JPA(Java Persistence API)
背景
JPA(Java Persistence API)是 Java EE 标准中的一部分,它通过提供一套对象关系模型(ORM)来帮助在开发应用过程中高效的管理关系型数据。和 JDBC 一样,JPA 本身只是一套标准接口,目前比较成熟的 JPA 实现有 Hibernate、EclipseLink 等。
聊聊 ORM
在进一步介绍 JPA 之前,先聊聊对象关系模型 ORM,既然前面说它是帮助我们更高效的管理关系型数据,那么在没有 ORM 的情况下,我们如果使用 JDBC 进行数据库操作的话是怎么样的呢?
package me.leozdgao.demo.jdbc;
import java.sql.*;
public class Application {
public final static String JDBC_URL = "jdbc:mysql://localhost:3306/learnjdbc";
public final static String JDBC_USER = "root";
public final static String JDBC_PASSWORD = "******";
public static void main(String[] args) {
try (Connection connection = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = connection.prepareStatement("SELECT id, grade, name, gender FROM students WHERE gender=? AND grade=?")) {
ps.setObject(1, "M");
ps.setObject(2, 3);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
Student student = new Student();
student.setId(rs.getLong("id"));
student.setGrade(rs.getLong("grade"));
student.setName(rs.getString("name"));
student.setGender(rs.getString("gender"));
// 后续处理逻辑...
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
我们可以看到,直接使用 JDBC 进行数据库操作的话:
- 需要手动控制 Connection、PreparedStatement、ResultSet 等实例的生命周期;
- 每次执行都必须手动拼写 SQL 并设置变量,较为繁琐,代码维护成本高;
- 每次执行结果都需要手动转换为业务层的类,以便适配后续的业务逻辑处理。
那么面对上述代码繁琐的问题,我们肯定可以通过编写一些 DbUtils 类来将繁琐的逻辑进行封装,或者针对某个特定的实体类,来针对性的编写访问数据库进行读写的方法。
更进一步 ORM 是解决上述问题的通用解决方案,对象关系模型通过声明式的手段声明实体类,定义了实体类中字段与数据库字段的映射关系,以及实体类之间的关系,并基于这些关系提供了遍历的管理实体进行读写的操作,可以在大部分场景下不再需要手动编写 SQL。
接下来就通过一个例子来进一步介绍 JPA,例子中 JPA 的实现使用的是 Hibernate。
JPA 模块组成
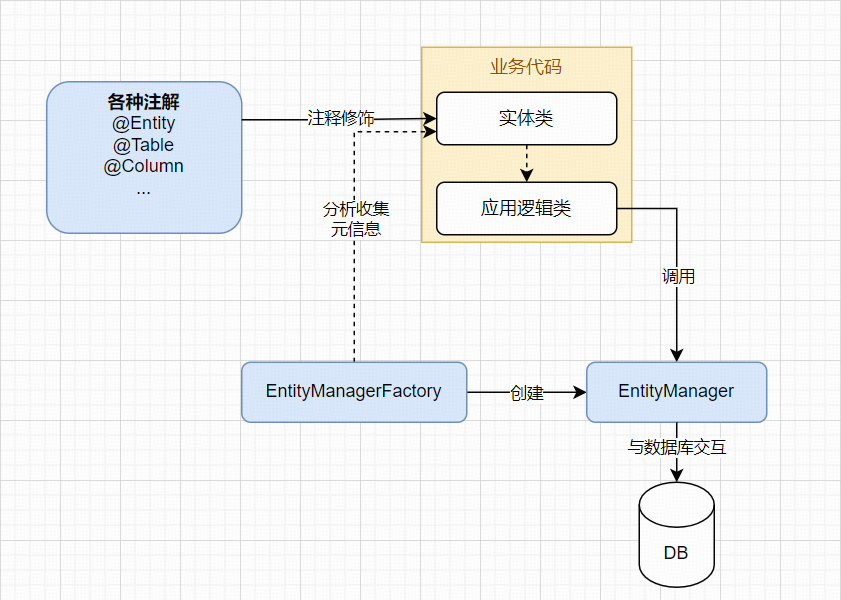
- EntityManager:对应了一个持久化上下文,通过这个上下文中的方法,就可以实现和数据库的交互,是使用 JPA 过程中最常用的 API。
- EntityManagerFactory:对应了一个 persistence-unit,用于创建 EntityManager,和 EntityManager
是一对多关系。 - 实体元数据配置:定义了实体类字段与数据库表结构字段的映射关系,支持通过 XML 或者 Java 注解的方式定义,后续的例子都采用注解的方式。
同时也可以看出 JPA 提供的 ORM 能力是基于 Data Mapper Pattern 的思想设计的,将实体的设计和具体的数据库行为解耦,由一个 EntityManager 实例来进行实体与数据库的链接。
有兴趣的可以了解一下两种 ORM Pattern 的区别:Active Record 和 Data Mapper 的区别
实体元信息定义
我们通过例子来介绍实体元信息的定义,比如我们定义实体类 Employee 代表雇员,那么首先我们定义 Employee 实体类,对实体类唯一的要求就是有一个支持无参构造函数的 Java Bean:
@Entity
@Table(name = "employees")
@Data
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "employeeNumber")
private Integer id;
private String lastName;
private String firstName;
private String email;
private String jobTitle;
}
我们看到这个实体类上的注解:
- @Entity,它标注这个是需要被扫描的实体类,这个实体类的元信息需要被收集。
- @Table 代表了实体类关联的数据表信息,通过 name 指定关联的表名,你还可以在 @Table 上通过 uniqueConstraints 定义表的唯一索引,在这里略过。
接下来就是对应数据库字段的注解,实际上这类注解既可以加在类的字段上,也可以加在 getter 方法上,但一个实体类中必须使用同一种方式,在上面的例子中选择加在字段上。
首先我们介绍一下 @Basic 注解,这个注解就代表了一个类字段和数据库字段具有映射关系,且数据库字段名即为类字段名。但我们发现例子中根本没有使用 @Basic 注解?因为如果这个类被施加了 @Entity 注解,那么所有字段默认都会加上 @Basic 注解,即默认情况下所有类字段都会映射为一个数据表字段。如果希望某个类字段不要建立和数据库字段的映射,则可以加上 @Transient 注解。
主键与主键生成策略
然后是用于标记主键的 @Id 注解,代表这个字段对应数据库表的主键,通常 @GeneratedValue 注解会配合使用,代表主键值生成的方式,通过 strategy 指定使用的生成策略,支持如下几种选项:
- AUTO:(默认)根据实际连接的数据库类型,选择是 IDENTITY、SEQUENCE 或者 TABLE。
- IDENTITY:使用数据库的 ID 自增的方式生成主键,Oracle 不支持。
- SEQUENCE:使用数据库的序列生成功能生成主键,MySQL 不支持。
- TABLE:使用其他数据库表的值作为当前表的主键值,一定程度影响扩展性和性能。
由于我们使用的数据库是 MySQL,我们指定的主键生成策略为 GenerationType.IDENTITY。当然 JPA 不同的实现会提供一些针对主键生成的扩展,比如 Hibernate 有 uuid 的主键生成策略,每次生成的主键都是一个唯一的 UUID,并且也支持通过实现 IdentifierGenerator 接口去实现自己的主键生成器。
总结
JPA 及其实现框架(Hibernate等)还有其它许多特性与功能,这里不再一一阐述,有兴趣的同学可以去了解一下,对 JPA 全貌有一个初步认识。其实最想说的是 ORM 框架其实都是基于 Java 标准库提供的基础能力之上扩展而来,所以理解这些标准库是非常重要的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号