爬取和分析NBA球员排名及各项数据
一、选题的背景
NBA受到世界各地极大多数人的喜爱,不分年龄,学生、员工、劳动工人等社会各界都有热爱篮球的人,也有各自喜欢信仰的球星,在NBA中国官方网站里他们更好的了解和清楚自己喜爱的球星和其它联盟里的球星的一些数据对比,知道他们近期的一些起伏和爆发,本次爬虫建立在这基础上,通过对网页数据的提取并进行可视化对比,更好地了解联盟里球员的排名和其余各项数据之间的关系来分析对球队的贡献好与坏。
二、设计方案
1.爬虫名称:爬取NBA球员排名及各项数据
2.爬取内容:爬取NBA球员排名、场均得分、各项命中率等
3.方案概述:访问网页得到状态码200,分析网页源代码,找出所需要的的标签,逐个提取标签保存到相同路径csv文件中,读取该文件,进行数据清洗,数据模型分析,数据可视化处理,绘制排名与其余几项数据的关系图。
技术难点:
1.在爬取网页数据,提取数据成csv文件时,由于数据较为杂乱。
2. 做数据分析,即求回归系数,因为标题是文字,无法与数字作比较,需要把标题这一列删除才可。由于不明原因,输出结果经常会显示超出列表范围。
三、主题页面的结构特征分析
首先,本次爬虫爬取NBA中国官方网站(https://china.nba.com/statistics/)球员排名及各项数据
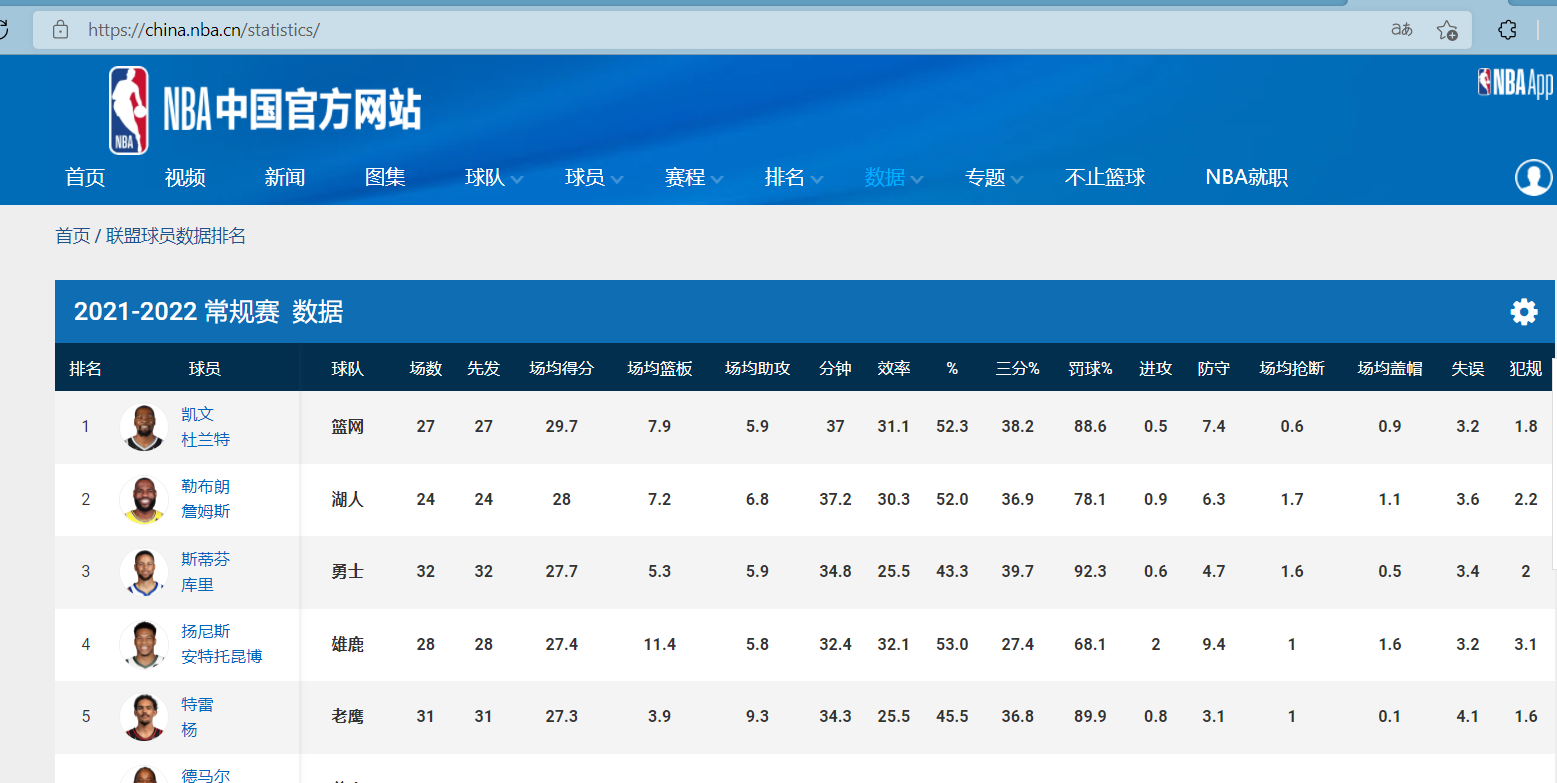
1.页面信息
在页面中找到Network(网络)之后,再找到XHR之后,刷新页面,获取到该网页的一些数据。找到保存数据的json文件

2.对json文件进行数据提取
在上一步查询的结果数据中筛选json文件找到正确的json文件之后,查询预览的结果,可以看到与需要爬取的信息相符,就是我们需要的库。

确定json文件信息是正确且需要的之后,再查询标头,找到user—URL。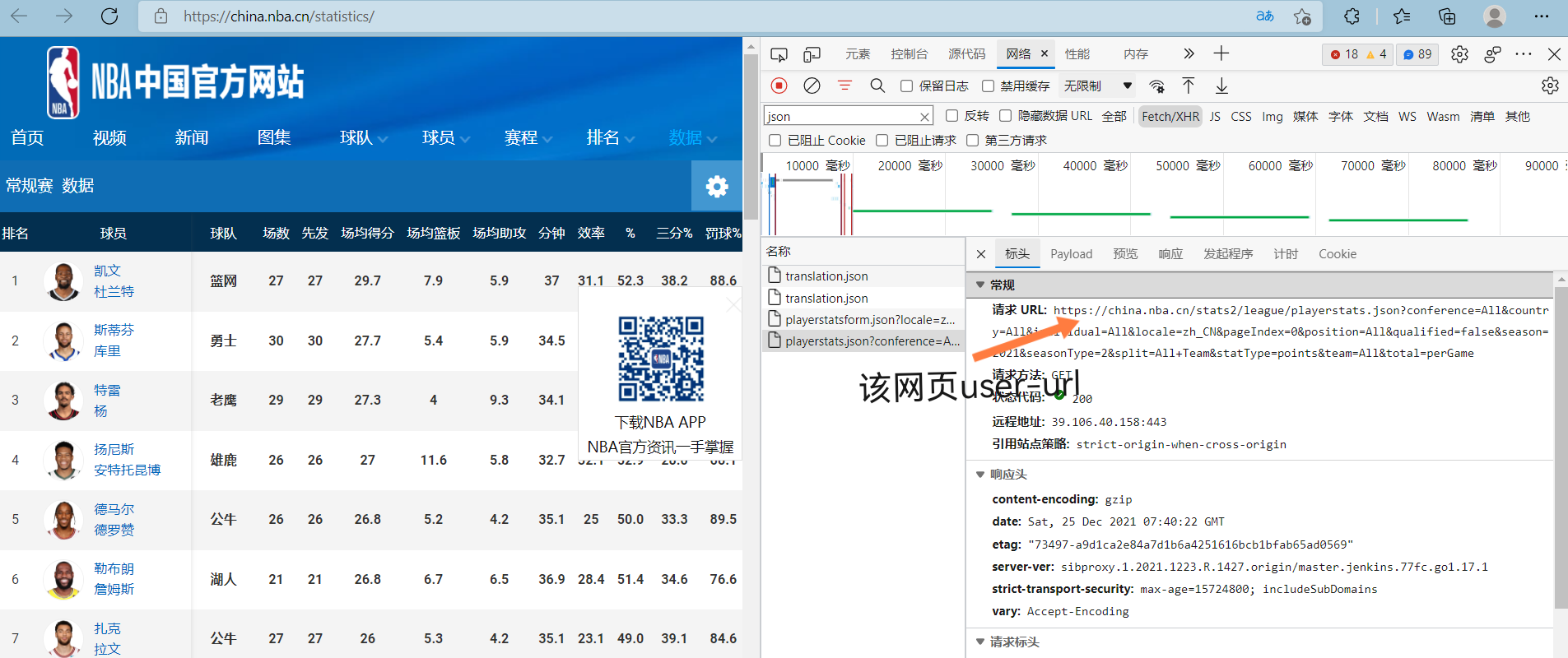
之后开始我们对NBA中国官方网站球员数据的抓包。
四、网络爬虫程序设计
1.数据爬取与采集
#爬取网页数据
#提取数据 import requests from bs4 import BeautifulSoup import json import numpy as np # url='https://china.nba.cn/stats2/league/playerstats.json?conference=All&country=All&individual=All&locale=zh_CN&pageIndex=0&position=All&qualified=false&season=2021&seasonType=2&split=All+Team&statType=points&team=All&total=perGame' # def getHTMLText(url,timeout=30): try: r=requests.get(url,timeout=30) # r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return'产生异常' #html.parser表示用BeautifulSoup库解析网页 html=getHTMLText(url) soup=BeautifulSoup(html,'html.parser') print(soup.prettify())
结果如下:

#采集数据
#创建空表 pointsPg_list=[] assistsPg_list=[] rebsPg_list=[] name_list=[] data1=[] tppct=[] ftpct=[] fgpct=[] stealsPg_list=[] blocksPg_list=[] offRebsPg_list=[] defRebsPg_list=[] rank=[] html=getHTMLText(url) data=json.loads(html) a=data['payload']['players'] data1.append(name_list) data1.append(assistsPg_list) b=1 for i in a: rank.append(b) name_list.append(i['playerProfile']['displayName']) pointsPg_list.append(i['statAverage'][ 'pointsPg']) rebsPg_list.append(i['statAverage'][ 'rebsPg']) assistsPg_list.append(i['statAverage'][ 'assistsPg']) stealsPg_list.append(i['statAverage'][ 'stealsPg']) blocksPg_list.append(i['statAverage'][ 'blocksPg']) offRebsPg_list.append(i['statAverage'][ 'offRebsPg']) defRebsPg_list.append(i['statAverage'][ 'defRebsPg']) tppct.append(i['statAverage']['tppct']) ftpct.append(i['statAverage']['ftpct']) fgpct.append(i['statAverage']['fgpct']) b=b+1 list_1=['排名'] #导出球员的各项数据 import pandas as pd df=pd.DataFrame(columns=list_1) df['排名']=rank df['NAME']=name_list df['场均得分']=pointsPg_list df['场均篮板']=rebsPg_list df['场均助攻']=assistsPg_list df['投篮命中率']=fgpct df['三分命中率']=tppct df['罚球命中率']=ftpct df['进攻效率']=offRebsPg_list df['防守效率']=defRebsPg_list df['场均抢断']=stealsPg_list df['场均盖帽']=blocksPg_list df=df.drop_duplicates() df
结果如下:
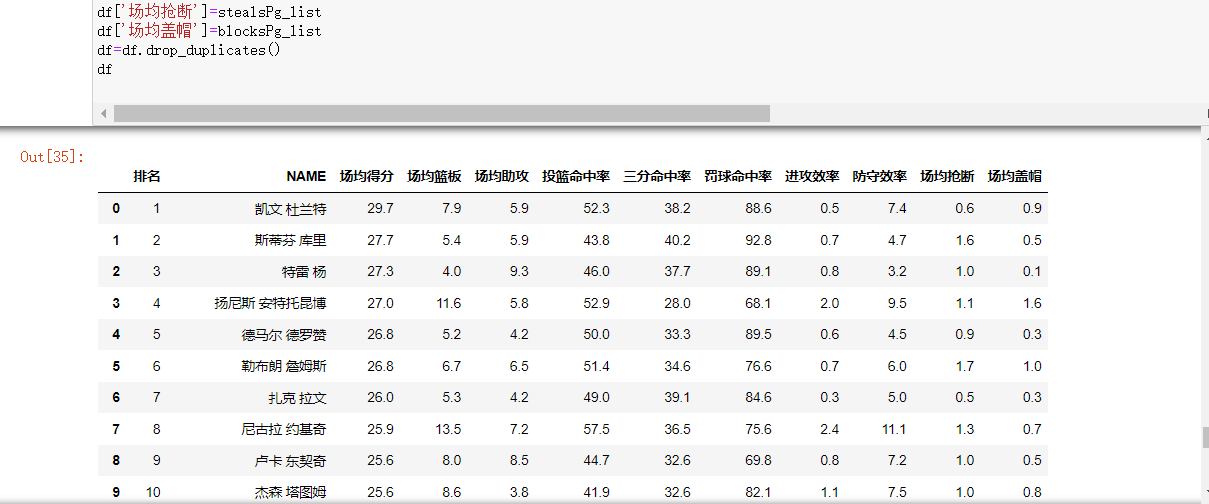
#保存数据
#将dataframe写入csv df.to_csv('D:/Python/NBA数据.csv',index=False) df.to_csv('D:/Python/NBA.csv',index=False)
2.对数据进行清洗和处理
#检查重复值
#检查并显示重复值 print(df.duplicated())

#删除重复值
#删除重复值 df = df.drop_duplicates() df.head(
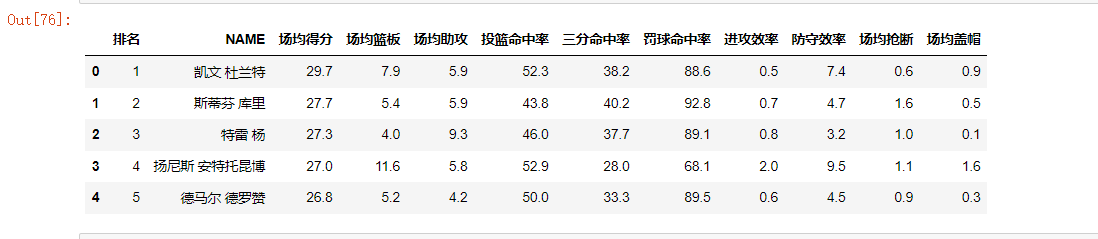
#检查是否有空值
#检查是否有空值 print(df['NAME'].isnull().value_counts())

#异常值处理
#异常值处理 df.describe()
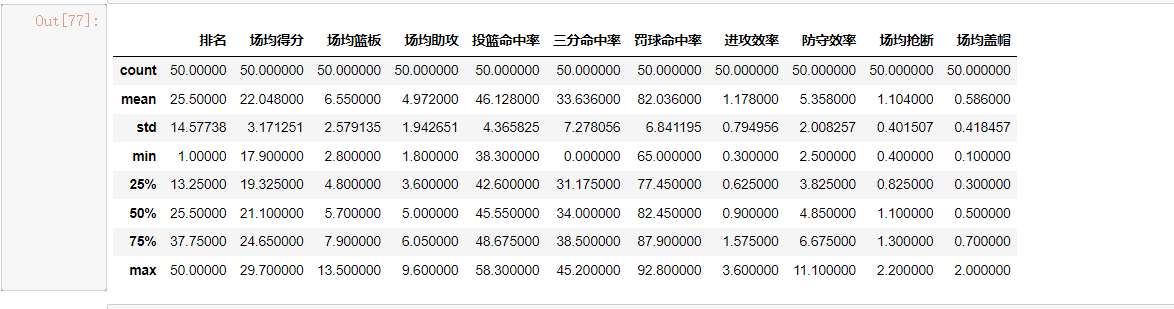
#查看统计信息
#查看统计信息 print(df.describe()

3、数据分析与可视化(例如:数据柱形图、折线图图、散点图、回归图、分布图)
#数据可视化
#绘制柱状图
#绘制柱状图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(df.排名, df.投篮命中率, color='b') plt.xlabel("排名") plt.ylabel("投篮命中率") plt.title('排名与投篮命中率柱状图') plt.show()
结果:

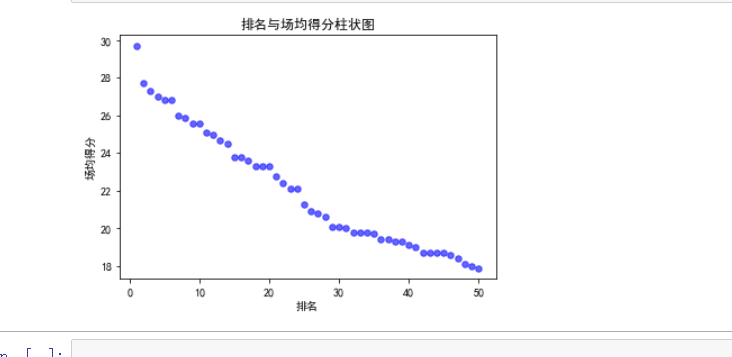
#绘制散点图
#绘制散点图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 size=30 plt.scatter(df.排名, df.场均得分,size, color='b',alpha=0.6,marker='o') plt.xlabel("排名") plt.ylabel("场均得分") plt.title('排名与场均得分柱状图') plt.show()
结果:
#绘制堆叠图
#绘制罚球命中率与排名图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.stackplot(df.排名, df.罚球命中率, color=['b',]) plt.xlabel("排名") plt.ylabel("罚球命中率") plt.title('排名与罚球命中率堆叠图') plt.show()
结果:

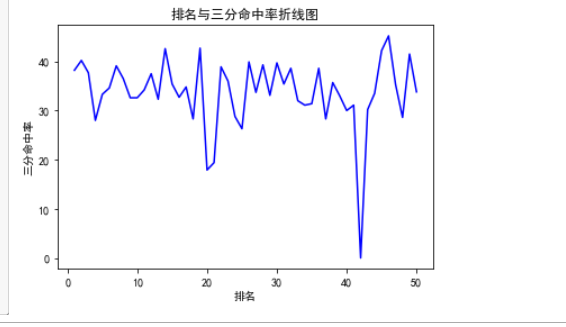
#绘制折线图
#绘制折线图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.plot(df.排名, df.三分命中率, color='b') plt.xlabel("排名") plt.ylabel("三分命中率") plt.title('排名与三分命中率折线图') plt.show()
结果:
4.数据处理分析
#求回归系数
#求取回归系数 from sklearn.linear_model import LinearRegression X=df.drop('NAME',axis=1) predict_model=LinearRegression() predict_model.fit(X,df['排名']) print('回归系数为:',predict_model.coef_)
结果求得:

#绘制回归图
#绘制回归图 import seaborn as sns import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签 X=df.drop('NAME',axis=1) sns.regplot(df['排名'],df['进攻效率']) sns.regplot(df['排名'],df['防守效率']) plt.title('排名与进攻、防守效率图')
结果:
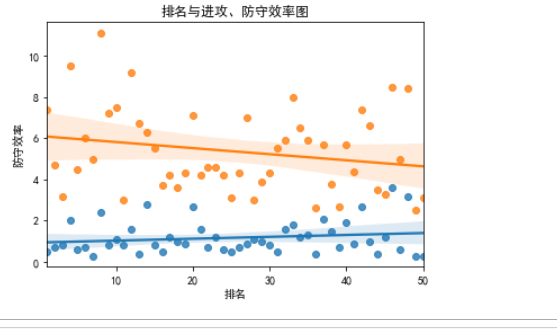
通过以上的分析,我们可以发现在排名与一些其他数据的比较之中,呈现出起伏的变化,可以得知一些场均得分排在前面的球员,在各项命中率,防守、进攻效率以及场均能得到的抢断和防守并没有比排在他们之后的一些球员高。从现实上的比赛来看,出手数对得分起到了一定的影响,导致场均得分较低。
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)。
#选择场均得分以及进攻效率,防守效率和场均抢断四个特征变量,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线
#绘制拟合曲线
1.进攻效率与场均得分
#绘制拟合曲线 import matplotlib.pyplot as plt import matplotlib import numpy as np import scipy.optimize as opt import csv x0=df['进攻效率'] y0=df['场均得分'] def func(x,c): k,a=c return k*x+a def errfc(c,x,y): return y-func(x,c) c0=(100,20) #调用拟合曲线 print(opt.leastsq(errfc,c0,args=(x0,y0))) #s设置画布 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') plt.plot(x0,y0,"o",label=u"进攻效率") plt.plot(x0,func(x0,opt.leastsq(errfc,c0,args=(x0,y0))[0]),label=u"场均得分") plt.title('进攻效率与场均得分拟合曲线图') plt.legend(loc=3,prop=chinese) plt.show()
结果:
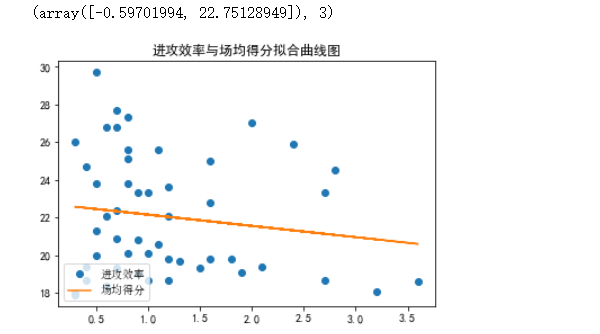
2.防守效率与场均抢断
#绘制拟合曲线 import matplotlib.pyplot as plt import matplotlib import numpy as np import scipy.optimize as opt import csv x0=df['防守效率'] y0=df['场均抢断'] # def func(x,c): k,a=c return k*x+a def errfc(c,x,y): return y-func(x,c) c0=(100,20) #调用拟合曲线 print(opt.leastsq(errfc,c0,args=(x0,y0))) #s设置画布 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') plt.plot(x0,y0,"o",label=u"防守效率") plt.plot(x0,func(x0,opt.leastsq(errfc,c0,args=(x0,y0))[0]),label=u"场均抢断") plt.title('防守效率与场均抢断拟合曲线图') plt.legend(loc=3,prop=chinese) plt.show()
结果:

6、数据持久化
#数据持久化 df = pd.DataFrame(df,columns=['排名','NAME','场均得分','场均篮板','场均助攻','投篮命中率','罚球命中率','三分命中率','进攻效率','防守效率','场均抢断','场均盖帽']) df.to_csv('NBA.csv',encoding = 'gbk') #保存文件,数据持久化
7、将以上各部分的代码汇总,附上完整程序代码
1 #提取数据 2 import requests 3 from bs4 import BeautifulSoup 4 import json 5 # 6 url='https://china.nba.cn/stats2/league/playerstats.json?conference=All&country=All&individual=All&locale=zh_CN&pageIndex=0&position=All&qualified=false&season=2021&seasonType=2&split=All+Team&statType=points&team=All&total=perGame' 7 # 8 def getHTMLText(url,timeout=30): 9 try: 10 r=requests.get(url,timeout=30) # 11 r.raise_for_status() 12 r.encoding=r.apparent_encoding 13 return r.text 14 except: 15 return'产生异常' 16 17 #html.parser表示用BeautifulSoup库解析网页 18 html=getHTMLText(url) 19 soup=BeautifulSoup(html,'html.parser') 20 print(soup.prettify()) 21 22 #创建空表 23 pointsPg_list=[] 24 assistsPg_list=[] 25 rebsPg_list=[] 26 name_list=[] 27 data1=[] 28 tppct=[] 29 ftpct=[] 30 fgpct=[] 31 stealsPg_list=[] 32 blocksPg_list=[] 33 offRebsPg_list=[] 34 defRebsPg_list=[] 35 rank=[] 36 html=getHTMLText(url) 37 data=json.loads(html) 38 a=data['payload']['players'] 39 data1.append(name_list) 40 data1.append(assistsPg_list) 41 b=1 42 for i in a: 43 rank.append(b) 44 name_list.append(i['playerProfile']['displayName']) 45 pointsPg_list.append(i['statAverage'][ 'pointsPg']) 46 rebsPg_list.append(i['statAverage'][ 'rebsPg']) 47 assistsPg_list.append(i['statAverage'][ 'assistsPg']) 48 stealsPg_list.append(i['statAverage'][ 'stealsPg']) 49 blocksPg_list.append(i['statAverage'][ 'blocksPg']) 50 offRebsPg_list.append(i['statAverage'][ 'offRebsPg']) 51 defRebsPg_list.append(i['statAverage'][ 'defRebsPg']) 52 tppct.append(i['statAverage']['tppct']) 53 ftpct.append(i['statAverage']['ftpct']) 54 fgpct.append(i['statAverage']['fgpct']) 55 b=b+1 56 list_1=['排名'] 57 58 #导出球员的各项数据 59 import pandas as pd 60 df=pd.DataFrame(columns=list_1) 61 df['排名']=rank 62 df['NAME']=name_list 63 df['场均得分']=pointsPg_list 64 df['场均篮板']=rebsPg_list 65 df['场均助攻']=assistsPg_list 66 df['投篮命中率']=fgpct 67 df['三分命中率']=tppct 68 df['罚球命中率']=ftpct 69 df['进攻效率']=offRebsPg_list 70 df['防守效率']=defRebsPg_list 71 df['场均抢断']=stealsPg_list 72 df['场均盖帽']=blocksPg_list 73 df 74 75 #将dataframe写入csv 76 df.to_csv('D:/Python/NBA数据.csv',index=False) 77 df.to_csv('D:/Python/NBA.csv',index=False) 78 79 #检查并显示重复值 80 print(df.duplicated()) 81 82 #删除重复值 83 df = df.drop_duplicates() 84 df.head() 85 86 #异常值处理 87 df.describe() 88 89 #检查是否有空值 90 print(df['排名'].isnull().value_counts()) 91 92 #查看统计信息 93 print(df.describe()) 94 df 95 96 #求取回归系数 97 from sklearn.linear_model import LinearRegression 98 X=df.drop('NAME',axis=1) 99 predict_model=LinearRegression() 100 predict_model.fit(X,df['排名']) 101 print('回归系数为:',predict_model.coef_) 102 103 #绘制回归图 104 import seaborn as sns 105 import matplotlib.pyplot as plt 106 plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签 107 X=df.drop('NAME',axis=1) 108 sns.regplot(df['排名'],df['进攻效率']) 109 sns.regplot(df['排名'],df['防守效率']) 110 plt.title('排名与进攻、防守效率图') 111 112 #绘制柱状图 113 import pandas as pd 114 import numpy as np 115 import matplotlib.pyplot as plt 116 plt.rcParams['font.sans-serif']=['SimHei'] 117 plt.bar(df.排名, df.投篮命中率, color='b') 118 plt.xlabel("排名") 119 plt.ylabel("投篮命中率") 120 plt.title('排名与投篮命中率柱状图') 121 plt.show() 122 123 #绘制散点图 124 import pandas as pd 125 import numpy as np 126 import matplotlib.pyplot as plt 127 plt.rcParams['font.sans-serif']=['SimHei'] 128 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 129 size=30 130 plt.scatter(df.排名, df.场均得分,size, color='b',alpha=0.6,marker='o') 131 plt.xlabel("排名") 132 plt.ylabel("场均得分") 133 plt.title('排名与场均得分柱状图') 134 plt.show() 135 136 #罚球命中率与排名 137 import pandas as pd 138 import numpy as np 139 import matplotlib.pyplot as plt 140 plt.rcParams['font.sans-serif']=['SimHei'] 141 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 142 plt.stackplot(df.排名, df.罚球命中率, color=['b',]) 143 plt.xlabel("排名") 144 plt.ylabel("罚球命中率") 145 plt.title('排名与罚球命中率堆叠图') 146 plt.show() 147 148 #绘制折线图 149 import pandas as pd 150 import numpy as np 151 import matplotlib.pyplot as plt 152 plt.rcParams['font.sans-serif']=['SimHei'] 153 plt.rcParams['axes.unicode_minus'] = False 154 plt.plot(df.排名, df.三分命中率, color='b') 155 plt.xlabel("排名") 156 plt.ylabel("三分命中率") 157 plt.title('排名与三分命中率折线图') 158 plt.show() 159 160 #绘制拟合曲线 161 import matplotlib.pyplot as plt 162 import matplotlib 163 import numpy as np 164 import scipy.optimize as opt 165 import csv 166 x0=df['进攻效率'] 167 y0=df['场均得分'] 168 def func(x,c): 169 k,a=c 170 return k*x+a 171 def errfc(c,x,y): 172 return y-func(x,c) 173 c0=(100,20) 174 #调用拟合曲线 175 print(opt.leastsq(errfc,c0,args=(x0,y0))) 176 #s设置画布 177 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 178 179 plt.plot(x0,y0,"o",label=u"进攻效率") 180 181 plt.plot(x0,func(x0,opt.leastsq(errfc,c0,args=(x0,y0))[0]),label=u"场均得分") 182 plt.title('进攻效率与场均得分拟合曲线图') 183 plt.legend(loc=3,prop=chinese) 184 185 plt.show() 186 187 #绘制拟合曲线 188 import matplotlib.pyplot as plt 189 import matplotlib 190 import numpy as np 191 import scipy.optimize as opt 192 import csv 193 x0=df['防守效率'] 194 y0=df['场均抢断'] 195 # 196 def func(x,c): 197 k,a=c 198 return k*x+a 199 def errfc(c,x,y): 200 return y-func(x,c) 201 c0=(100,20) 202 #调用拟合曲线 203 print(opt.leastsq(errfc,c0,args=(x0,y0))) 204 #s设置画布 205 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 206 207 plt.plot(x0,y0,"o",label=u"防守效率") 208 209 plt.plot(x0,func(x0,opt.leastsq(errfc,c0,args=(x0,y0))[0]),label=u"场均抢断") 210 plt.title('防守效率与场均抢断拟合曲线图') 211 plt.legend(loc=3,prop=chinese) 212 213 plt.show() 214 215 #数据持久化 216 df = pd.DataFrame(df,columns=['排名','NAME','场均得分','场均篮板','场均助攻','投篮命中率','罚球命中率','三分命中率','进攻效率','防守效率','场均抢断','场均盖帽']) 217 df.to_csv('NBA.csv',encoding = 'gbk') #保存文件,数据持久化
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
通过一系列的数据分析及可视化可以发现,在爬取的这些球员之中,根据场均得分来进行的排名,事实上并不是能那么可靠地分析一个球员的好与坏,在场上不仅仅只有得分,还有其余的各项数据,投篮的命中率以及防守、进攻效率和对球队的1帮助很大程度上并不是根据场均得分来体现,得分高命中率低,可能会导致球队落后和失分。经过一系列数据对比我们可以的到此结论,达到了预期的目标。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
在完成设计的过程中,由于选题以及对爬取知识的欠缺耗费了大量的时间,期间浏览、了解、和学习了许多老师推荐的优秀作品,以及CSDN,博客园里的许多博主发布的很好的作品,让我得到也学到了很多的新的知识,学到了很多不同的完善和解决同一个问题的方法,但是还没有完全掌握并使用使之成为自己的东西,还需要在课后进行更仔细的研究。在完成设计的过程中,需要感谢一些掌握知识比较透彻的同学对我出现的问题的指正。在绘制分析图时课本里的例题分析讲解的也比较透彻,当然这些知识在课上也都很清楚地进行过讲解,在课后作业中也进行了多次练习。在设计中,存在很多的不足之处,但是,通过这次设计能让我更好地警醒自己的Python水平和理解的有限。同样,这些不足会给我更大的动力去探索Python。总而言之,这次的设计很大程度,很大意义上对我起到了巨大的帮助和督促。课下的空余时间依然要不断努力学习新的知识完善自己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号