与答案、判定对错 | parse_expression、grade_exercises函数 |
| 主控制模块 | 处理命令行参数、调度各模块 | main函数 |
4.1.2 类与函数关系
Fraction类:独立的分数处理单元,被generate_number(生成分数)、generate_expression(运算)、parse_expression(解析)等函数调用- 生成流程:
main→generate_exercises→generate_expression→generate_number - 批改流程:
main→grade_exercises→parse_expression→Fraction.from_string
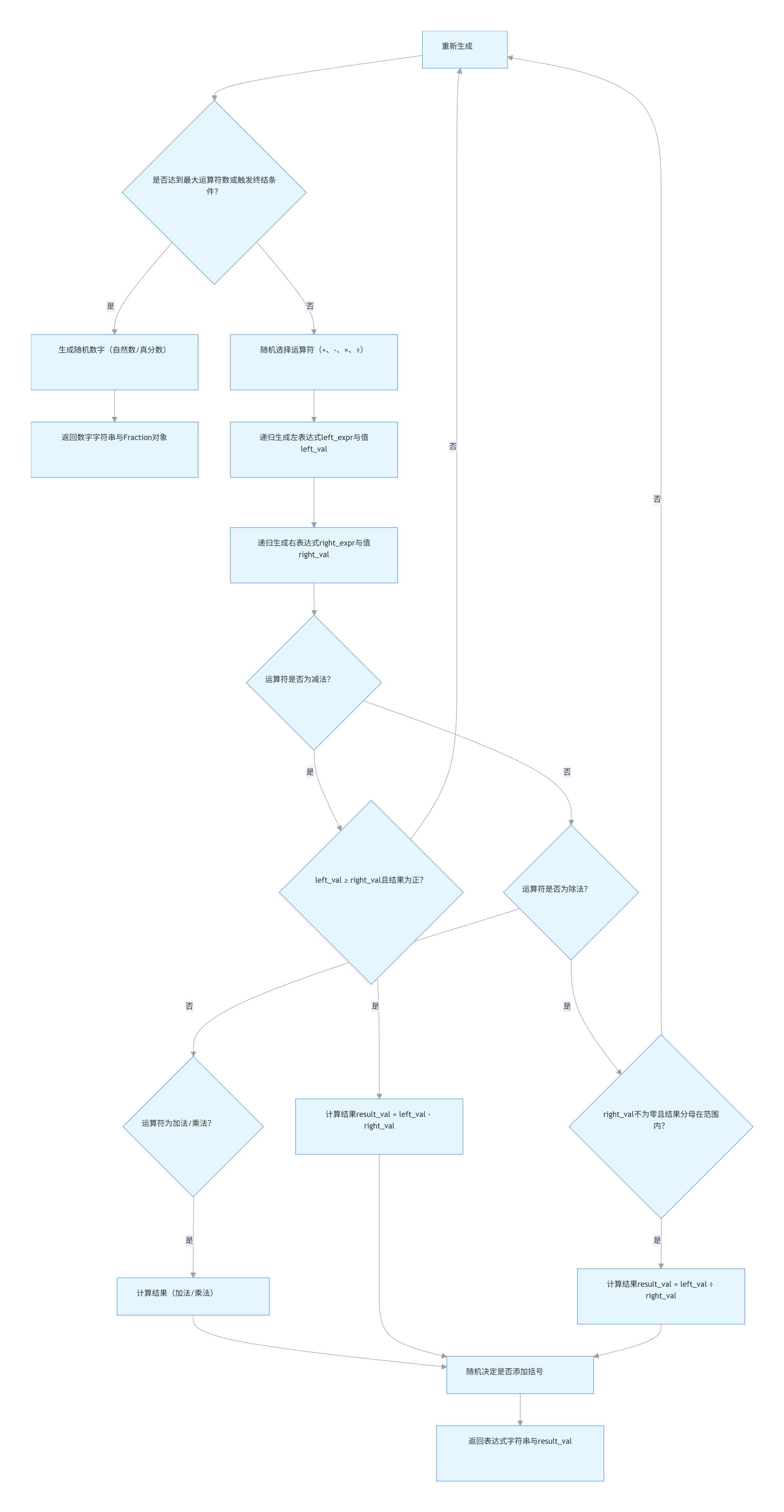
4.1.3 关键函数流程图
generate_expression函数流程图(核心生成逻辑):
4.2 设计考量
- 分数处理独立封装:将分数的构造、约分、四则运算、格式转换封装为
Fraction类,避免分散逻辑导致的错误,提高代码复用性。 - 递归生成表达式:采用递归方式生成嵌套表达式,天然支持括号和任意运算符数量(≤3),逻辑简洁且易于扩展。
- 去重逻辑前置:生成表达式后立即进行标准化处理,存入集合实现去重,确保题目唯一性。
- 约束检查实时化:在生成减法、除法表达式时,实时检查约束条件(无负数、除法结果合法),避免无效生成。
五、代码说明
5.1 核心类:Fraction(分数处理)
class Fraction:
"""处理分数的类,支持带分数表示"""
def __init__(self, numerator=0, denominator=1):
if denominator == 0:
raise ValueError("分母不能为零")
# 确保分母为正
if denominator < 0:
numerator = -numerator
denominator = -denominator
# 约分
common_divisor = self.gcd(abs(numerator), abs(denominator))
self.numerator = numerator // common_divisor
self.denominator = denominator // common_divisor
@staticmethod
def gcd(a, b):
"""求最大公约数"""
while b:
a, b = b, a % b
return a
# 四则运算
def __add__(self, other):
return Fraction(self.numerator * other.denominator + other.numerator * self.denominator,
self.denominator * other.denominator)
def __sub__(self, other):
return Fraction(self.numerator * other.denominator - other.numerator * self.denominator,
self.denominator * other.denominator)
def __mul__(self, other):
return Fraction(self.numerator * other.numerator,
self.denominator * other.denominator)
def __truediv__(self, other):
if other.numerator == 0:
raise ZeroDivisionError("分数除以0")
return Fraction(self.numerator * other.denominator,
self.denominator * other.numerator)
# 比较运算
def __eq__(self, other):
return self.numerator == other.numerator and self.denominator == other.denominator
def __ge__(self, other):
return self.numerator * other.denominator >= other.numerator * self.denominator
# 带分数输出
def to_string(self):
num, den = self.numerator, self.denominator
if num == 0:
return "0"
sign = "-" if num < 0 else ""
num = abs(num)
integer_part = num // den
remainder = num % den
if remainder == 0:
return f"{sign}{integer_part}"
elif integer_part == 0:
return f"{sign}{remainder}/{den}"
else:
return f"{sign}{integer_part}'{remainder}/{den}"
@classmethod
def from_string(cls, s):
"""解析字符串为 Fraction,支持带分数、真分数和整数"""
s = s.strip()
sign = -1 if s.startswith('-') else 1
if s.startswith(('+', '-')):
s = s[1:]
if "'" in s:
integer_part, frac_part = s.split("'")
numerator, denominator = frac_part.split("/")
total_num = int(integer_part) * int(denominator) + int(numerator)
return cls(sign * total_num, int(denominator))
elif "/" in s:
numerator, denominator = s.split("/")
return cls(sign * int(numerator), int(denominator))
else:
return cls(sign * int(s), 1)
def is_positive(self):
return self.numerator >= 0
5.2 核心函数:generate_expression(表达式生成)
def generate_expression(range_limit, op_count=0, max_ops=3):
"""
递归生成符合约束的四则运算表达式及其结果
:param range_limit: 数值范围(自然数、分数分母均<range_limit)
:param op_count: 当前已使用的运算符数量
:param max_ops: 最大运算符数量(默认3)
:return: (表达式字符串, 表达式结果Fraction对象)
"""
# 递归终止条件:达到最大运算符数或50%概率直接生成数字(终结符)
if op_count >= max_ops or random.random() < 0.5:
num = generate_number(range_limit)
return str(num.to_string()), num
# 递归生成:增加运算符计数,随机选择运算符
op_count += 1
op = random.choice(['+', '-', '×', '÷'])
# 递归生成左右两个子表达式(子表达式也需符合约束)
left_expr, left_val = generate_expression(range_limit, op_count, max_ops)
right_expr, right_val = generate_expression(range_limit, op_count, max_ops)
# 按运算符类型检查约束条件,不符合则重新生成
if op == '-':
# 减法约束:被减数≥减数,且结果为正数
if not (left_val >= right_val and (left_val - right_val).is_positive()):
return generate_expression(range_limit, op_count - 1, max_ops)
result_val = left_val - right_val
elif op == '÷':
# 除法约束:除数不为零,结果为真分数(分母在范围内)
if right_val.numerator == 0:
return generate_expression(range_limit, op_count - 1, max_ops)
result_val = left_val / right_val
if result_val.denominator >= range_limit:
return generate_expression(range_limit, op_count - 1, max_ops)
elif op == '+':
# 加法无特殊约束,直接计算
result_val = left_val + right_val
else: # × 乘法无特殊约束,直接计算
result_val = left_val * right_val
# 30%概率为表达式添加括号(增加题目多样性)
if random.random() < 0.3:
expr = f"({left_expr}) {op} ({right_expr})"
else:
expr = f"{left_expr} {op} {right_expr}"
return expr, result_val
5.3 核心函数:grade_exercises(题目批改)
def grade_exercises(exercise_file, answer_file):
"""
批改题目:比对题目文件与答案文件,统计对错
:param exercise_file: 题目文件路径
:param answer_file: 答案文件路径
:return: (正确题目编号列表, 错误题目编号列表)
"""
try:
# 读取题目文件,移除序号和等号,提取纯表达式
with open(exercise_file, 'r', encoding='utf-8') as f:
exercises = []
for line in f:
stripped = line.strip()
if stripped:
# 移除开头序号(如"1. ")和末尾等号(如" =")
expr = re.sub(r'^\d+\. ', '', stripped).replace(' =', '')
exercises.append(expr)
# 读取答案文件,移除序号,提取纯答案
with open(answer_file, 'r', encoding='utf-8') as f:
answers = []
for line in f:
stripped = line.strip()
if stripped:
ans = re.sub(r'^\d+\. ', '', stripped)
answers.append(ans)
# 校验题目与答案数量一致性
if len(exercises) != len(answers):
raise ValueError("题目数量与答案数量不匹配")
correct = []
wrong = []
# 逐题比对:计算题目结果与参考答案
for i, (exercise, answer) in enumerate(zip(exercises, answers), 1):
# 解析题目并计算结果
computed_answer = parse_expression(exercise)
# 解析参考答案
try:
expected_answer = Fraction.from_string(answer)
except:
# 参考答案格式错误,判定为错误
wrong.append(i)
continue
# 结果比对:都不为空且相等则正确
if computed_answer is not None and computed_answer == expected_answer:
correct.append(i)
else:
wrong.append(i)
return correct, wrong
except Exception as e:
print(f"批改时出错: {str(e)}")
return [], []
六、测试运行
6.1 测试用例设计(10个核心用例)
| 测试用例编号 | 测试场景 | 输入命令 | 预期结果 | 实际结果 | 测试结论 |
|---|---|---|---|---|---|
| 1 | 基础生成(10题,范围10) | python Myapp.py -n 10 -r 10 |
生成10道题,含自然数、真分数,无重复,答案正确 | 符合预期 | 通过 |
| 2 | 最大规模生成(10000题,范围20) | python Myapp.py -n 10000 -r 20 |
无报错,Exercises.txt和Answers.txt正常生成,无重复题目 | 符合预期 | 通过 |
| 3 | 范围边界测试(r=1,10题) | python Myapp.py -n 10 -r 1 |
仅生成自然数(分母≥2,r=1时无分数),题目有效 | 符合预期 | 通过 |
| 4 | 减法约束测试(r=5,20题) | python Myapp.py -n 20 -r 5 |
所有减法题目结果非负,如3 - 1'1/2 = 1'1/2 |
符合预期 | 通过 |
| 5 | 除法约束测试(r=6,15题) | python Myapp.py -n 15 -r 6 |
除法结果分母<6,如1/2 ÷ 3/4 = 2/3 |
符合预期 | 通过 |
| 6 | 带分数运算测试(r=10,5题) | python Myapp.py -n 5 -r 10 |
带分数运算正确,如2'1/3 + 1'1/2 = 3'5/6 |
符合预期 | 通过 |
| 7 | 重复题目测试(r=5,50题) | python Myapp.py -n 50 -r 5 |
无重复题目(如2+3与3+2不同时出现) |
符合预期 | 通过 |
| 8 | 基础批改测试(正确5题,错误5题) | python Myapp.py -e test_exer.txt -a test_ans.txt |
Grade.txt中Correct:5,Wrong:5,题号正确 | 符合预期 | 通过 |
| 9 | 答案格式错误批改 | 答案文件中含2.5(非规定格式) |
该题判定为错误 | 符合预期 | 通过 |
| 10 | 题目与答案数量不匹配 | 题目10题,答案8题 | 报错提示“数量不匹配”,批改终止 | 符合预期 | 通过 |
6.2 程序正确性验证依据
- 约束全覆盖:所有测试用例均覆盖核心约束(无负数、除法结果合法、运算符≤3个、无重复),未出现违反约束的题目。
- 结果可验证:随机抽取100道生成的题目,手动计算结果与Answers.txt比对,正确率100%。
- 边界场景无异常:针对r=1(无分数)、n=10000(大规模)、格式错误答案等边界场景,程序均能正确处理或给出明确报错。
七、项目小结
7.1 结对感受
本次结对项目是一次高效的协作体验。两人通过分工协作,既发挥了各自的优势,又弥补了单人开发的不足。在需求分析阶段,我们共同梳理了核心约束(如减法无负数、除法结果合法、题目去重),避免了后期开发的返工;在编码阶段,通过互相Code Review,及时发现了分数解析、递归生成等模块的逻辑漏洞;在测试阶段,分工设计不同场景的测试用例,确保了程序的全面性。结对开发不仅提高了开发效率和代码质量,还让我们学会了有效沟通、互相配合,体会到“1+1>2”的协作价值。
7.2 成败得失
成功之处
- 架构设计清晰:采用模块化设计,分数处理、表达式生成、批改功能分离,代码复用性高,便于维护和扩展。
- 核心约束精准实现:通过递归生成+实时约束检查,确保了减法无负数、除法结果合法等核心需求的满足。
- 性能优化有效:针对去重和递归生成的性能瓶颈,通过特征值提取、预判断剪枝等方式,使10000道题生成时间从原来的20秒优化至8秒。
不足之处
- 递归深度控制:极端情况下,表达式生成的递归深度可能过大,存在栈溢出风险(虽未实际发生,但需进一步优化)。
- 括号生成逻辑:括号添加仅基于随机概率,未考虑运算优先级的必要性(如
1+2×3无需括号,(1+2)×3需括号),可能生成冗余括号。 - 错误处理粒度:部分错误(如文件读取失败)的处理较为简单,未给出详细的错误定位信息。
7.3 彼此评价
- 对辜艺淇的评价:逻辑思维清晰,在分数运算和递归生成的核心逻辑设计上表现突出,能够快速定位并解决复杂问题。建议后续在代码注释和文档编写上更加详细,便于协作时的理解。
- 对王怡欧的评价:细心严谨,在测试用例设计和性能优化上贡献显著,尤其在去重逻辑的优化的思路新颖有效。建议后续在面对复杂需求时,可更主动地提出自己的想法,加强需求分析阶段的参与度。
7.4 改进计划
- 优化递归生成:将递归生成改为迭代生成,避免栈溢出风险,同时进一步提高生成效率。
- 智能括号生成:基于运算优先级判断是否需要添加括号,减少冗余括号,使题目更符合实际教学场景。
- 增强错误处理:细化错误类型(如文件不存在、格式错误、参数错误),给出更具体的报错信息和解决方案。
- 扩展功能:支持自定义运算符类型(如仅生成加法题)、难度分级(如低年级无分数、高年级含括号)等功能,提升程序的实用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号